誰でもわかるStable Diffusion AnimateDiff
Stable Diffusionの登場、またLoraやDreamBoothなどのファインチューニング法によって、お絵描きAIはこの1年で驚異的に進化しました。誰もが希望に近い画像を描けるようになってきています。
ここまで生成AIが進歩してくると、今度は画像を動かしたくなってくるものですが、最近になって、Stable Diffusionを使った新たな動画生成技術が発表されました。
今回は生成動画技術である「AnimateDiff」のメカニズムについて解説します。
画像生成のしくみのおさらい
もう何度も説明しましたが、何度説明してもいいくらい重要な技術なので、もう一度説明します。
Stable Diffusionではいくつかのテクニックを使って画像を生成していますが、その大きな特徴は「ノイズから画像を作る」という点です。「ノイズ」とはザラザラの砂嵐画像です。ここから少しずつ少しずつ、何回もノイズを取り除いて画像を浮かび上がらせていきます。これは彫刻に似ていて、荒々しい岩を少しずつ削り彫刻を仕上げていくような作業です。
そして、この「ノイズを取り除く」作業を行うのがStable Diffusionの本体である「U-Net」です。ザラザラ画像と描きたい絵の説明テキスト(「プロンプト」と言います)をU-Netに入れると、U-Netはまず現在の画像とプロンプトを比べて、「こうしたらプロンプトのような画像になる」と判断し、ザラザラ画像からどうノイズを取り除けばいいかを予測します。このU-Netの作業は指定された回数繰り返されます。

もうひとつ重要な技術として、U-Netの作業は「Latent Space」という「画像を圧縮した」状態で行われますが、これは今回の記事と関係が薄いので省略します。
AnimateDiffとは
AnimateDiffとは「アニメーションに特化した画像処理モジュール」です。アニメーションだけに特化しているので、2D系モデルやリアル系モデルなどのいろいろなモデルと一緒に使うことができます。つまり、2D系モデルと一緒に使えばアニメのように、リアル系モデルと一緒に使えば実写ムービーのような動画を作ることができます。
Stable Diffusionを使った動画生成技術は他にもありますが、AnimateDiffは他の技術より比較的破綻が少ないのが特徴です。

AnimateDiffのしくみ
AnimateDiffはどのように実装されているのでしょう?
発表されたレポートを見てみると、以下のような図で説明されています。
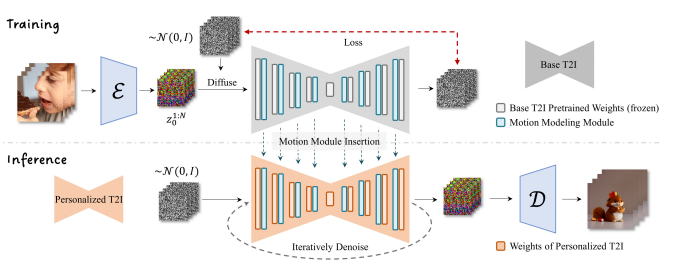
「なんだかよく分からない」と思われるかもしれませんが、ひとつずつ見ていきましょう。
AnimateDiffの本体
AnimateDiffは大きな1つの独立したモジュールというわけではなく、Stable DiffusionのU-Netに挿入する、言ってみれば「プラグイン」のようなものです。
上の図にリボンのような形をした部分(灰色とオレンジ色の部分)がありますが、これは記事の最初に説明したU-Netを表しています。このU-NetはもともとStable Diffusionにあるもので、AnimateDiff独自の機能ではありません。
さて、リボンの中にいくつも長方形があるのに気づかれたでしょう。これら一つ一つが何か「処理」を行っているのですが、この中の水色のものがAnimateDiffで追加される部分です。
この水色部分は「モーションモデリングモジュール」と呼ばれています。
ちなみに、U-Net内の処理について詳しく知りたい方は過去の記事をご覧ください。
水色の処理は、もともとある(灰色またはオレンジの)処理の後ろに追加されていることが分かると思います。つまり、オリジナルのノイズ予測のあとに、さらに画像に修正を加えます。この「修正」こそがAnimateDiffの肝で、この部分で前のコマとの整合性を取りながら、前のコマより少し動いた画像を作ります。
動画を作るために、複数の画像がいっぺんに作られます。これは「バッチ」と呼ばれる処理で、1~32枚(枚数はユーザーが指定できます)の画像をいっぺんに作って、それらをつなげることで短い動画を作ります。今のところはせいぜい最大2秒程度ですが、将来的には時間も長くなっていくでしょう。
モーションモデリングモジュールの機能
モーションモデリングモジュールの中身は「Self Attention」と呼ばれる処理です。これは「Transformer」というメカニズム内で使われている処理です。
これらは複雑なので詳しい説明は以下の記事をご覧ください。
画像にSelf Attentionを行う場合、普通は「各マスどうしの特徴を比較して、関係の強そうな情報を取り込む」という処理を行います。しかしモーションモデリングモジュールのSelf Attentionでは、各マス同士でなく、同じマス内の「各フレームどうしの特徴」を比較します。フレームとはアニメーションにとってもっとも重要な時間情報なので、この処理によって各フレームの整合性を保つのです。
各フレームを比較しなければいけないので、バッチ処理によって複数コマ画像をいっぺんに作る必要があります。
AnimateDiffの学習
もう一度図を見てみると、「トレーニング」部分(上半分)と「実際の画像生成」部分(下半分)に分かれていることが分かります。
AnimateDiffはただの「しくみ」なので、最初は何もできず、学習して賢くなる必要があります。そこでたくさんの動画を使って学習をします。それが上半分の「トレーニング」部分です。
まず何か元となるU-Net(モデル)を用意します。そこにAnimateDiffのモジュールであるモーションモデリングモジュール(図の水色の四角)を挿入します。このモジュールは最初は何もしません。このU-Netで学習を始めます。
一番左にある何枚かの画像は、動画を1コマずつ切り出したものです。
画像の右に「ε」という部分がありますが、これは「オートエンコーダー」または「VAE」と呼ばれるもので、ここで画像を圧縮して「Latent Space」と呼ばれる状態にするのですが、本記事では重要でないので無視してかまいません。
VAEの右のカラフルな砂嵐は「圧縮」された入力画像です。これらの圧縮画像は「ノイズ」がランダムに加えられた後にU-Netに送られ、処理され、予測されたノイズが右側から出てきます。
出てきた予測ノイズを「実際の」ノイズと比べて、同じになるようにU-Netを修正します(この「修正」こそが「学習」です)。もし予測ノイズが実際のノイズと同じなら、ザラザラ画像から予測ノイズを取り除けば、完璧に元画像を復元できることになります。
さて、「U-Netを修正する」と説明しましたが、ここで修正するのは水色の部分のみです。つまり、オリジナルのU-Net(一般に「モデル」と呼ばれるものです)はまったく修正しません。修正するのは水色の部分、モーションモデリングモジュールのみです。
AnimateDiffを使う
図の下半分「Inference」と書かれている部分が実際にAnimateDiffを使って画像を生成する部分です。
まず、学習済みのモーションモデリングモジュールをオレンジ色のU-Netに挿入します。
ここで特筆すべきことは、「オレンジ色のU-Netは何でも構わない」ということです。U-Netとは、つまり、「モデル」です。Stable Diffusionのモデルはいろいろ配布されていますが、どのモデルもAnimateDiffと一緒に使えます*1。もちろん相性があるので、変なアニメーションしかできないモデルもあるかもしれませんが、構造的にはどのモデルとも使えます。
画像生成のプロセスは冒頭で説明した通りです。ノイズだらけの画像をU-Netに突っ込むと、U-Net(とモーションモデリングモジュール)がノイズを予測し、取り除きます。この作業を指定された回数繰り返し、最後に画像を「展開」(図の「D」と書かれた部分が行います)すれば画像が出てきます。
普通のU-NetとAnimateDiffが違うのは、モーションモデリングモジュールが動きも考慮した構図の画像を作り出す、という点です。
AnimateDiffってLoRAっぽい?
説明を読んで、「あれ?なんかこれってLoRAのしくみに似てない?」と思われた方がいるかもしれません。
その通りです。「元のモデルをいじらず、追加されたニューラルネットのみを学習する」という点で、LoRAとAnimateDiffは本質的に同じです。LoRAの場合は、もっと細かくU-Netの様々な部分に追加されますが、AnimateDiffは大きなブロックがひとつ各サイズごとに追加されるのみです(サイズについては今回は説明しません)。
まとめ
今回はStable Diffusionを使った動画作成技術であるAnimateDiffについて解説しました。
これはU-Netに新たな処理モジュールを追加してそれに動画作成機能を持たせるものです。そこにはTransformerというメカニズムで提唱されたSelf Attentionという処理が使われていますが、これはもともとのU-Netでも使われているメカニズムで、いかにTransformerが優れているかがわかる応用例だと思います。
LoRA学習に使われるKohya-ssと同じように、今後AnimateDiffについても追加学習のためのツールが出てくるかもしれませんね。
*1:ただし2023年9月現在、Stable Diffusionのバージョン1.5のみ動作保証されています
誰でもわかるStable Diffusion kohya_ssの追加パラメータを解説
以前の記事でkohya_ssの各パラメータについて解説しました。
別に万人向けの有益な情報として書いたつもりはなかったんですが、最近になってこの記事へのアクセスが多くなってきたため、需要はあるのかなあと思う一方、進歩の著しいkohya_ssの最新バージョンから見ると数カ月前に書かれたこの記事は情報が古い部分もあります。
そこで今回は、kohya_ssの前回から変わった部分を補足解説していこうと思います。
今回解説するkohya_ssのバージョンはv21.8.8です。
- kohya_ssの基本画面
- LoRAタブ内の構造
- Trainingタブ内の構造
- Source modelタブの変更点
- Foldersタブの変更点
- Parametersタブの変更点
- Max train steps
- Optimizer
- LR scheduler extra arguments
- Minimum bucket resolution
- Maximum bucket resolution
- Weight norms、Dropoutオプションについての前知識
- Scale weight norms
- Network dropout
- Rank dropout
- Module dropout
- VAE
- Save last N steps state
- Full bf 16 training
- CrossAttention
- V Pred like loss
- Min Timestep
- Max Timestep
- Scale v prediction loss
- まとめ
kohya_ssの基本画面
下の画面はkohya_ssを立ち上げたときに表示される基本画面です。kohya_ssのそれぞれの機能はタブによってまとめられていることが分かります。
バージョンは右下に常に表示されます。
一番上のタブグループを見てみましょう。
追加学習タブ
kohya_ssは「Dreambooth」、「LoRA」、「Textual Inversion」、「Finetuning」という4種類の方法で追加学習を行えます。これら4種類の追加学習設定がそれぞれ独立してタブにまとめられています。
現在ではLoRA学習が主流なので、ほとんどの人は左から2番目の「LoRA」タブを選ぶことになると思います。そのため、この記事ではLoRAタブのみを解説します。
Utilitiesタブ
「Utilities」では「学習用の画像を準備する」ためのツールと「学習済みモデルを加工、変換、出力する」ためのツールが用意されています。
kohya_ssを追加学習ツールとして使うのであれば、「画像をサイズごとにまとめる」、「学習画像にキャプションをつける」などの学習画像準備ツールがよく利用されると思います。
本記事ではユーティリティについては解説しません。
Aboutタブ
これはヘルプページです。バージョン情報もトップに表示されます。
ここではインストールやアップデート、立ち上げに関するヘルプが詳細に書かれています。ただ、このヘルプ画面を見ているということはもうkohya_ssのインストールができているはずなので、読み進める必要はないかもしれません。
その他、各追加学習についての解説動画や外部リンクが軽く紹介されています。
LoRAタブ内の構造
本記事では「LoRA」タブの中身のみ解説します。
「LoRA」タブ内にはさらに「Training」「Tools」「Guides」という3つのタブがあります。
Trainingタブ
「Training」タブは追加学習設定の本体です。ここで主要なパラメータをすべて設定し、学習を行います。ここにあるパラメータの大部分は以前の記事で解説しましたが、新たに追加されたパラメータについては後述します。
Toolsタブ
ここではLoRAファイルやLyCORISファイルを抽出したり合体させたりできます。LoRA学習を行った後に使うツールがほとんどなので、学習前には必要ないでしょう。
ただ、「Dataset Preparation」というタブでは、学習準備のための2つのツールが用意されています。
- 「Folder preparation」:学習画像の特殊なフォルダ構造を自動で作成、ネーミング、整理してくれる機能です。この機能は画像自体には変更を加えません。
- 「Dataset balancing」:それぞれのコンセプトの画像がほぼ同じステップ数学習されるように、学習ステップ数を自動計算します。例えば「コンセプト1」フォルダが20枚の画像を持ち、「コンセプト2」フォルダが40枚の画像を持つ場合、「コンセプト1」フォルダの繰り返し学習数を「コンセプト2」フォルダの2倍にします。
Guidesタブ
LoRA学習の実行や開発のためのガイドがここに追加されていくそうです。現在は学習のためのガイドが少しだけ触れられています。
Trainingタブ内の構造
いよいよLoRA学習の本体、「Training」タブを見ていきます。ここにはさらに4つのタブがあります。これは以前の記事のときとだいたい同じ構造です。

