誰でもわかるStable Diffusion kohya_ssの追加パラメータを解説
以前の記事でkohya_ssの各パラメータについて解説しました。
別に万人向けの有益な情報として書いたつもりはなかったんですが、最近になってこの記事へのアクセスが多くなってきたため、需要はあるのかなあと思う一方、進歩の著しいkohya_ssの最新バージョンから見ると数カ月前に書かれたこの記事は情報が古い部分もあります。
そこで今回は、kohya_ssの前回から変わった部分を補足解説していこうと思います。
今回解説するkohya_ssのバージョンはv21.8.8です。
- kohya_ssの基本画面
- LoRAタブ内の構造
- Trainingタブ内の構造
- Source modelタブの変更点
- Foldersタブの変更点
- Parametersタブの変更点
- Max train steps
- Optimizer
- LR scheduler extra arguments
- Minimum bucket resolution
- Maximum bucket resolution
- Weight norms、Dropoutオプションについての前知識
- Scale weight norms
- Network dropout
- Rank dropout
- Module dropout
- VAE
- Save last N steps state
- Full bf 16 training
- CrossAttention
- V Pred like loss
- Min Timestep
- Max Timestep
- Scale v prediction loss
- まとめ
kohya_ssの基本画面
下の画面はkohya_ssを立ち上げたときに表示される基本画面です。kohya_ssのそれぞれの機能はタブによってまとめられていることが分かります。
バージョンは右下に常に表示されます。
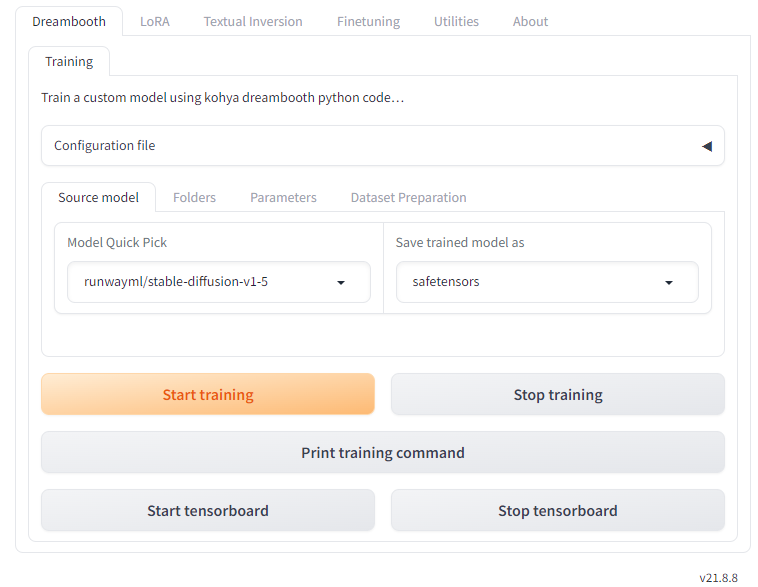
一番上のタブグループを見てみましょう。
追加学習タブ
kohya_ssは「Dreambooth」、「LoRA」、「Textual Inversion」、「Finetuning」という4種類の方法で追加学習を行えます。これら4種類の追加学習設定がそれぞれ独立してタブにまとめられています。
現在ではLoRA学習が主流なので、ほとんどの人は左から2番目の「LoRA」タブを選ぶことになると思います。そのため、この記事ではLoRAタブのみを解説します。
Utilitiesタブ
「Utilities」では「学習用の画像を準備する」ためのツールと「学習済みモデルを加工、変換、出力する」ためのツールが用意されています。
kohya_ssを追加学習ツールとして使うのであれば、「画像をサイズごとにまとめる」、「学習画像にキャプションをつける」などの学習画像準備ツールがよく利用されると思います。
本記事ではユーティリティについては解説しません。
Aboutタブ
これはヘルプページです。バージョン情報もトップに表示されます。
ここではインストールやアップデート、立ち上げに関するヘルプが詳細に書かれています。ただ、このヘルプ画面を見ているということはもうkohya_ssのインストールができているはずなので、読み進める必要はないかもしれません。
その他、各追加学習についての解説動画や外部リンクが軽く紹介されています。
LoRAタブ内の構造
本記事では「LoRA」タブの中身のみ解説します。
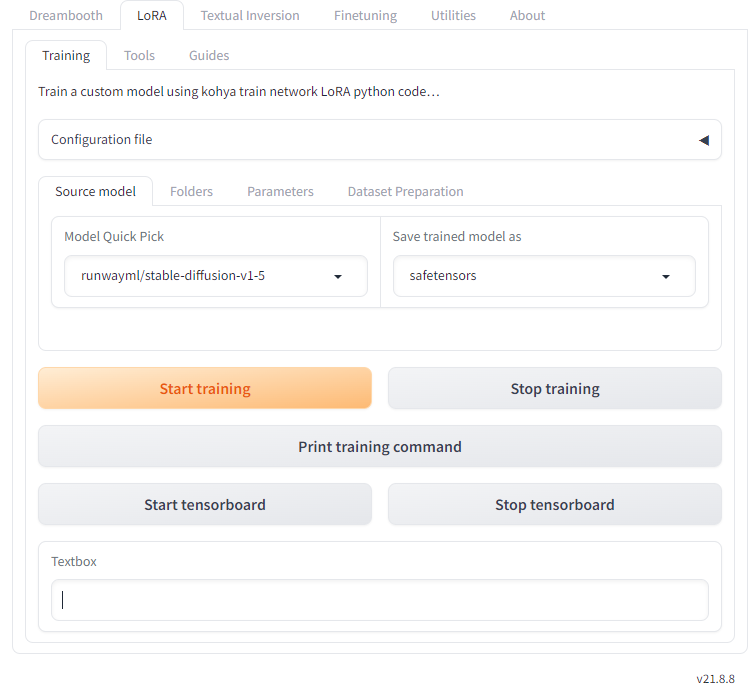
「LoRA」タブ内にはさらに「Training」「Tools」「Guides」という3つのタブがあります。
Trainingタブ
「Training」タブは追加学習設定の本体です。ここで主要なパラメータをすべて設定し、学習を行います。ここにあるパラメータの大部分は以前の記事で解説しましたが、新たに追加されたパラメータについては後述します。
Toolsタブ
ここではLoRAファイルやLyCORISファイルを抽出したり合体させたりできます。LoRA学習を行った後に使うツールがほとんどなので、学習前には必要ないでしょう。
ただ、「Dataset Preparation」というタブでは、学習準備のための2つのツールが用意されています。
