誰でもわかるStable Diffusion AnimateDiff
Stable Diffusionの登場、またLoraやDreamBoothなどのファインチューニング法によって、お絵描きAIはこの1年で驚異的に進化しました。誰もが希望に近い画像を描けるようになってきています。
ここまで生成AIが進歩してくると、今度は画像を動かしたくなってくるものですが、最近になって、Stable Diffusionを使った新たな動画生成技術が発表されました。
今回は生成動画技術である「AnimateDiff」のメカニズムについて解説します。
画像生成のしくみのおさらい
もう何度も説明しましたが、何度説明してもいいくらい重要な技術なので、もう一度説明します。
Stable Diffusionではいくつかのテクニックを使って画像を生成していますが、その大きな特徴は「ノイズから画像を作る」という点です。「ノイズ」とはザラザラの砂嵐画像です。ここから少しずつ少しずつ、何回もノイズを取り除いて画像を浮かび上がらせていきます。これは彫刻に似ていて、荒々しい岩を少しずつ削り彫刻を仕上げていくような作業です。
そして、この「ノイズを取り除く」作業を行うのがStable Diffusionの本体である「U-Net」です。ザラザラ画像と描きたい絵の説明テキスト(「プロンプト」と言います)をU-Netに入れると、U-Netはまず現在の画像とプロンプトを比べて、「こうしたらプロンプトのような画像になる」と判断し、ザラザラ画像からどうノイズを取り除けばいいかを予測します。このU-Netの作業は指定された回数繰り返されます。

もうひとつ重要な技術として、U-Netの作業は「Latent Space」という「画像を圧縮した」状態で行われますが、これは今回の記事と関係が薄いので省略します。
AnimateDiffとは
AnimateDiffとは「アニメーションに特化した画像処理モジュール」です。アニメーションだけに特化しているので、2D系モデルやリアル系モデルなどのいろいろなモデルと一緒に使うことができます。つまり、2D系モデルと一緒に使えばアニメのように、リアル系モデルと一緒に使えば実写ムービーのような動画を作ることができます。
Stable Diffusionを使った動画生成技術は他にもありますが、AnimateDiffは他の技術より比較的破綻が少ないのが特徴です。

AnimateDiffのしくみ
AnimateDiffはどのように実装されているのでしょう?
発表されたレポートを見てみると、以下のような図で説明されています。
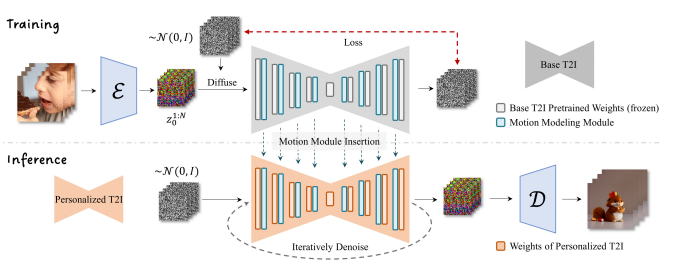
「なんだかよく分からない」と思われるかもしれませんが、ひとつずつ見ていきましょう。
AnimateDiffの本体
AnimateDiffは大きな1つの独立したモジュールというわけではなく、Stable DiffusionのU-Netに挿入する、言ってみれば「プラグイン」のようなものです。
上の図にリボンのような形をした部分(灰色とオレンジ色の部分)がありますが、これは記事の最初に説明したU-Netを表しています。このU-NetはもともとStable Diffusionにあるもので、AnimateDiff独自の機能ではありません。
さて、リボンの中にいくつも長方形があるのに気づかれたでしょう。これら一つ一つが何か「処理」を行っているのですが、この中の水色のものがAnimateDiffで追加される部分です。
この水色部分は「モーションモデリングモジュール」と呼ばれています。
ちなみに、U-Net内の処理について詳しく知りたい方は過去の記事をご覧ください。
水色の処理は、もともとある(灰色またはオレンジの)処理の後ろに追加されていることが分かると思います。つまり、オリジナルのノイズ予測のあとに、さらに画像に修正を加えます。この「修正」こそがAnimateDiffの肝で、この部分で前のコマとの整合性を取りながら、前のコマより少し動いた画像を作ります。
動画を作るために、複数の画像がいっぺんに作られます。これは「バッチ」と呼ばれる処理で、1~32枚(枚数はユーザーが指定できます)の画像をいっぺんに作って、それらをつなげることで短い動画を作ります。今のところはせいぜい最大2秒程度ですが、将来的には時間も長くなっていくでしょう。
モーションモデリングモジュールの機能
モーションモデリングモジュールの中身は「Self Attention」と呼ばれる処理です。これは「Transformer」というメカニズム内で使われている処理です。
これらは複雑なので詳しい説明は以下の記事をご覧ください。