なお、「Dataset Preparation」タブの中身は、一つ上の「Tools」タブ内にある「Dataset Preparation」タブの中身と全く同じです。
Source modelタブの変更点
Source modelタブでは、「SDXL Model」オプションが追加されています。これはバージョン2に続く最新バージョンで、Stable Diffusionの構造も大きく変わっています。SDXLモデルを使うときは必ずオンにしておきましょう。
Foldersタブの変更点
Foldersタブ内のパラメータは以前から変わっていません。
Parametersタブの変更点
Parametersタブ内のパラメータは、さらに「Basic」「Advanced」「Samples」の3つのタブに整理されました。一部場所を移動したパラメータもありますが、機能は同じです。
ここでは追加されたパラメータのみを解説します。
Max train steps
「Max train epoch」オプションと似たような働きをします。
通常ステップ数は画像数x繰り返し数xエポック数で決まりますが、上限ステップ数をここで指定することもできます。ここで指定したステップ数に達すると、学習が強制的に終了します。
デフォルトは空欄です。ステップ数を抑える必要がない場合は空欄のままで構いません。
Optimizer
オプティマイザーは「学習中にニューラルネットのウェイトをどうアップデートするか」の設定です。以前の記事に比べてオプティマイザーの数が増えていますが、基本的に「AdamW」または「AdamW8bit」を使っておけば問題ありません。