- 「Folder preparation」:学習画像の特殊なフォルダ構造を自動で作成、ネーミング、整理してくれる機能です。この機能は画像自体には変更を加えません。
- 「Dataset balancing」:それぞれのコンセプトの画像がほぼ同じステップ数学習されるように、学習ステップ数を自動計算します。例えば「コンセプト1」フォルダが20枚の画像を持ち、「コンセプト2」フォルダが40枚の画像を持つ場合、「コンセプト1」フォルダの繰り返し学習数を「コンセプト2」フォルダの2倍にします。
Guidesタブ
LoRA学習の実行や開発のためのガイドがここに追加されていくそうです。現在は学習のためのガイドが少しだけ触れられています。
Trainingタブ内の構造
いよいよLoRA学習の本体、「Training」タブを見ていきます。ここにはさらに4つのタブがあります。これは以前の記事のときとだいたい同じ構造です。

なお、「Dataset Preparation」タブの中身は、一つ上の「Tools」タブ内にある「Dataset Preparation」タブの中身と全く同じです。
Source modelタブの変更点
Source modelタブでは、「SDXL Model」オプションが追加されています。これはバージョン2に続く最新バージョンで、Stable Diffusionの構造も大きく変わっています。SDXLモデルを使うときは必ずオンにしておきましょう。
Foldersタブの変更点
Foldersタブ内のパラメータは以前から変わっていません。
Parametersタブの変更点
Parametersタブ内のパラメータは、さらに「Basic」「Advanced」「Samples」の3つのタブに整理されました。一部場所を移動したパラメータもありますが、機能は同じです。
ここでは追加されたパラメータのみを解説します。
Max train steps
「Max train epoch」オプションと似たような働きをします。
通常ステップ数は画像数x繰り返し数xエポック数で決まりますが、上限ステップ数をここで指定することもできます。ここで指定したステップ数に達すると、学習が強制的に終了します。
デフォルトは空欄です。ステップ数を抑える必要がない場合は空欄のままで構いません。
Optimizer
オプティマイザーは「学習中にニューラルネットのウェイトをどうアップデートするか」の設定です。以前の記事に比べてオプティマイザーの数が増えていますが、基本的に「AdamW」または「AdamW8bit」を使っておけば問題ありません。

以下は追加されたオプティマイザーです。
- DAdaptadanIP
- DAdaptAdamPreprint
- DAdaptLion
- PagedAdamW8bit
- PagedLion8bit
- Prodigy
このうち、「Paged」オプティマイザーは学習時に発生する突発的なメモリ不足エラーを防止する機能を備えたオプティマイザー、またProdigyは最近提唱された「DAdapt」バリエーションの改良版で、「DAdapt」より素早く正確に学習が収束すると報告されています。
LR scheduler extra arguments
スケジューラーのための追加設定をここでコマンド表記できます。空欄で構いません。
Minimum bucket resolution
Maximum bucket resolution
これら2つのオプションは、「Enable buckets」にチェックが入っている場合のみ有効のオプションです。
「bucket」とは学習画像をサイズごとに振り分けて入れておく「バケツ」です。LoRAは様々な解像度の画像を混ぜて学習することができますが、この2つのオプションで最小画像サイズと最大画像サイズを指定することができます。どちらも64ピクセル未満の数字を指定することはできません。
Weight norms、Dropoutオプションについての前知識
LoRAとは、オリジナルのモデルの大きなニューラルネットに追加する小さなニューラルネットです(詳細は過去の記事をご覧ください)。この小さなニューラルネットがオリジナルのモデル(正確にはU-Netという構造をしています)の中のあちこちに何十個も追加されます。この「小さなニューラルネット」ひとつを便宜的に「モジュール」と呼びます。
LoRAモジュールは「ダウンウェイト」「ランク」「アップウェイト」からなっています。「ランク」とは真ん中の層のニューロンの数です。
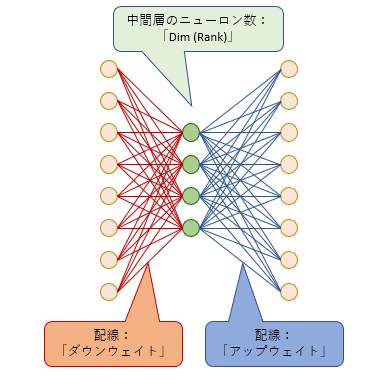
