誰でもわかるStable Diffusion 新バージョン「SDXL」の概要
Stable Diffusionが登場してもう1年近く経ちます。登場以来、この画像生成AIは世界中にとてつもないインパクトを与えました。
AIはものすごい勢いで進化していますが、Stable Diffusionも例外ではありません。バージョン1からバージョン2にアップグレードし、最近になってさらにアップデートしたバージョン「XL」が登場しました。
今回はこの新バージョンが前バージョンと何が違うのか見てみましょう。
※私はまだXLを触っていないので、ここで解説する情報ははXLの紹介ページから得たものです。間違いがある場合は教えてください。
Stable Diffusion XLの特徴
「XL」とはバージョンの名前です。バージョン2の後バージョンとして発表されました。
なぜ「3」のような数字でなく「XL」なのかは不明ですが、おそらく2と明確に区別したかったのでしょう。Stable Diffusionバージョン2は正直言ってあまり画像クオリティが上がったとはいえず、今でもそれほど普及していません。
開発サイドとしては「今回は2と違ってかなり進歩しました」というアピールの表れのような気がします。
開発に関わっているStability.ai社によると、XLの大きな特徴は以下のようなものです。
- 美麗な写実的画像。Stable Diffusionは登場当時からきれいな写実的な絵を描けていましたが、さらにパワーアップしました。
- 人体構造の正確化。AI画像生成の最大の欠点のひとつが人体をうまく描けないことです。前バージョンでは特に手の指がおかしかったり、人体構造がおかしかったりしました。XLでは人体構造をはるかに正確に描けるようになります。また、顔もきれいに描けます。
- しっかり文字が描ける。前バージョンは絵の中に文字を描かせてもなんだかよく分からない象形文字のようなものが多かったのですが、XLではアルファベットとや日本語などちゃんと読める文字を描けるとのことです。
- プロンプトが簡潔に書ける。前バージョンでは呪文のような特殊なプロンプト構文をずらずらと並べてStable Diffusionにきれいな絵を描かせていましたが、XLではテキスト翻訳機能である「テキストエンコーダー」の機能強化により短いプロンプトでもきちんときれいな絵が描けるようになりました。
- 画像合成クオリティの向上。画像内にあるいろいろな要素がより矛盾なく描画されるようになります。そのほか、画像の一部だけを生成しなおす「インペイント」や画像全体の構造を保ったまま違う絵を生成する「img-to-img」など、生成画像の編集による破綻が少なく、高品質な画像を合成できます。
このような品質向上をどうやって実現したのか、その仕組みの概要を見ていきます。
Stable Diffusion XLの変更点
XLを発表した論文には、バージョン1系(現時点で一番よく使われているバージョンです)との違いが描かれています。
- U-Net内のTransformerブロックの数が3.75倍に増えた
- テキストエンコーダーが1つから2つに増えた
- プロンプトの各トークンの数字表現(ベクトル)内の数字が768個から2048個に増えた
- いろいろな解像度の学習画像データを有効活用できるようにした
- 対象物の「見切れ」を減らす工夫をした
- VAEを再チューニングしてディテール表現を向上させた
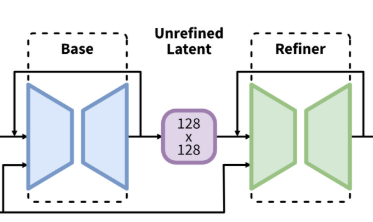
- 本体のU-Netの後にもう1つ「リファイン用U-Net」を追加した(ただしこれはオプション)