以下は追加されたオプティマイザーです。
- DAdaptadanIP
- DAdaptAdamPreprint
- DAdaptLion
- PagedAdamW8bit
- PagedLion8bit
- Prodigy
このうち、「Paged」オプティマイザーは学習時に発生する突発的なメモリ不足エラーを防止する機能を備えたオプティマイザー、またProdigyは最近提唱された「DAdapt」バリエーションの改良版で、「DAdapt」より素早く正確に学習が収束すると報告されています。
LR scheduler extra arguments
スケジューラーのための追加設定をここでコマンド表記できます。空欄で構いません。
Minimum bucket resolution
Maximum bucket resolution
これら2つのオプションは、「Enable buckets」にチェックが入っている場合のみ有効のオプションです。
「bucket」とは学習画像をサイズごとに振り分けて入れておく「バケツ」です。LoRAは様々な解像度の画像を混ぜて学習することができますが、この2つのオプションで最小画像サイズと最大画像サイズを指定することができます。どちらも64ピクセル未満の数字を指定することはできません。
Weight norms、Dropoutオプションについての前知識
LoRAとは、オリジナルのモデルの大きなニューラルネットに追加する小さなニューラルネットです(詳細は過去の記事をご覧ください)。この小さなニューラルネットがオリジナルのモデル(正確にはU-Netという構造をしています)の中のあちこちに何十個も追加されます。この「小さなニューラルネット」ひとつを便宜的に「モジュール」と呼びます。
LoRAモジュールは「ダウンウェイト」「ランク」「アップウェイト」からなっています。「ランク」とは真ん中の層のニューロンの数です。
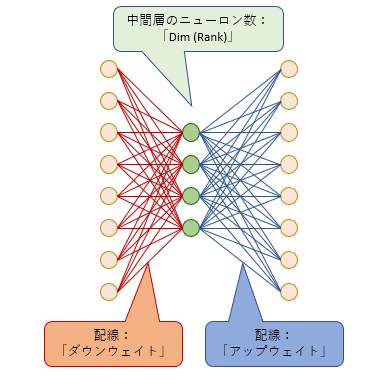
これらを踏まえて、次の3つのオプションを見てみましょう。
「Dropout」とは、学習ステップごとに毎回一定の確率でこのモジュール内の一部、あるいは全部をスイッチオフするオプションです。スイッチオフされた部分は何もせず、学習もしません。
これは「過学習」を防ぐためのトリックです。「過学習」とは、与えられた学習画像を過度に覚えすぎて融通が利かなくなり、学習画像に似た画像しか作れなくなる状態です。これを防ぐために、時にはある程度学習を「サボる」ことも有効です。
Scale weight norms
LoRA学習によって、上のモジュール内の「ダウンウェイト」と「アップウェイト」の線の太さが変わっていきますが、これをどこまで太くしていいのか、上限を設けることができます。
全体の線の太さは「ノルム」という数値で表すことができます。このノルムを一定範囲に抑えることで、特定の線が太くなりすぎて過学習になったり、学習部位が極端に偏ったりするのを防ぐことができます。また、LoRAを複数併用する時も安定して働くことが期待されます。
0~10の値でどれほど強い上限を設けるかを決められます。数字が小さければ小さいほど強い上限が設けられます。
デフォルトは0で、0の場合はこの機能は無効です。推奨設定は1とされています。
なお、このオプションは後述のDropoutと併用するとさらに効果を発揮するようです。
Network dropout
このオプションでは、モジュール内のダウンウェイトを一定の確率でドロップアウトする(つまり配線を切る)オプションです。0~1の値で、値が大きいほどドロップアウトの確率が増えます。
デフォルトは0です。推奨範囲は0.1~0.5とされています。
Rank dropout
このオプションでは、モジュールの真ん中のニューロンを一定の確率でドロップアウトするオプションです。0~1の値で、値が大きいほどドロップアウトの確率が増えます。
デフォルトは0です。推奨範囲は0.1~0.3とされています。
Module dropout
モジュール丸ごとを一定の確率で無効にするオプションです。つまり(その部分では)LoRAがまったく効いていない状態になります。もちろん一部のモジュールが無効になったところで、U-Net内には何十個もモジュールが追加されているので、LoRA学習が無駄になるということはありません。0~1の値で、値が大きいほどドロップアウトの確率が増えます。
デフォルトは0です。推奨範囲は0.1~0.3とされています。
VAE
学習に使用するVAEをここで指定することができます。ここが空欄の場合、VAEはモデルデータ(Sourcd modelタブで指定したもの)に同梱しているものを使用します。
デフォルトは空欄です。
Save last N steps state
このオプションは「Save training state」がオン、かつ「Save every N steps」が0でない時に有効になります。
学習時は途中の状態をセーブしておくことができます。この状態ファイルをロードすると、学習途中の状態から続きを再開することができます。
セーブするタイミングは「Save every N steps」で指定します。例えば「Save every N steps」が200の場合、200ステップ目、400ステップ目、600ステップ目…という感じに200ステップごとに状態データがセーブされます。
「Save last N steps state」では、過去何ステップ分の状態データを保持するかを指定することができます。
例えば、「Save every N steps」が200の時、このオプションを300に指定してみます。800ステップ目には、本来なら200、400、600、800ステップ時点の状態がセーブされているはずですが、過去300ステップ分のみを残すよう指定しているので、それより以前(つまり800-300=500ステップ目より前)の200、400ステップ時点の状態データは消去されます。
デフォルトは0で、0の場合はセーブされません。
Full bf 16 training
すべてのウェイトデータをbf16サイズにして学習を行います。これは16ビットのため、32ビットのウェイトデータで学習を行うときに比べてメモリ節約になるでしょう。bf16はなるべく32ビットの精度を保つように工夫された形式なので、もしメモリが不足している場合は試してみてもいいでしょう。
CrossAttention
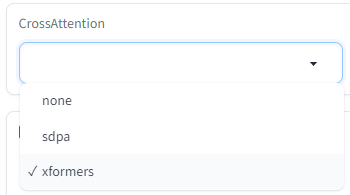
以前は「use xformers」というオプションでした。xformersのほか「sdpa」というアルゴリズムを使用することができるようになりました。
どちらも「計算方法を工夫してメモリを抑えたりパフォーマンスを上げる」という働きをします。
V Pred like loss
学習時、学習画像はそのまま読み込まれるわけではなく、そこに若干のノイズ(砂嵐のようなもの)を乗せてからニューラルネットに読み込まれます。
さて、追加学習の目的は、ニューラルネットが学習画像と同じような画像を作れるようになる事です。つまり、学習画像に乗っているノイズを完全に取り除けるニューラルネットを作りたいのです。ノイズを完璧に取り除ければ、学習画像と同じ画像ができます。
ニューラルネットは入力された画像にいろいろな処理を行って、乗っているノイズを「予測」します。「予測」されたノイズは「実際」のノイズと比べられ、これらが一致するようにニューラルネットを修正していきます。
「予測」ノイズと「実際」ノイズの違いを「損失」と言います。学習とは、「損失」を小さくするようにニューラルネットを変化させていく作業です。
ところで、私たちが欲しいのは「画像」であって「ノイズ」ではありません。この「画像」を少ないステップ数でよりうまく生成するために「ノイズ」の代わりに「v」*1と呼ばれる特殊な値を予測するよう学習する手法が提唱されました。Stable Diffusionバージョン2系はこの「v予測」(v_parameterization)に基づいてモデルが学習されています。
「V Pred like loss」オプションをオンにすると「v予測」学習に似た学習を行います。
デフォルトではオフです。
Min Timestep
Max Timestep
上でも書いた通り、学習画像はランダムにノイズを乗せてからニューラルネットに入力されます。どの程度のノイズが乗るかは毎回ランダムに決まります。ノイズの強さはStable Diffusionの場合0~1000の数字で表され、0はノイズがまったくない状態、1000はノイズしかない状態(つまり砂嵐画像)を表します。
この2つのオプションでは、乗せるノイズの強さの範囲(Min:最小、Max:最大)を決めることができます。
乗せるノイズの最大値を小さくすると、学習後のLoRAは画像生成の初期段階(ノイズだらけの状態の時)にはほとんど機能せず、代わりに画像がある程度浮かんできた状態になってから能力を発揮していきます。これはimg2imgに使用するLoRAを作る際は有益かもしれません。
デフォルトはMinは0、Maxは1000です。通常はこのままで問題ありません。
Scale v prediction loss
これは「v予測」(「V Pred like loss」を参照)をベースにしたバージョン2系モデル向けのオプションです。
「V Pred like loss」で説明した通り、「学習」とは「損失」を小さくする作業です。
「Scale v prediction loss」をオンにすると、この「損失」の値が通常より小さく見積もられます。どれくらい小さくなるかは学習画像に乗っているノイズの量で決まり、ノイズがたくさん乗っているときはあまり小さくせず、ノイズが少ししか乗っていない時はかなり小さくします。
「損失」の値が小さいと、ニューラルネットはあまり変化しません。つまり「ノイズがたくさん乗った画像」を学習するときはニューラルネットを大きく修正し、「ノイズがあまりない画像」を学習する時はあまり修正しない、という挙動になります。
kohya_ssでは、このオプションによって画像内の大まかな構図情報に乗るノイズと微細情報に乗るノイズの予測差異が補償され、画像細部のクオリティが向上すると説明されています。
ただ、このオプションをオンにすると、オフのときよりも学習効率が下がることに注意しましょう。場合によっては学習率(Learning rate)を上げる必要があるかもしれません。
デフォルトはオフです。
まとめ
LoRA学習も普及が進み、量、質、ともに上がってきたので、kohya_ssでも様々なオプションが追加されてきています。もちろんたくさんのパラメータを設定できることで細やかなLoRAが作成できますが、ほとんどのパラメータをデフォルトにしておいても十分実用に耐えるLoRAを作成することができます。
まずは簡単な設定で慣れて、こだわりたくなったらパラメータを変えてみましょう。
*1:v ≡ αt∊ − σtx、∊はノイズ、xは画像
誰でもわかるStable Diffusion 新バージョン「SDXL」の概要
Stable Diffusionが登場してもう1年近く経ちます。登場以来、この画像生成AIは世界中にとてつもないインパクトを与えました。
AIはものすごい勢いで進化していますが、Stable Diffusionも例外ではありません。バージョン1からバージョン2にアップグレードし、最近になってさらにアップデートしたバージョン「XL」が登場しました。
今回はこの新バージョンが前バージョンと何が違うのか見てみましょう。
※私はまだXLを触っていないので、ここで解説する情報ははXLの紹介ページから得たものです。間違いがある場合は教えてください。
Stable Diffusion XLの特徴
「XL」とはバージョンの名前です。バージョン2の後バージョンとして発表されました。
なぜ「3」のような数字でなく「XL」なのかは不明ですが、おそらく2と明確に区別したかったのでしょう。Stable Diffusionバージョン2は正直言ってあまり画像クオリティが上がったとはいえず、今でもそれほど普及していません。
開発サイドとしては「今回は2と違ってかなり進歩しました」というアピールの表れのような気がします。
開発に関わっているStability.ai社によると、XLの大きな特徴は以下のようなものです。
- 美麗な写実的画像。Stable Diffusionは登場当時からきれいな写実的な絵を描けていましたが、さらにパワーアップしました。
- 人体構造の正確化。AI画像生成の最大の欠点のひとつが人体をうまく描けないことです。前バージョンでは特に手の指がおかしかったり、人体構造がおかしかったりしました。XLでは人体構造をはるかに正確に描けるようになります。また、顔もきれいに描けます。
- しっかり文字が描ける。前バージョンは絵の中に文字を描かせてもなんだかよく分からない象形文字のようなものが多かったのですが、XLではアルファベットとや日本語などちゃんと読める文字を描けるとのことです。
- プロンプトが簡潔に書ける。前バージョンでは呪文のような特殊なプロンプト構文をずらずらと並べてStable Diffusionにきれいな絵を描かせていましたが、XLではテキスト翻訳機能である「テキストエンコーダー」の機能強化により短いプロンプトでもきちんときれいな絵が描けるようになりました。
- 画像合成クオリティの向上。画像内にあるいろいろな要素がより矛盾なく描画されるようになります。そのほか、画像の一部だけを生成しなおす「インペイント」や画像全体の構造を保ったまま違う絵を生成する「img-to-img」など、生成画像の編集による破綻が少なく、高品質な画像を合成できます。
このような品質向上をどうやって実現したのか、その仕組みの概要を見ていきます。
Stable Diffusion XLの変更点
XLを発表した論文には、バージョン1系(現時点で一番よく使われているバージョンです)との違いが描かれています。
- U-Net内のTransformerブロックの数が3.75倍に増えた
- テキストエンコーダーが1つから2つに増えた
- プロンプトの各トークンの数字表現(ベクトル)内の数字が768個から2048個に増えた
- いろいろな解像度の学習画像データを有効活用できるようにした
- 対象物の「見切れ」を減らす工夫をした
- VAEを再チューニングしてディテール表現を向上させた
- 本体のU-Netの後にもう1つ「リファイン用U-Net」を追加した(ただしこれはオプション)
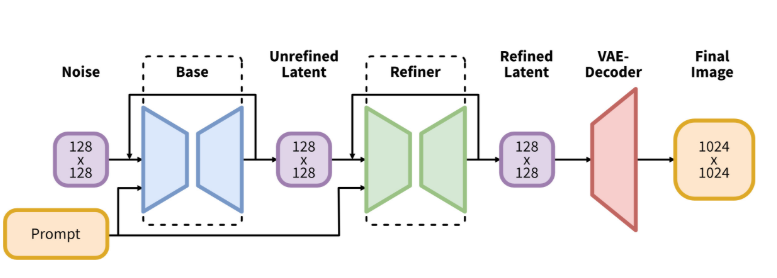
青いU-Netと緑のU-Netの2段構え
Transformerブロックの数が増えた
(追記:説明が正しくなかったので修正しました。コメント下さったxrgさんに感謝します。)
Stable Diffusionの本体であるU-Netはたくさんのブロックからなっています。