これらを踏まえて、次の3つのオプションを見てみましょう。
「Dropout」とは、学習ステップごとに毎回一定の確率でこのモジュール内の一部、あるいは全部をスイッチオフするオプションです。スイッチオフされた部分は何もせず、学習もしません。
これは「過学習」を防ぐためのトリックです。「過学習」とは、与えられた学習画像を過度に覚えすぎて融通が利かなくなり、学習画像に似た画像しか作れなくなる状態です。これを防ぐために、時にはある程度学習を「サボる」ことも有効です。
Scale weight norms
LoRA学習によって、上のモジュール内の「ダウンウェイト」と「アップウェイト」の線の太さが変わっていきますが、これをどこまで太くしていいのか、上限を設けることができます。
全体の線の太さは「ノルム」という数値で表すことができます。このノルムを一定範囲に抑えることで、特定の線が太くなりすぎて過学習になったり、学習部位が極端に偏ったりするのを防ぐことができます。また、LoRAを複数併用する時も安定して働くことが期待されます。
0~10の値でどれほど強い上限を設けるかを決められます。数字が小さければ小さいほど強い上限が設けられます。
デフォルトは0で、0の場合はこの機能は無効です。推奨設定は1とされています。
なお、このオプションは後述のDropoutと併用するとさらに効果を発揮するようです。
Network dropout
このオプションでは、モジュール内のダウンウェイトを一定の確率でドロップアウトする(つまり配線を切る)オプションです。0~1の値で、値が大きいほどドロップアウトの確率が増えます。
デフォルトは0です。推奨範囲は0.1~0.5とされています。
Rank dropout
このオプションでは、モジュールの真ん中のニューロンを一定の確率でドロップアウトするオプションです。0~1の値で、値が大きいほどドロップアウトの確率が増えます。
デフォルトは0です。推奨範囲は0.1~0.3とされています。
Module dropout
モジュール丸ごとを一定の確率で無効にするオプションです。つまり(その部分では)LoRAがまったく効いていない状態になります。もちろん一部のモジュールが無効になったところで、U-Net内には何十個もモジュールが追加されているので、LoRA学習が無駄になるということはありません。0~1の値で、値が大きいほどドロップアウトの確率が増えます。
デフォルトは0です。推奨範囲は0.1~0.3とされています。
VAE
学習に使用するVAEをここで指定することができます。ここが空欄の場合、VAEはモデルデータ(Sourcd modelタブで指定したもの)に同梱しているものを使用します。
デフォルトは空欄です。
Save last N steps state
このオプションは「Save training state」がオン、かつ「Save every N steps」が0でない時に有効になります。
学習時は途中の状態をセーブしておくことができます。この状態ファイルをロードすると、学習途中の状態から続きを再開することができます。
セーブするタイミングは「Save every N steps」で指定します。例えば「Save every N steps」が200の場合、200ステップ目、400ステップ目、600ステップ目…という感じに200ステップごとに状態データがセーブされます。
「Save last N steps state」では、過去何ステップ分の状態データを保持するかを指定することができます。
例えば、「Save every N steps」が200の時、このオプションを300に指定してみます。800ステップ目には、本来なら200、400、600、800ステップ時点の状態がセーブされているはずですが、過去300ステップ分のみを残すよう指定しているので、それより以前(つまり800-300=500ステップ目より前)の200、400ステップ時点の状態データは消去されます。
デフォルトは0で、0の場合はセーブされません。
Full bf 16 training
すべてのウェイトデータをbf16サイズにして学習を行います。これは16ビットのため、32ビットのウェイトデータで学習を行うときに比べてメモリ節約になるでしょう。bf16はなるべく32ビットの精度を保つように工夫された形式なので、もしメモリが不足している場合は試してみてもいいでしょう。
CrossAttention
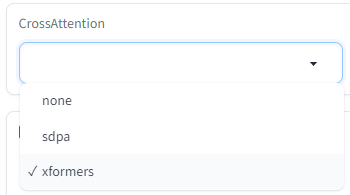