青いU-Netと緑のU-Netの2段構え
Transformerブロックの数が増えた
(追記:説明が正しくなかったので修正しました。コメント下さったxrgさんに感謝します。)
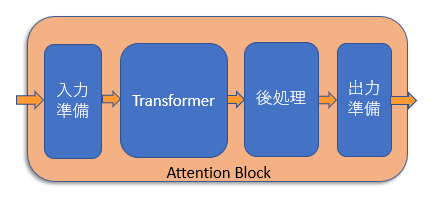
Stable Diffusionの本体であるU-Netはたくさんのブロックからなっています。

オレンジのブロックがAttentionブロック
そのうち「Attention」ブロックと呼ばれるもの(図の中のオレンジのブロック)は画像データにテキストデータを混ぜ込む重要な役割を果たしていますが、この処理を行うのが「Transformer」と呼ばれるものです。
「Attentionブロックの中にTransformerという処理がある」と考えてください。
U-Netが画像データを処理する時、画像データは1/1、1/2、1/4、1/8と縮小され、各サイズごとにAttentionブロックで処理が行われます。
上の図から分かる通り、各画像サイズごとに複数回のAttentionブロック処理が行われています。ただし画像サイズ1/8のときはAttentionブロックは1つだけです。
バージョン1系の場合、それぞれのAttentionブロック内でTransformer処理が必ず1度行われます。
これに対し、SDXLでは画像サイズによってAttentionブロック内のTransformer処理の回数が変わります。
具体的には、画像サイズが1/1(最大)のときはAttentionブロックはTransformer処理を行いません(0回)。1/2のときはAttentionブロック内で2回、1/4のときはAttentionブロック内で10回もTransformer処理が行われます。一方、画像サイズが1/8のときはAttentionブロックじたいが削除されています。
Transformer処理の総数でいえば、バージョン1系の16回からSDXLの60回、3.75倍の回数に増えています。
Transformerの働きは「画像内のそれぞれのマス位置の情報を比べ、混ぜる」ことと、「画像とテキストの情報を比べ、混ぜる」ことです。SDXLでは「最大画像サイズ」と「最小画像サイズ」でこの処理が削除され、「中間画像サイズ」でこの処理を何度も行います。画像の微細情報と構図情報の両方を精度よく描くための工夫なのだと思います。
テキストエンコーダーが増えた
テキストエンコーダーは、ユーザーから与えられたプロンプト(要するにテキスト)を数字の列(ベクトル)に変換するモジュールです。数字の列になって初めて、Stable Diffusionはテキストの意味を理解できるようになります。
バージョン1系では、「CLIP」というテキストエンコーダーを使っていました。このCLIPは非常に賢く、プロンプト内の単語(トークン)がどんなカテゴリに属しているのか、どういう意味があるのか、他の単語との関係はどうか、プロンプト中のどの位置にあるか、などの情報を全部詰め込んだベクトルを計算してくれます。
SDXLではこのテキストエンコーダーに加えてもう一つ、「OpenCLIP ViT-bigG」というテキストエンコーダーが追加されています。OpenCLIPとはCLIPのバージョンアップ版で、より精度の高いベクトル変換ができます。名前の後ろに「bigG」という単語がくっついていますが、これは「たくさん」という意味だと捉えてください。「たくさん学習したので賢いよ」ということです。