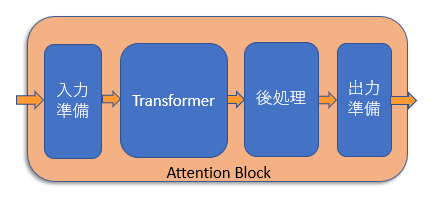
オレンジのブロックがAttentionブロック
そのうち「Attention」ブロックと呼ばれるもの(図の中のオレンジのブロック)は画像データにテキストデータを混ぜ込む重要な役割を果たしていますが、この処理を行うのが「Transformer」と呼ばれるものです。
「Attentionブロックの中にTransformerという処理がある」と考えてください。
U-Netが画像データを処理する時、画像データは1/1、1/2、1/4、1/8と縮小され、各サイズごとにAttentionブロックで処理が行われます。
上の図から分かる通り、各画像サイズごとに複数回のAttentionブロック処理が行われています。ただし画像サイズ1/8のときはAttentionブロックは1つだけです。
バージョン1系の場合、それぞれのAttentionブロック内でTransformer処理が必ず1度行われます。
これに対し、SDXLでは画像サイズによってAttentionブロック内のTransformer処理の回数が変わります。
具体的には、画像サイズが1/1(最大)のときはAttentionブロックはTransformer処理を行いません(0回)。1/2のときはAttentionブロック内で2回、1/4のときはAttentionブロック内で10回もTransformer処理が行われます。一方、画像サイズが1/8のときはAttentionブロックじたいが削除されています。
Transformer処理の総数でいえば、バージョン1系の16回からSDXLの60回、3.75倍の回数に増えています。
Transformerの働きは「画像内のそれぞれのマス位置の情報を比べ、混ぜる」ことと、「画像とテキストの情報を比べ、混ぜる」ことです。SDXLでは「最大画像サイズ」と「最小画像サイズ」でこの処理が削除され、「中間画像サイズ」でこの処理を何度も行います。画像の微細情報と構図情報の両方を精度よく描くための工夫なのだと思います。
テキストエンコーダーが増えた
テキストエンコーダーは、ユーザーから与えられたプロンプト(要するにテキスト)を数字の列(ベクトル)に変換するモジュールです。数字の列になって初めて、Stable Diffusionはテキストの意味を理解できるようになります。
バージョン1系では、「CLIP」というテキストエンコーダーを使っていました。このCLIPは非常に賢く、プロンプト内の単語(トークン)がどんなカテゴリに属しているのか、どういう意味があるのか、他の単語との関係はどうか、プロンプト中のどの位置にあるか、などの情報を全部詰め込んだベクトルを計算してくれます。
SDXLではこのテキストエンコーダーに加えてもう一つ、「OpenCLIP ViT-bigG」というテキストエンコーダーが追加されています。OpenCLIPとはCLIPのバージョンアップ版で、より精度の高いベクトル変換ができます。名前の後ろに「bigG」という単語がくっついていますが、これは「たくさん」という意味だと捉えてください。「たくさん学習したので賢いよ」ということです。
追加されたテキストエンコーダーは既存のテキストエンコーダーと一緒に使われます。プロンプト内の各トークンは2つのテキストエンコーダーに別々に送られ、それぞれがベクトルを計算します。結果的に2つのベクトルが得られますが、この2つは合体して1つの大きなベクトルになり、画像データと混ぜられます(後述)。
プロンプトの各トークンのベクトルが大きくなった
下の図はU-Netの中にあるAttentionブロックが行っている「Cross Attention」という処理を説明したものです。左側に「画像データ」と「テキストデータ」がありますが、これら2つが「賢い方法」によって混ぜられて、その結果、画像データの中にテキスト情報が入り込みます。
この図に描かれている「賢い方法」の詳細については過去の記事をご覧ください。
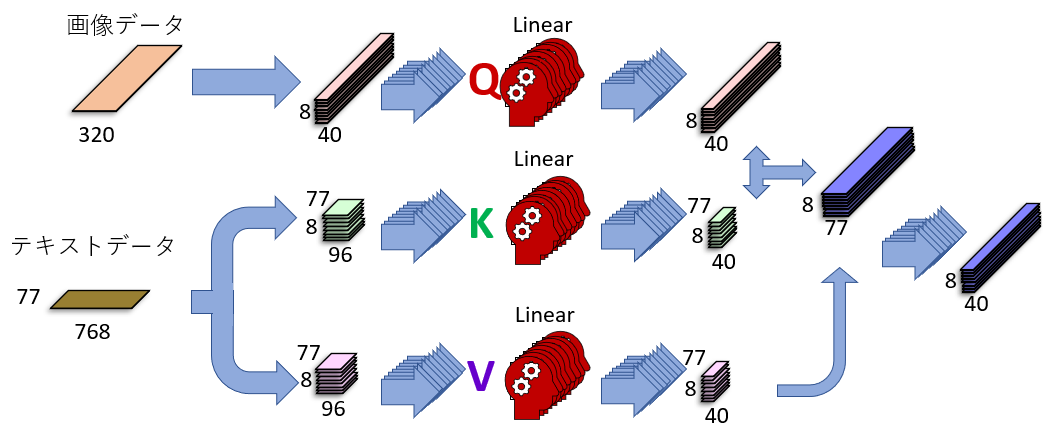
さて、これは「バージョン1」のAttentionブロックです。SDXLでは、左下の「テキストデータ」が768でなく、2048に増えています。その結果、テキストデータが持つ情報量が3倍近く増えます。情報量が増えると、より詳細に、正確に、テキスト情報を画像データに練り込むことができます。
いろいろな解像度を取り込んだ
Stable Diffusionは、事前にたくさんの画像を取り込んで学習し、膨大な画像情報を中に蓄えます。この蓄えられたデータをもとに絵を描くのです。
バージョン1系のStable Diffusionは学習に512x512ピクセル以上の画像を使い、512x512に満たない画像は学習に使わず捨てていました。しかし、用意された学習データの実に4割近くが512x512ピクセルに満たない画像だったので、膨大な数の画像を捨てていたことになります。これはもったいないことです。
SDXLは、これらの小さな画像も無視せずに全部学習に使います。しかし何も工夫せずにいろいろな解像度の画像を学習させると、問題が起こります。
例えば小さな顔画像と大きな顔画像を混ぜて学習するとします。それを使って大きな顔画像を生成するとき、もし小さな顔画像の情報が使われたら、モザイクがかかったような荒い顔になってしまう可能性があります。これを避けるには、生成する画像の解像度に応じて使用する学習データを切り替える必要があります。
これを実装するため、SDXLでは画像を学習するときに「解像度情報」を一緒に取り込むようにしました。この情報はベクトルに変換され(詳細は省略)、Resブロックの「時間情報」ベクトル(いまが処理の何ステップ目かを記録するベクトル)とともに画像データに追加されます。
「見切れ」を減らす工夫をした
学習画像は適当に切り抜かれてから学習されます。そのため、たくさんの「見切れ」画像が学習されることになります。つまり、キャプションは「ネコの上半身」となっていても実際はネコの首しか映っていない、ということもあり得るわけです。Stable Diffusionがそれを「上半身」と学習してしまったら、「ネコの上半身」と指定しても首の絵しか出てこなくなってしまいます。
SDXLは、「画像が見切れているか」の情報も学習画像に追加します。具体的には、画像の「左上」の座標を画像データに組み込みます。もし画像が見切れていなかったら、この座標は「ゼロ」になります。見切れている場合、例えば上側が100ピクセル切り取られている場合、この座標のタテ側は「100」となります。
こうした情報は、上で紹介した「解像度情報」と同じように、ベクトル化されて画像データに追加されます。
VAEが再チューンされた
VAEとは、画像データを圧縮、展開するモジュールです。画像データそのままだと処理が膨大になりすぎるので、圧縮状態の画像を処理しているわけです。
SDXLでVAEが再チューニングされましたが、学習方法を少し変えたおかげで、展開時に微細情報をより精細に描写できるようになったそうです。
ちなみにバージョン1系の「基本画像解像度」は512x512ピクセルでしたが、SDXLで1024x1024ピクセルまで拡大されました。VAEでタテヨコそれぞれ8分の1に圧縮されるので、SDXLの基本圧縮サイズは128x128マスとなります。
「リファイン用U-Net」が追加された
上にあるSDXLの図をもういちど見てみましょう。U-Netが2つあります。
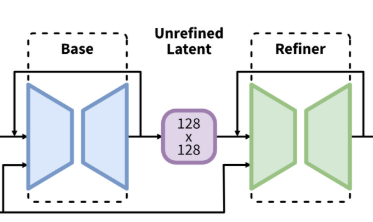
「Base」と書かれているものは本体のU-Netです。これに加えて「Refiner」というU-Netが増えています。このU-Netは実質「img-to-img」用に特別にチューニングされたU-Netです。Baseで出てきた画像をさらにきれいにするために、細かい部分も微調整するのが主な働きです。どちらも画像を「圧縮」状態で扱います。
ただ、リファイン用U-NetはSDXLに必須の機能ではありません。用意はされていますが、使わなくても構わないのです。実際これを使うと処理時間が2倍かかるので、「微調整なんかいらないから画像を速く生成したい」という人はこのモジュールをスキップすることができます。
Stable Diffusion XLのクオリティは?
メジャーなバージョンアップなので当然生成画像の劇的なクオリティ向上を期待したいところなのですが、実際はどうでしょう?
私は試していないのでこの点については何とも言えませんが、生成メカニズムを見る限り「確実に画質は上がるけど驚愕すべきほどではないかもしれない」という印象です。
高解像度画像を生成するときの破綻は減るかもしれません。学習画像がいろいろな解像度に対応したので、構図のクオリティ向上には貢献すると思います。ただ、これらの機能は現バージョンでもLoRAなど追加学習で一部対応可能です。
プロンプト解釈が賢くなった、という宣伝文句ですが、確かにテキストエンコーダーが賢くなったので、プロンプト理解も賢くなったかもしれません。より短いプロンプトで思い通りの絵を描けるようになる、という効果は確かにあると思います。
「リファイン用U-Net」ですが、Stable Diffusion WebUIには「Highres Fix」や「img-to-img」という機能があり、実質的にはリファインU-Netと同じような事をしているので、すでにその恩恵を受けていた人は多いかもしれません。
Stable Diffusionはバージョン1のころから有志のユーザーたちがいろいろな工夫を凝らして画像品質を上げてきましたが、それらの工夫を公式が改良し取り入れ、まとめ上げた感じ、というのがXLに対する私の印象です。
バージョン2やXLは確かにすごいんですが、バージョン1が登場時点ですでにすごすぎたんでしょうね。
まとめ
今回はStable Diffusionの最新版であるSDXLの機能の概要を紹介しました。
様々な工夫を凝らして画像品質の向上を図っていますが、ほとんどは既存の機能の拡張という感じです。U-Netがもう1つ増えましたが、これはSDXLの特徴を決定づけるほどの大きなインパクトを持っているわけではありません。
学習解像度は向上しているので、今後の主力はSDXLに少しずつ移行していくのかもしれません。しかしバージョン1系のStable Diffusionもまだまだ現役でバリバリ働いていくんだろうな、という印象を持ちました。
誰でもわかるStable Diffusion コントロールネット
またリクエストいただいたので今回はコントロールネットについて見てみましょう。
- コントロールネットとは
- U-Netのしくみをおさらい
- コントロールネットのはたらき
- コントロールネットのU-Net
- コントロールネットの入力って?
- コントロールネットのU-Netを実際に使うには
- まとめ
コントロールネットとは
コントロールネットは「絵の構図」に特化した追加学習モデルです。ただ、絵の構図をプロンプトで指定するのでなく、「棒人間のポーズ」や「深度画像」といった画像データで指定するのが大きな特徴です。
「画像データで描きたいものを指定できるの?」と疑問に思われるかもしれませんが、可能です。指定方法がテキストプロンプトであっても画像データであっても、数字の列に変換されてしまえばどちらもStable Diffusionにとっては同じようなものです*1。
追加学習といえば「Dreambooth」とか「LoRA」とかいろいろありますが、コントロールネットはそれらに比べて規模の大きい追加学習と言えるでしょう。
Stable Diffusionで絵を描くとき、「U-Net」というメカニズムが使われます。コントロールネットを使用すると、U-Netがもう一つ追加されます。そのため、コントロールネットを理解するにはU-Netの仕組みを知っておく必要があります。次の項でU-Netの構造について軽く解説し、そのあとでコントロールネットの説明をします。
U-Netは以前の記事でも説明していますので詳細はそちらをご覧ください。
U-Netのしくみをおさらい
U-Netは大まかに25個のブロックからできています。25個のブロックは数珠つなぎのように繋がっていて、データを第1ブロックに入れるとそのデータは次々とブロックを渡り歩いていき、最後は第25ブロックから出てきます。ブロック間を渡り歩く間にデータは次々と処理されていきます。
この25個のブロック3つのグループに分けることができて、第1ブロックから第12ブロックまでを「エンコーダーブロック」、第13ブロックを「ミドルブロック」、第14ブロックから第25ブロックまでを「デコーダーブロック」と呼びます。
簡単のため、それぞれ「エンコーダー」「ミドル」「デコーダー」と呼ぶことにします*2。
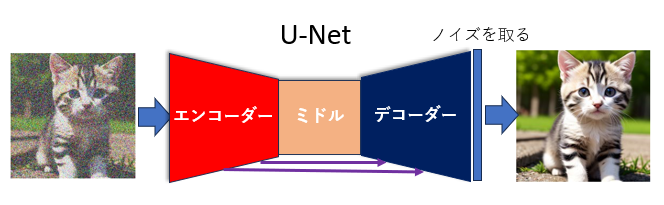
紫の細い矢印はスキップコネクション
それぞれのグループの働きを見てみましょう。
事前準備
以下の解説では、512x512ピクセルの画像を描くときの処理を例にして説明します。
最初に適当な砂嵐のような「ノイズ画像」を用意して、ここから完成絵まで画像を少しずつ変化させていきます。
さて、この画像はまずは64x64マスに「圧縮」されます。圧縮する方が計算量が少なくてすむからです。
エンコーダー
エンコーダーは、画像を小さくしながら画像の持つ特徴を取り出していくパートです。エンコーダーの最初のブロックである第1ブロックは64x64マスの画像データを受け取り、画像を作るための「処理」をします。これをバケツリレーのように第2ブロック、第3ブロック……と渡していきますが、画像がブロックを通るにつれて画像がさらに「圧縮」されて小さくなっていきます。第12ブロックを出るころには、画像サイズは8x8マスまで縮んでいます。縮んでいる間にも少しずつ完成に向かって画像を変化させているのですが、なぜ画像を縮める必要があるのでしょう?
それは、画像が「部分ごと」に処理されるからです。3x3マスをひとつのかたまりとして、このかたまりごとに特徴を取り出していきます。64x64マスの中の3x3マスといえば、全体のほんの一部分でしかありません。もしこれが絵だったら、この3x3マスではとても全体像を捉えられません。ネコの絵だったら、3x3に収まるのはせいぜい目とか耳とか毛くらいでしょう。
しかし、よりプロンプトに忠実な絵を描くためには、例えば背景とか、ネコがどんなポーズをしているかとか、全体像を処理する必要もあります。そこで画像を縮小するのです。最終的には8x8マスまで縮むので、3x3マスのかたまりでも十分全体を捉えることができます。
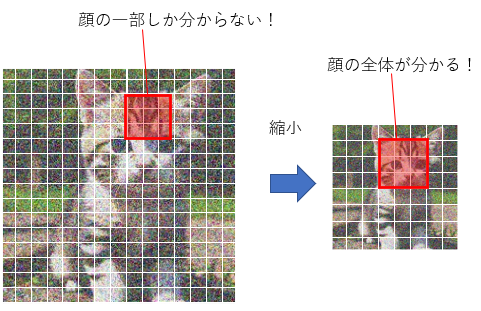
ミドル
ミドルでは、画像が最小の8x8マスになっていますが、画像の特徴が2560個も取り出されています。この画像サイズのまま、さらに特徴を抽出し、またプロンプトの情報も組み込みます。
デコーダー
デコーダーでは、今まで抽出した特徴をまとめていき、小さくなっている画像を拡大して元の大きさに戻していきます。ここでもプロンプト情報の取り込みは行われますが、重要なのは「画像が大きくなるにしたがって特徴量が減っていく」という点です。エンコーダーやミドルで抽出した特徴たちをまとめて画像内の情報をとらえ、それをもとに構築した新たな情報を画像に反映させていくのがデコーダーブロックの働きといえるでしょう。
さて、デコーダー内のブロックたちもエンコーダーやミドルと同じように、処理された画像を前のブロックから受け取り、自分のブロックで処理し、次のブロックに渡していきます。しかし、デコーダーのブロックたちはそのほかにエンコーダーのブロックから「直接」情報を受け取っています。
例えば、デコーダー内の最初のブロックである第14ブロックは、エンコーダー内の最後のブロックである第12ブロックから「直接」画像データを受け取っています。
この、デコーダーブロックがエンコーダーブロックから画像データを受け取る仕組みを「スキップコネクション」といいます。
U-Netで処理している間も画像はどんどん内容が変わっていくので、バケツリレー方式でデータを受け渡していると後になるにしたがって最初の方の情報が消えていってしまいます。これを防ぐため、画像の最初の方の情報を後ろの方のブロック(つまりデコーダー)に伝える仕組みがスキップコネクションです。
この「スキップコネクション」はコントロールネットで大きな役割を果たすので、覚えておいてください。
コントロールネットのはたらき
では、コントロールネットを追加してみましょう。
コントロールネットをオンにすると、U-Netによく似たモジュールがもう一つ現れます。
コントロールネットのU-Net
以下の図はコントロールネットの論文に載っている図です。左の方の灰色のブロックたちはStable Diffusion本体のU-Netを表しています。右の方の水色のブロックたちはコントロールネットで新たに追加されるU-Netです。