以前は「use xformers」というオプションでした。xformersのほか「sdpa」というアルゴリズムを使用することができるようになりました。
どちらも「計算方法を工夫してメモリを抑えたりパフォーマンスを上げる」という働きをします。
V Pred like loss
学習時、学習画像はそのまま読み込まれるわけではなく、そこに若干のノイズ(砂嵐のようなもの)を乗せてからニューラルネットに読み込まれます。
さて、追加学習の目的は、ニューラルネットが学習画像と同じような画像を作れるようになる事です。つまり、学習画像に乗っているノイズを完全に取り除けるニューラルネットを作りたいのです。ノイズを完璧に取り除ければ、学習画像と同じ画像ができます。
ニューラルネットは入力された画像にいろいろな処理を行って、乗っているノイズを「予測」します。「予測」されたノイズは「実際」のノイズと比べられ、これらが一致するようにニューラルネットを修正していきます。
「予測」ノイズと「実際」ノイズの違いを「損失」と言います。学習とは、「損失」を小さくするようにニューラルネットを変化させていく作業です。
ところで、私たちが欲しいのは「画像」であって「ノイズ」ではありません。この「画像」を少ないステップ数でよりうまく生成するために「ノイズ」の代わりに「v」*1と呼ばれる特殊な値を予測するよう学習する手法が提唱されました。Stable Diffusionバージョン2系はこの「v予測」(v_parameterization)に基づいてモデルが学習されています。
「V Pred like loss」オプションをオンにすると「v予測」学習に似た学習を行います。
デフォルトではオフです。
Min Timestep
Max Timestep
上でも書いた通り、学習画像はランダムにノイズを乗せてからニューラルネットに入力されます。どの程度のノイズが乗るかは毎回ランダムに決まります。ノイズの強さはStable Diffusionの場合0~1000の数字で表され、0はノイズがまったくない状態、1000はノイズしかない状態(つまり砂嵐画像)を表します。
この2つのオプションでは、乗せるノイズの強さの範囲(Min:最小、Max:最大)を決めることができます。
乗せるノイズの最大値を小さくすると、学習後のLoRAは画像生成の初期段階(ノイズだらけの状態の時)にはほとんど機能せず、代わりに画像がある程度浮かんできた状態になってから能力を発揮していきます。これはimg2imgに使用するLoRAを作る際は有益かもしれません。
デフォルトはMinは0、Maxは1000です。通常はこのままで問題ありません。
Scale v prediction loss
これは「v予測」(「V Pred like loss」を参照)をベースにしたバージョン2系モデル向けのオプションです。
「V Pred like loss」で説明した通り、「学習」とは「損失」を小さくする作業です。
「Scale v prediction loss」をオンにすると、この「損失」の値が通常より小さく見積もられます。どれくらい小さくなるかは学習画像に乗っているノイズの量で決まり、ノイズがたくさん乗っているときはあまり小さくせず、ノイズが少ししか乗っていない時はかなり小さくします。
「損失」の値が小さいと、ニューラルネットはあまり変化しません。つまり「ノイズがたくさん乗った画像」を学習するときはニューラルネットを大きく修正し、「ノイズがあまりない画像」を学習する時はあまり修正しない、という挙動になります。
kohya_ssでは、このオプションによって画像内の大まかな構図情報に乗るノイズと微細情報に乗るノイズの予測差異が補償され、画像細部のクオリティが向上すると説明されています。
ただ、このオプションをオンにすると、オフのときよりも学習効率が下がることに注意しましょう。場合によっては学習率(Learning rate)を上げる必要があるかもしれません。
デフォルトはオフです。
まとめ
LoRA学習も普及が進み、量、質、ともに上がってきたので、kohya_ssでも様々なオプションが追加されてきています。もちろんたくさんのパラメータを設定できることで細やかなLoRAが作成できますが、ほとんどのパラメータをデフォルトにしておいても十分実用に耐えるLoRAを作成することができます。
まずは簡単な設定で慣れて、こだわりたくなったらパラメータを変えてみましょう。
*1:v ≡ αt∊ − σtx、∊はノイズ、xは画像