追加されたテキストエンコーダーは既存のテキストエンコーダーと一緒に使われます。プロンプト内の各トークンは2つのテキストエンコーダーに別々に送られ、それぞれがベクトルを計算します。結果的に2つのベクトルが得られますが、この2つは合体して1つの大きなベクトルになり、画像データと混ぜられます(後述)。
プロンプトの各トークンのベクトルが大きくなった
下の図はU-Netの中にあるAttentionブロックが行っている「Cross Attention」という処理を説明したものです。左側に「画像データ」と「テキストデータ」がありますが、これら2つが「賢い方法」によって混ぜられて、その結果、画像データの中にテキスト情報が入り込みます。
この図に描かれている「賢い方法」の詳細については過去の記事をご覧ください。
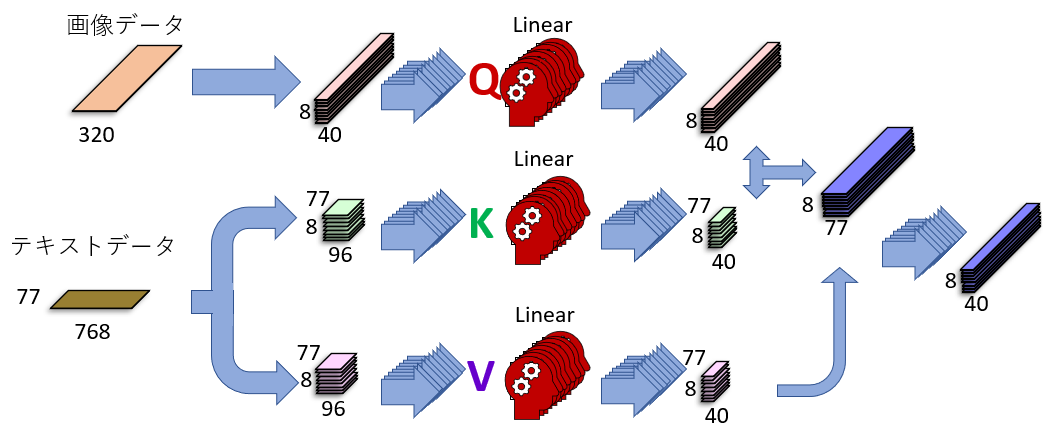
さて、これは「バージョン1」のAttentionブロックです。SDXLでは、左下の「テキストデータ」が768でなく、2048に増えています。その結果、テキストデータが持つ情報量が3倍近く増えます。情報量が増えると、より詳細に、正確に、テキスト情報を画像データに練り込むことができます。
いろいろな解像度を取り込んだ
Stable Diffusionは、事前にたくさんの画像を取り込んで学習し、膨大な画像情報を中に蓄えます。この蓄えられたデータをもとに絵を描くのです。
バージョン1系のStable Diffusionは学習に512x512ピクセル以上の画像を使い、512x512に満たない画像は学習に使わず捨てていました。しかし、用意された学習データの実に4割近くが512x512ピクセルに満たない画像だったので、膨大な数の画像を捨てていたことになります。これはもったいないことです。
SDXLは、これらの小さな画像も無視せずに全部学習に使います。しかし何も工夫せずにいろいろな解像度の画像を学習させると、問題が起こります。
例えば小さな顔画像と大きな顔画像を混ぜて学習するとします。それを使って大きな顔画像を生成するとき、もし小さな顔画像の情報が使われたら、モザイクがかかったような荒い顔になってしまう可能性があります。これを避けるには、生成する画像の解像度に応じて使用する学習データを切り替える必要があります。
これを実装するため、SDXLでは画像を学習するときに「解像度情報」を一緒に取り込むようにしました。この情報はベクトルに変換され(詳細は省略)、Resブロックの「時間情報」ベクトル(いまが処理の何ステップ目かを記録するベクトル)とともに画像データに追加されます。
「見切れ」を減らす工夫をした
学習画像は適当に切り抜かれてから学習されます。そのため、たくさんの「見切れ」画像が学習されることになります。つまり、キャプションは「ネコの上半身」となっていても実際はネコの首しか映っていない、ということもあり得るわけです。Stable Diffusionがそれを「上半身」と学習してしまったら、「ネコの上半身」と指定しても首の絵しか出てこなくなってしまいます。
SDXLは、「画像が見切れているか」の情報も学習画像に追加します。具体的には、画像の「左上」の座標を画像データに組み込みます。もし画像が見切れていなかったら、この座標は「ゼロ」になります。見切れている場合、例えば上側が100ピクセル切り取られている場合、この座標のタテ側は「100」となります。
こうした情報は、上で紹介した「解像度情報」と同じように、ベクトル化されて画像データに追加されます。
VAEが再チューンされた
VAEとは、画像データを圧縮、展開するモジュールです。画像データそのままだと処理が膨大になりすぎるので、圧縮状態の画像を処理しているわけです。