左はStable Diffusion本体のU-Net、右はコントロールネットのU-Net
デコーダーの構造がちょっと違う
Stable Diffusion本体のU-Net(本体U-Netと呼ぶことにします)と違って、コントロールネットのU-Net(コントロールU-Netと呼ぶことにします)では、デコーダー内のブロックは画像処理を行わず、データを次のブロックに渡すこともしません。その代わり、デコーダーブロックは「データを出力する」という機能を持っています。
通常のU-Netはデータ出力は一か所だけ、最終ブロックである第25ブロックだけがデータを出力します(上の図、左下の「Output」が出力です)。残りのブロックは処理したデータを次のブロックに渡すだけなので、U-Netの外に出力はされません。
ところが、コントロールU-Netはミドルとデコーダーのブロックがそれぞれデータを出力します。出力したデータはどこに行くのかというと、本体U-Netの中の対応するブロックに突っ込まれます(上の図の右から左に向かう水色の矢印)。
例えばコントロールU-Netの第14ブロック(デコーダーの最初のブロック)が出力したデータは、本体U-Netの第14ブロックに入力されます。
ゼロ畳み込み
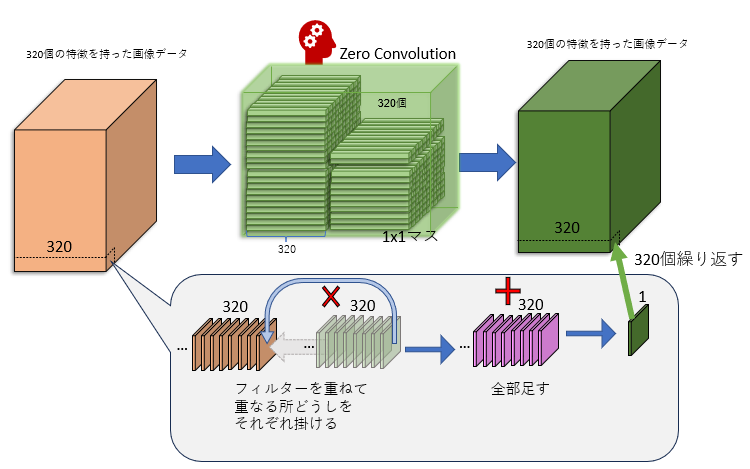
コントロールU-Netのデコーダーは本体U-Netと同じく12個のブロックからなっていますが、これらのブロックはすべて「ゼロ畳み込み」(zero convolution)というモジュールに置き換わっています。
「ゼロ畳み込み」は何も難しいことはしていません。「ゼロ」と名付けられてはいますが、やっていることは「1x1マスの畳み込み」です*3。
「1x1マスの畳み込み」とは、各マスごとに、特徴をいろんなパターンで混ぜてみる、という作業です。例えば1つのマスが320個の特徴を持っているとすると、マス内の320個の特徴を「ある値」で掛けて、(そして別の「ある値」を足して)、全部足す、ということを320パターン繰り返します。パターンごとに「ある値」は変わります。
畳み込みの結果、データの内容は変わります。しかし画像サイズは変わりません。320個の特徴は相変わらず320個の特徴のままです(320パターン計算したので)。
ゼロ畳み込みは本体U-NetにないコントロールU-Net独特のもので、この部分が棒人間画像などの構図データを学習(後述)します。本体U-Netのモデルからコピーして使っているだけのエンコーダーやミドルは学習しても全く変化しないので、ゼロ畳み込みモジュールこそがコントロールネットの「賢くなる部分」です。
ゼロ畳み込みを通った画像データは本体U-Netに送られます。
「スキップコネクション」が重要
コントロールU-Netのデコーダーブロックは隣のブロックにデータを送らない、ということを上で説明しましたが、例えばもし第14ブロックが次のブロックにデータを送らないなら、第15ブロックはどこからデータを受け取るのでしょう?
それが上でも説明した「スキップコネクション」です。コントロールU-Netのデコーダーブロックは、エンコーダーブロックから「直接」データを受け取っています(上の図の上から下に向かう水色の矢印)E。
つまりデコーダーブロックが出力しているデータは、エンコーダーブロックが処理したデータ(を少し変換したもの)なのです。
本体のU-Netに情報提供
さて、本体U-Netのデコーダーブロックは、「本体U-Net内のブロック」と「コントロールU-Netのデコーダーブロック」からそれぞれ同じサイズのデータを受け取ります。
入力された2つのデータは、足しあわされて混ざります。
つまりコントロールネットとは、絵を並行して2枚作り、生成中の2枚の絵をそのつど混ぜ合わせていく、というプロセスです。力関係としては本体U-Netの影響の方がコントロールU-Netよりも強力なので、完成した絵もそちらの影響の方が強く出ますが、コントロールU-Netに入力された「構図」情報も完成絵によく反映されます。
コントロールネットの入力って?
上の図の「入力」部分をちょっと拡大してみてみましょう。