画像にSelf Attentionを行う場合、普通は「各マスどうしの特徴を比較して、関係の強そうな情報を取り込む」という処理を行います。しかしモーションモデリングモジュールのSelf Attentionでは、各マス同士でなく、同じマス内の「各フレームどうしの特徴」を比較します。フレームとはアニメーションにとってもっとも重要な時間情報なので、この処理によって各フレームの整合性を保つのです。
各フレームを比較しなければいけないので、バッチ処理によって複数コマ画像をいっぺんに作る必要があります。
AnimateDiffの学習
もう一度図を見てみると、「トレーニング」部分(上半分)と「実際の画像生成」部分(下半分)に分かれていることが分かります。
AnimateDiffはただの「しくみ」なので、最初は何もできず、学習して賢くなる必要があります。そこでたくさんの動画を使って学習をします。それが上半分の「トレーニング」部分です。
まず何か元となるU-Net(モデル)を用意します。そこにAnimateDiffのモジュールであるモーションモデリングモジュール(図の水色の四角)を挿入します。このモジュールは最初は何もしません。このU-Netで学習を始めます。
一番左にある何枚かの画像は、動画を1コマずつ切り出したものです。
画像の右に「ε」という部分がありますが、これは「オートエンコーダー」または「VAE」と呼ばれるもので、ここで画像を圧縮して「Latent Space」と呼ばれる状態にするのですが、本記事では重要でないので無視してかまいません。
VAEの右のカラフルな砂嵐は「圧縮」された入力画像です。これらの圧縮画像は「ノイズ」がランダムに加えられた後にU-Netに送られ、処理され、予測されたノイズが右側から出てきます。
出てきた予測ノイズを「実際の」ノイズと比べて、同じになるようにU-Netを修正します(この「修正」こそが「学習」です)。もし予測ノイズが実際のノイズと同じなら、ザラザラ画像から予測ノイズを取り除けば、完璧に元画像を復元できることになります。
さて、「U-Netを修正する」と説明しましたが、ここで修正するのは水色の部分のみです。つまり、オリジナルのU-Net(一般に「モデル」と呼ばれるものです)はまったく修正しません。修正するのは水色の部分、モーションモデリングモジュールのみです。
AnimateDiffを使う
図の下半分「Inference」と書かれている部分が実際にAnimateDiffを使って画像を生成する部分です。
まず、学習済みのモーションモデリングモジュールをオレンジ色のU-Netに挿入します。
ここで特筆すべきことは、「オレンジ色のU-Netは何でも構わない」ということです。U-Netとは、つまり、「モデル」です。Stable Diffusionのモデルはいろいろ配布されていますが、どのモデルもAnimateDiffと一緒に使えます*1。もちろん相性があるので、変なアニメーションしかできないモデルもあるかもしれませんが、構造的にはどのモデルとも使えます。
画像生成のプロセスは冒頭で説明した通りです。ノイズだらけの画像をU-Netに突っ込むと、U-Net(とモーションモデリングモジュール)がノイズを予測し、取り除きます。この作業を指定された回数繰り返し、最後に画像を「展開」(図の「D」と書かれた部分が行います)すれば画像が出てきます。
普通のU-NetとAnimateDiffが違うのは、モーションモデリングモジュールが動きも考慮した構図の画像を作り出す、という点です。
AnimateDiffってLoRAっぽい?
説明を読んで、「あれ?なんかこれってLoRAのしくみに似てない?」と思われた方がいるかもしれません。
その通りです。「元のモデルをいじらず、追加されたニューラルネットのみを学習する」という点で、LoRAとAnimateDiffは本質的に同じです。LoRAの場合は、もっと細かくU-Netの様々な部分に追加されますが、AnimateDiffは大きなブロックがひとつ各サイズごとに追加されるのみです(サイズについては今回は説明しません)。
まとめ
今回はStable Diffusionを使った動画作成技術であるAnimateDiffについて解説しました。
これはU-Netに新たな処理モジュールを追加してそれに動画作成機能を持たせるものです。そこにはTransformerというメカニズムで提唱されたSelf Attentionという処理が使われていますが、これはもともとのU-Netでも使われているメカニズムで、いかにTransformerが優れているかがわかる応用例だと思います。
LoRA学習に使われるKohya-ssと同じように、今後AnimateDiffについても追加学習のためのツールが出てくるかもしれませんね。
*1:ただし2023年9月現在、Stable Diffusionのバージョン1.5のみ動作保証されています