SDXLでVAEが再チューニングされましたが、学習方法を少し変えたおかげで、展開時に微細情報をより精細に描写できるようになったそうです。
ちなみにバージョン1系の「基本画像解像度」は512x512ピクセルでしたが、SDXLで1024x1024ピクセルまで拡大されました。VAEでタテヨコそれぞれ8分の1に圧縮されるので、SDXLの基本圧縮サイズは128x128マスとなります。
「リファイン用U-Net」が追加された
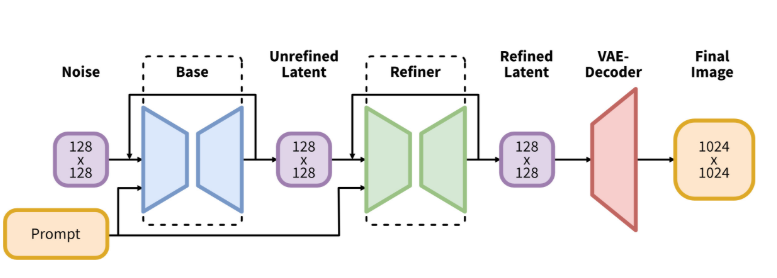
上にあるSDXLの図をもういちど見てみましょう。U-Netが2つあります。
「Base」と書かれているものは本体のU-Netです。これに加えて「Refiner」というU-Netが増えています。このU-Netは実質「img-to-img」用に特別にチューニングされたU-Netです。Baseで出てきた画像をさらにきれいにするために、細かい部分も微調整するのが主な働きです。どちらも画像を「圧縮」状態で扱います。
ただ、リファイン用U-NetはSDXLに必須の機能ではありません。用意はされていますが、使わなくても構わないのです。実際これを使うと処理時間が2倍かかるので、「微調整なんかいらないから画像を速く生成したい」という人はこのモジュールをスキップすることができます。
Stable Diffusion XLのクオリティは?
メジャーなバージョンアップなので当然生成画像の劇的なクオリティ向上を期待したいところなのですが、実際はどうでしょう?
私は試していないのでこの点については何とも言えませんが、生成メカニズムを見る限り「確実に画質は上がるけど驚愕すべきほどではないかもしれない」という印象です。
高解像度画像を生成するときの破綻は減るかもしれません。学習画像がいろいろな解像度に対応したので、構図のクオリティ向上には貢献すると思います。ただ、これらの機能は現バージョンでもLoRAなど追加学習で一部対応可能です。
プロンプト解釈が賢くなった、という宣伝文句ですが、確かにテキストエンコーダーが賢くなったので、プロンプト理解も賢くなったかもしれません。より短いプロンプトで思い通りの絵を描けるようになる、という効果は確かにあると思います。
「リファイン用U-Net」ですが、Stable Diffusion WebUIには「Highres Fix」や「img-to-img」という機能があり、実質的にはリファインU-Netと同じような事をしているので、すでにその恩恵を受けていた人は多いかもしれません。
Stable Diffusionはバージョン1のころから有志のユーザーたちがいろいろな工夫を凝らして画像品質を上げてきましたが、それらの工夫を公式が改良し取り入れ、まとめ上げた感じ、というのがXLに対する私の印象です。
バージョン2やXLは確かにすごいんですが、バージョン1が登場時点ですでにすごすぎたんでしょうね。
まとめ
今回はStable Diffusionの最新版であるSDXLの機能の概要を紹介しました。
様々な工夫を凝らして画像品質の向上を図っていますが、ほとんどは既存の機能の拡張という感じです。U-Netがもう1つ増えましたが、これはSDXLの特徴を決定づけるほどの大きなインパクトを持っているわけではありません。
学習解像度は向上しているので、今後の主力はSDXLに少しずつ移行していくのかもしれません。しかしバージョン1系のStable Diffusionもまだまだ現役でバリバリ働いていくんだろうな、という印象を持ちました。