コントロールネットを使う場合、3つのデータが入力されます。
- 画像データ(Input)
- プロンプト(Prompt)
- 構図データ(Condition)
画像データ入力
左の本体U-Netには「Input」というものが入力されています。これは「処理前の画像データ」です。上でも説明したように、最初は砂嵐のような画像を用意してInputとして本体U-Netに突っ込みます。砂嵐はU-Netを1回通るとちょっとノイズの減った画像になります。その画像をまたInputとして同じ本体U-Netに突っ込みます。これを指定ステップ数繰り返して、絵を生成していきます。
プロンプト入力
本体U-Netには、「プロンプト」も入力されています。これはユーザーが指定するテキストです。「Cat」とか「Dog」とか、描いてほしいものをテキストとして入力するとU-Netがそれを翻訳して、指定された絵を描いてくれます。
構図データ入力
図の右側のコントロールU-Netには「Condition」というものが入力されていますが、これは「絵の構図」を指定するデータです。ここでいう「構図」とは、例えば棒人間だったり、深度情報だったり、輪郭だったり、かなり抽象的な画像です。
他にも「処理前の画像データ」のコピーがコントロールU-Netに送られます(「Input」から伸びている矢印)。
構図と画像データコピーは、コントロールU-Netに入る前に統合されます。
(上の図では統合される前に構図画像が「zero convolution」を通っていますが、これは構図画像の透明度を調整するものだと思ってください)
なお、コントロールU-Netにも「プロンプト」が入力されます。
つまり本体U-NetとコントロールU-Netは、(少なくともエンコーダーは)同じような生成処理を並行して行っているのです。ただ、両者の入力画像データは微妙に違って、コントロールU-Netに突っ込まれる画像には構図情報もぼんやりと入っています。例えば構図が棒人間の場合、入力画像データにうっすらと棒人間が映っています。
コントロールU-Netはこの入力された棒人間入りの画像データを見て、「おっ、人間っぽいのがいるな」という感じで構図に沿った特徴を拾っていきます。この情報は本体U-Netに送られ、「人間っぽいのがいるぞ」と本体U-Netに教えます。すると本体U-Net(のデコーダーブロック)はその情報をもとに絵を仕上げるので、結果的に構図情報が反映された絵になっていきます。
絵から構図への変換はおまけ機能
上で解説した通り、コントロールネットは「構図情報」を受け取って処理します。
そのため、コントロールU-Netを使うには構図画像データを事前に用意する必要があります。「用意」とは、例えば人の映っている写真を棒人間の画像に変換したり、輪郭だけの画像に変換したり、といった処理です。

だいたい一緒に使うので付属機能みたいなもんです
ここで注意すべきなのは、構図画像への変換はコントロールネットの機能ではない、ということです。構図変換はあくまで「コントロールネットに入力する構図を用意するための前処理」です。
ただ、Stable Diffusion WebUIなどのアプリでは構図情報への変換もコントロールネットと一緒に提供されるので、まあ変換処理もコントロールネットの「付属機能」といっても差し支えないかもしれません。
Stable Diffusion WebUIでは、「Preprocessor」というリストから「どのタイプの構図画像に変換したいか」を選ぶことができます。

コントロールネットのU-Netを実際に使うには
さて、コントロールU-Netはもちろん最初から棒人間を「人間」だと知っているわけではありません。事前にそういう風に学習させたので「人間」として認識するだけで、「輪郭」しか知らないコントロールU-Netに棒人間画像を見せても「人間」とは思ってくれません。
そういうわけで、それぞれの「構図情報」に特化したコントロールU-Netを個別に用意する必要があります。「棒人間専用U-Net」とか「輪郭専用U-Net」という具合です。
Stable Diffusion WebUIでは、「Model」リストからモデル(つまりU-Net)を選択できますが、使用モデルは構図画像のタイプに合わせる必要があります。

合わせる必要があります
Stable Diffusion WebUIにはコントロールネットのモデル(コントロールU-Net)は付属していませんので、初期状態ではコントロールネットのモデルは空っぽです。
使いたいモデルがリストにない場合はダウンロードする必要があります。
さて、コントロールネットを使いたいなら「学習済み」のモデルをダウンロードしてきて使えばいいわけですが、もしモデルを自分で作りたい場合は(そんな人はあまりいないでしょうが)、モデルを学習して作る必要があります。
それぞれのU-Netは以下のような学習を行って構図情報の意味を勉強します。
- 元となるモデル(本体U-Net)を用意して、それをコピーし、コピーを元にコントロールU-Netを作る。
- テキスト付き画像を用意する。
- 画像を学習対象(「ポーズ」とか「深度」など)の「構図情報」に変換し、それをコントロールU-Netに入力する。
- 本体U-NetとコントロールU-Netを使って絵を生成する。プロンプトをもとに絵を生成することもあれば、プロンプトを完全に無視することもある。
- 絵が完成する。この絵を元のと比べて、なるべく似るようにコントロールU-Netの「ゼロ畳み込み」部分を修正する。
こうしてできたコントロールU-Netは、たとえば「棒人間専用コントロールネット」とか「深度専用コントロールネット」という感じで、別々に配布されます。
コントロールU-Netは本体U-Netと構造が違うとはいえ、U-Netであることに変わりはないので、ファイルサイズも通常は5ギガバイトを超えるほど大きいものになります。
まとめ
今回はコントロールネットについて解説しました。コントロールネットは追加学習の一種ですがそのパワフルさから多くのStable diffusionウェブアプリで標準搭載されるようになっています。
コントロールネットを使うと2つのU-Netが並行して実行され、1つは通常の生成処理、もう1つは「構図情報」を使って生成処理を行い、処理途中に何度も2枚の画像をミックスしながら1枚の画像を完成させます。そのため、両者の特徴が出た画像を作ることができます。
誰でもわかるStable Diffusion モデルから概念を消す(ESD、LECO)
最近、Stable Diffusionのモデルから特定の概念だけを消す、という面白いテクニックが提唱されたので見てみましょう。
オリジナルはこの論文のようです。論文の中で、このテクニックのことをErased Stable Diffusion(略してESD)と呼んでいます。
まずはESDが何なのかを見てみます。そして、ESDをLoRAによって実装したLECOという追加モデルについても軽く触れます。
なお、この記事を読む前に、「CFGスケール」の解説記事をお読みいただくことを強くお勧めします。CFGスケールについて理解しておくと、この記事もかなり分かりやすくなると思います。
Stable Diffusionが絵を描くしくみ
まず、Stable Diffusionのしくみについておさらいします。
Stable Diffusionは「しくみ」であって、これ自体が膨大な絵の知識を持っているわけではありません。OSの乗っていないパソコンのようなもので、「脳みそ」がないと何もできません。
その「脳みそ」はStable Diffusionでは俗に「モデル」と呼ばれます。モデルを読み込んで初めてStable Diffusionで絵を描けるようになります。
モデルを読み込んで、こちらから何も指示せずに絵を描かせてみると、何かを描いてくれるかもしれませんが、きっと意味の分からない絵になると思います。これを「無題の絵」と呼ぶことにします。

無題の絵では何の役にも立たないので、こんどは「cat」と指示して絵を描かせます。するとネコの絵が描かれるはずです。これを「お題の絵」と呼ぶことにします。「ネコ」という「お題」を出されたので、Stable Diffusionはネコの絵を描いたのです。
さて、Stable Diffusionで「絵を描く」とは、
 ⇒
⇒ 
砂嵐のようなカオスな絵を、人間が「美しい」と思う絵に変えていく作業です。
ちょっとずつ、それぞれのピクセルを変化させて、絵を完成させていくのです。
ここで仮に、この世の画像がすべて「2ピクセル」でできているとします。下の図の黒い2ピクセルを砂嵐の絵、右の灰色の2ピクセルをネコの絵だと思ってください。

Stable Diffusionで「絵を描く」ときは、まず適当に「砂嵐」(左の2ピクセル)を用意します。ちょっとずつピクセルの色を変えていき、最終的にゴールの絵に近づけます。それはあたかも地図上をちょっとずつ進んでいくようなものです。

「ネコの絵」の方向に進んでいくには、ナビゲーションが必要です。このナビゲーションこそユーザーが指定する「お題」、つまり「プロンプト」です。Stable Diffusionのモデルは「ネコ」がどの方向にあるのかだいたい知っているので、「あっちに行けばいいんだな」という感じでネコの絵の方向に近づいていきます。
ナビゲーションがないとどうなるでしょう?Stable Diffusionはとりあえずどこかの方向に進みたがります。しかし、そちらの行き先は「無題の絵」で、ほしい絵とは似ても似つかない絵なので、そっちには絶対に行かないようにしなければなりません。この「無題の絵から遠ざかりつつ、目標の絵にうまく導く」手法を「Classifier Free Guidance」(略してCFG)といいます。
CFGに関しては過去の記事を見ていただくとして、ここで重要なのは「お題が与えられたせいで無題のときと違う方向に向かった」という点です。つまり、「無題」と「お題」の差が現れます。これは重要なので覚えておいてください。

さて、ここまでが前提知識です。
いよいよ「概念消し」であるESDについて見ていきましょう。
ESDとは
日本語にすると「消去されたStable Diffusion」です。何というか、あいまいな名前ですすが、その手法を提案した論文に以下のような図があります。

この図の右側にある2つの(砂嵐みたいな)絵は、上で説明した「無題の絵」と「お題の絵」の2つを表しています*1。そして、真ん中の数式で「無題とお題の差」を計算しています。
左の黄緑色のモジュールが、ESDで新たに追加される部分です。これは何をしているかというと、「無題とお題の差を打ち消すような何か」を吐き出しています。
「無題とお題の差」を打ち消すと、どうなるでしょう?
「お題」が「無題」と変わらなくなってしまいます。すると、「お題の絵」の方向に進まず、「無題の絵」のほうに進んでしまうのです。そうすると、最終的には「無題の絵」のほうに近寄っていきます。つまり、「お題」というナビゲーションを完全無視する、ということになります。
これは「『お題』を忘れ去ってしまう」ということに他なりません。
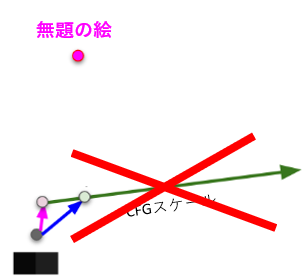
それがESD
LECOは概念を消し去るLoRA
要するにESDは「特定のお題(トークン)が画像を作ろうとする力」を打ち消しているだけで、考えてみれば単純な事なのですが、実現するためにはその打ち消す力をモデルに追加してやらなければいけません。
オリジナルモデルにその力を組み込むこともできますが、そうするとその組み込んだ後のモデルを丸々配布しないといけなくなります。モデルは小さくても2ギガバイト以上あるので、配布は大変です。
そこで、概念を打ち消す力を持つ小さなニューラルネットを別に作って、それを配布する手法が提案されました。それが「LECO」です。
上で紹介した論文の図の黄緑色のモジュールにあたります。
LECOについては以下のサイトで詳しく説明されているのでご覧ください。
小さなニューラルネットを追加する手法は「LoRA」と同じです(今回の記事ではUNet内のどの部分に適応されているか、などの説明は省略します)。
通常のLoRAは新たな概念を追加するために使われますが、LECOはその逆で、負の概念(打ち消す力)を追加するために使われます。
まとめ
今回はモデルから概念を消すESDとLECOを軽く解説しました。
Stable Diffusionは概念を追加して新たな絵を描かせることができますが、ESDによって「特定の概念を描かせない」という応用例も登場しました。
単純なようでいてなかなか思いつかない手法ですが、こういうたくさんの応用例が出てくるとAIお絵描きの幅もどんどん広がっていくのでしょうね。
*1:正確に言うと「「無題の絵」と「お題の絵」に乗っているであろうノイズ」です。
誰でもわかるStable Diffusion リージョナルプロンプト
コメントでリクエストをいただいたので今回はStable Diffusion WebUIの拡張機能として提供されている「リージョナルプロンプト」について解説します。
(リクエスト引き続きお待ちしてます)
※このブログを読まれている方はもうご存じだと思いますが、この記事は「いい絵を生成する方法」は解説していません。あくまで「しくみ」の解説であることをご了承ください。
リージョナルプロンプトとは
Stable Diffusionに絵を描かせるとき、どんな絵を描きたいかを英語のテキストで指定します。このテキストの事を「プロンプト」と呼びます。
最近はプロンプトの書き方も研究が進んで、プロンプト技法をうまく使えば自分のイメージにかなり近い絵を描くことができます。
しかし、デフォルトのプロンプトではどうしてもうまく描けない構図があります。それは「複数のコンセプトを別々に描く」構図です。
例えば2匹の猫を描きたいとします。
2 cats
とプロンプトに書けばたいてい2匹のネコが描かれます。
しかし、この2匹のネコの特徴をそれぞれ指定したらどうなるでしょう?
「寝ている白ネコ、歩いている黒ネコ」と入力してみます。
sleeping white cat and walking black cat

なかなか思い通りの絵が出てきません。人間が読めば「白いネコは寝ていて、黒いネコは歩いている」と分かるのですが、Stable Diffusionはこういう「共通するコンセプト」を混ぜてしまいがちです。
Stable Diffusionでは「テキストエンコーダー」というプロンプト翻訳機能が使われます。テキストエンコーダーは本来、英語の文脈や文法も考慮してプロンプトを解読するので、上記のような単純なプロンプトは難なく翻訳してくれるはずなのですが、実際に出来上がった絵を見ると、その翻訳をうまく理解できていません。プロンプトが長くなるとどんどん文脈が複雑になるので、より思い通りの絵を描かせるのが難しくなってきます。
もちろん、プロンプトの文法を正しく書けばテキストエンコーダーがより正しく翻訳してくれる可能性は高くなります。しかし、Stable Diffusionの「混ぜ癖」はそれだけでは解決しません。
そこで提案されたのが「リージョナルプロンプト」です。
「リージョナルプロンプト」とは、要するに画像を区切ることです。
弁当箱をイメージしてください。区切りのない弁当箱にごはんやいろいろなおかずを詰め込んだら、全部混ざってしまいます。汁が出るおかずやソースのかかったおかずがあったら大変です。
弁当を1枚の絵とすると、混ざるプロンプトとは、弁当内の汁やソースに相当します。これらが混ざらないようにするために、仕切りを作って別々の区切りに別々のおかずを入れます。
リージョナルプロンプトも弁当と同じように「左はSleeping cat、右はWalking cat」というふうに区切りを作ってそれぞれの区切りごとに別のプロンプトを指定します。
「つまり、別々の画像を作ってくっつけてるだけ?」と思われたかもしれません。
その通りです。
しかし、ただ単純にくっつけただけではツギハギだらけの美しくない絵になってしまうので、「別々の画像を作る」手法と「くっつける」手法にちょっと工夫が必要です。
リージョナルプロンプトのはたらき
※注意
以下の説明は「Stable DiffusionのU-Netが『画像』を生成している」という体で解説をしています。実際はU-Netが生成しているのは「画像に乗っているであろうノイズ」です。何を言っているのか分からない方は気にしなくても結構です。
リージョナルプロンプトでは、画像を細かく切り分け、その区画ごとに違うプロンプトを指定します。ここまでは共通ですが、「画像の別々の区画に別々のプロンプトをどう取り込むか」の手法が2つあります。「Latent Couple」と「Attention Couple」です。
Latent Couple
Latent Coupleは単純です。要するに画像のそれぞれの区画ごとに画像を別々に作ります。これだけ聞くと複数画像をくっつけているだけのように思われるかもしれませんが、Latent Coupleの場合はもうちょっと手の込んだ2つの特徴があります。
- 背景画像も作れる
- 圧縮状態の画像を統合する
例えば2枚の別の画像があるとします。Latent Coupleでは、この2枚のほかにもう1枚「背景画像」を作ることができます(作らないこともできます)。以下、背景画像を作る場合の説明をします。
画像編集ソフトを思い浮かべると分かりやすいと思います。まず背景レイヤーに「2匹のネコ」と名前を付けます(レイヤー名がプロンプトに相当します)。この背景レイヤーに軽く下描きをして、どの辺にどういうネコがいるか、おおまかな構図を決めます。次に、背景レイヤーの上に同じ画像サイズの新たなレイヤーを2枚作り、1枚は左側に白ネコの絵を、もう1枚は右側に黒ネコの絵を描きます。2枚のネコ絵レイヤーは、それぞれ描画範囲が重ならないようにします。最後にレイヤーを統合すれば完成です。
別々の絵も背景に馴染ませればそれなりにキレイに見えるんじゃないか、というアイデアです。

2つ目の特徴は、完成したピクセル画像をくっつけるのでなく、圧縮状態(つまりLatentスペース)の画像をくっつけることです。
画像内のそれぞれの区画はレイヤーごとに別々に仕上げていくわけですが、それぞれのレイヤーを圧縮された状態のまま統合します。これによって、完成画像をくっつけるよりもより滑らかに画像統合できることが期待されます。
Latent Coupleを使って描いた画像は、それぞれの区画に指定プロンプトが詳細に反映されます。それぞれの区画が独立して描かれているので当然と言えば当然ですが、特定プロンプトで指定したものを他のプロンプトと混ざることなくかなりきっちり描いてくれます。
半面、Latent Coupleは処理が重くなります。
例えば3つのパートに画像を分けたとき、3枚の画像+背景画像1枚+ネガティブプロンプト画像1枚の計5枚の画像を別々に書く必要があり、結果的に1枚の画像を描くよりも5倍の処理が必要です。たとえ右半分に何もない左半分だけの絵でも、Stable Diffusionは何もない部分に「何もないようにする」という「処理」を行うので、結局1枚絵を描くのと変わらない労力が必要です。
なお、「バッチ処理」という手法によって5枚を並行して1度に描くので、5倍時間がかかるというわけではありません。それでも処理が重いので時間は多めにかかるでしょう。
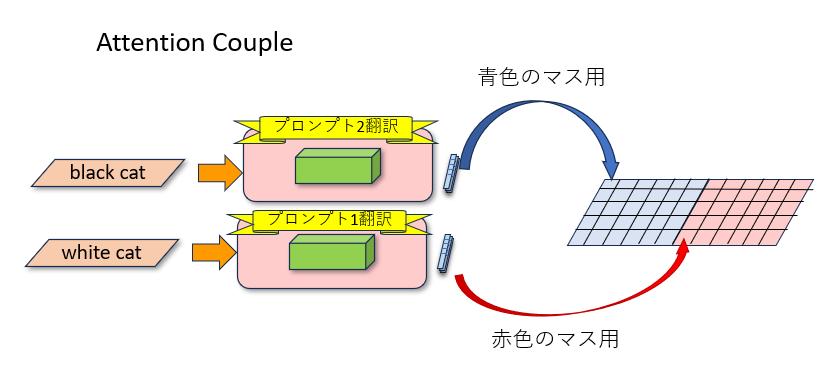
Attention Couple
Attention CoupleはLatent Coupleの改良系として提案されました。
Latent Coupleの違いは、それぞれの区画を別々の画像として描かず、最初から1枚の画像として描く点です。このため、Latent Coupleのようにそれぞれの区画に1枚絵と同等の時間をかける必要がなく、1枚分の絵を描く処理ですべての区画を描いてくれます。
画像編集ソフトの例でいえば、Latent Coupleが「レイヤー分け」なら、Attention Coupleは「レイヤー分けせず範囲選択して描く」という感じです。
最初から1枚絵として描くので、画像内で整合性のとれた(つまりツギハギの目立たない)絵になることが期待できます。
その反面、それぞれの区画のプロンプトがあまりはっきり反映されない「ぼやけた」画像になる可能性もあります。これは、Stable Diffusionの心臓部である「U-Net」というしくみが、画像の拡大、縮小を繰り返しながら絵を描いていくからです。画像を縮小してしまうとそれぞれの区画が小さくなりすぎてほとんど区別がつかなくなってしまうのです。極端な例では区画が1マスまで縮んでしまいます。その1マス中に特定プロンプトを詰め込むのは非常に大変です。
Attention Coupleのしくみは「Attention」のしくみを知っていると分かりやすいので、以下に軽く解説します。そこまで興味がない方は読み飛ばしてください。
プロンプトが画像になるしくみをおさらい
※このセクションはちょっと複雑なので、リージョナルプロンプトについて軽く知りたいだけならここは読み飛ばしてください。
Stable Diffusionはどうやってプロンプトを画像に変換しているのでしょう?
変換するうえでとても大きな役割を果たしているのが「テキストエンコーダー」と「Attention」です。
これについては以前の記事で詳しく解説しているのでそちらもご覧ください。
ここでは概要を説明します。
Stable Diffusionがプロンプトから画像を作るしくみは、おおまかに2つのパートから成り立っています。
- プロンプトを数字に変換する「テキストエンコーダー」
- 数字になったプロンプトを画像に取り込む「Attentionブロック」
テキストエンコーダーの仕事
プロンプトとは、人間が読めるテキストです。Stable Diffusionはテキストが読めず、数字しか読めません。そこで「テキストエンコーダー」がプロンプトを数字の列に変換します。
まず、プロンプトのそれぞれの単語を、さらに細かい単語に切り分けます。切り分けられた後の小さな単語を「トークン」と呼びます。トークンになって初めて、テキストエンコーダーがその意味を理解できるようになります。
例えば「xformers」という単語は短いにもかかわらず「x」「form」「ers」の3トークンに切り分けられます。
もちろん単語がいつも切り分けられるわけではありません。「cat」という単語はもうこれ以上切り分けられないのでそのままです。
次に、それぞれのトークンを768個の数字列(ベクトルと言います)に変換します。「x」だろうと「cat」だろうと、トークンの長さに関係なくすべて必ず768個の数字になります。テキストエンコーダーはかなり賢く、単語の順番、重要度、意味などをすべて考慮して、それらをすべて含んだ最適な数字の列をそれぞれのトークンに対して作り出します。
人間の側としては「ただの数字列にそんないろいろな情報を詰め込めるの?」と感じてしまいますが、Stable Diffusionにとってはその数字列こそが情報の宝庫なのです。

さて、ここからが重要ですが、テキストエンコーダーはそれぞれのトークンから768個の数字列を3つ作るのです。
3つのベクトルにはそれぞれ名前がついていて、「Q」「K」「V」と呼ばれます。
※Qは「クエリ(Query)」の略、Kは「キー(Key)」の略、Vは「値(Value)」の略です。
この3つのベクトルはそれぞれまったく違う数字が入っていますが、3つとも完全にリンクしています。
そして、この3つの中で一番重要なのは「V」です。Vはまさに「トークンに対応する画像データ」なのです。
Attentionブロックの仕事
Stable Diffusionには「Attentionブロック」というモジュールが16個も使われています。たくさんありますが、どれも働きはだいたい同じです。画像生成では1ステップごとにこの16個のモジュールが順に実行されて、だんだん絵ができてきます。
Attentionブロックには以下の2つの情報が入力されます。
上でも説明したように、トークンはそれぞれQ、K、Vベクトルになっています。これを画像に取り込みたいのですが、そのためにAttentionブロックは生成途中の画像もそれぞれのマスごとにQ、K、Vの3つのデータに分裂させます。
つまり、Attentionブロックでは「トークンのQ、K、V」と「画像のQ、K、V」の合計6つのデータが現れるのです!しかし、これらを全部使うわけではありません。使うのは「トークンのK、V」と「画像のQ」の3つだけです。
さて、トークンの情報を画像に取り込みます。
トークンのKとVはガッチリとペアになっています。Kは箱に貼ってあるラベルのような役割を果たし、Vは箱の中身です。画像のQは「ほしいものリスト」のようなものです。つまり、画像のそれぞれのマスが「こんなトークン欲しいな」というリストを持っているわけです。
トークンはプロンプトごとに「トークン集」として1まとめで扱われます。いわばカタログです。
それぞれのマスはトークン集のK(ラベル)を見て、自分のQ(ほしいものリスト)と比べます。ほしいラベルが見つかったら、その本体であるVを取り込みます。そうして、画像のそれぞれのマスがトークンのVに染まります。もともと画像のマス自体も自分の「V」を持っていたのですが、トークンのVを取り込んだ後は元のVは完全に捨てられます。
Attentionブロックの処理によって、作っている途中の画像データは、トークンたちが持ってきたVのデータに完全に置き換わってしまうのです。
ちなみに、この一連の処理を「Cross Attention」と呼びます。
画像のそれぞれのマスすべてがこの処理を行っている、ということを覚えておいてください。
Attention CoupleでK、Qをすり替え
Attention Coupleの話に戻ります。
上で説明した通り、画像内のそれぞれのマスすべてがトークン集のK、Vを見るなら、それぞれのマスの場所ごとに違うトークン集を渡せば、違うプロンプトを違う場所に反映できます。トークン集(つまりプロンプト)がカタログなら、「この区画にはカタログ1を渡し、別の区画にはカタログ2を渡す」という感じです。
例えばプロンプトが左右2つ用意されたとします。それぞれのプロンプトからKとVのカタログが作られます(この処理は1回だけでオッケーです)。この2つのペア、「K左、V左」カタログと「K右、V右」カタログをAttentionブロックに渡します。すると作りかけの画像内のそれぞれのマスがカタログを見に来ますが、左側にあるマスは「K左、V左」カタログを、右側にあるマスは「K右、V右」カタログを見るようにします。
区画ごとに別々に1枚絵を描く必要がないのは、区画ごとに反映させるプロンプトを変えているからです。
どっちがいいの?
結局は用途によるところが大きいですが、継ぎ目が多少ぎこちなくてもちゃんとプロンプトどおりに詳細を描きたいならLatent Couple、より自然に見える絵を描きたいならAttention Coupleという感じです。別々の場所に別の個体を描きたいなら継ぎ目はあまり気にする必要はないでしょうが、たとえば「上半身」「下半身」というように同じ物体を区切りたいなら滑らかな継ぎ目も考慮する必要があるかもしれません。また、スピードは断然Attention Coupleの方が速いので、速度を気にされる方はAttention Coupleを選びましょう。
どちらを選んだとしてもStable Diffusionはなるべく矛盾のない絵を描こうと努力してくれますので、別々の絵をくっつけただけの画像よりもはるかによい結果を得られます。
まとめ
今回はリージョナルプロンプトについて解説しました。
Stable Diffusionで大きなサイズの画像を描こうとすると、構図や物体、人物の構造が破綻してしまう可能性が高くなります。これは、学習画像よりも大きな画像を描こうとすると、構造の繰り返し、いわゆる「カスケード」が起きてしまうからです。
リージョナルプロンプトを使うと、画像を小さく区切って区画ごとに描けるので、より破綻のない、思い通りの構図の絵が描けるようになります。ぜひ試してみましょう。
誰でもわかるStable Diffusion スケジューラー
Stable Diffusionで絵を生成するとき、まずノイズだらけの砂嵐のような画像が用意されます。ここから少しずつノイズを取り除いて希望の絵を浮かび上がらせていく、というのが画像生成の仕組みです。
さて、「少しずつノイズを取り除く」というとき、この「少しずつ」とはいったいどれくらいなのでしょう?それを決めるのが「サンプラー」といわれるものです。
今回はこの「サンプラー」について大まかに解説します。
なおこの記事は、各サンプラーの比較や、各サンプラーがどんな画像が生成するかといった実用的な話ではありません。あくまで「サンプラーが何か」を知るための解説です。
Diffusionモデルをおさらい
Stable Diffusionでは「Diffusionモデル」と呼ばれる手法が使われていますが、その仕組みを大まかに知っている必要があります。
※実際は「Latent Diffusion」という、画像を圧縮してから処理する手法ですが、この解説では簡単のため画像を圧縮せずに処理することにします。
まずは画像を学習
Diffusionモデルはまず「学習」によって大量の画像の特徴を記憶します。何十億枚という画像からたくさんの特徴を取り出し、それらをニューラルネットに取り込みます。
しかし、学習に使う画像をそのまま突っ込めばいいというわけではありません。

何をどう学習しているのでしょう?
- まず、学習用の画像「正解画像」を用意します。Diffusionモデルにはこの「正解画像」を描けるようになってもらいたいのです。
- 次にこの「正解画像」に少しだけノイズを乗せます。すると「正解画像」が少しザラザラした見た目になります。
- 2の「少しだけノイズを乗せる作業」をランダムな回数繰り返します(後述)。どんどんノイズが重なって、どんどん画像がザラザラになっていきます。ここで乗せたすべてのノイズを「追加ノイズ」、出来上がったザラザラの画像を「汚い画像」とします。
- この「汚い画像」をDiffusionモデルで使うニューラルネット(いわゆるAI)に入力します。するとニューラルネットはいろいろな処理をして最終的に「正解画像に乗っているであろう追加ノイズ」を予想して吐き出します。これを「予測ノイズ」とします。
- もしニューラルネットが完璧に賢いなら「予測ノイズ」は実際に追加されたノイズと完璧に一致するはずです。その場合、「汚い画像」から「予測ノイズ」を引くと「正解画像」に正しく近づきます。しかし、実際はそんなに簡単ではありません。そこで、乗っているノイズのうちの「ほんのちょっとだけのノイズ」を予測します。
- 「予測ノイズ」と実際に乗っている「追加ノイズ」がなるべく一致するようにニューラルネットを少し賢くします。
- 「正解画像」を変えたり「追加ノイズ」の量を変えたりして、1~6の作業を膨大な量繰り返します。
この「ノイズを乗せた画像を学習する」という学習はDiffusionモデルのユニークなところです。
さて、学習の時に大切になるのが「ランダムな回数ノイズを乗せる」という処理です。Stable Diffusionの場合、このランダムな回数は1~1000回です。
この記事では、ノイズが1回だけ乗った画像を「1ノイズ画像」と呼ぶことにします。50回乗れば「50ノイズ画像」、100回乗れば「100ノイズ画像」という感じです。最大にノイズが乗った画像は「1000ノイズ画像」ということになります。
学習では1回の処理につき1ノイズ分の「予測ノイズ」を出力できるようにします。
画像が「1ノイズ画像」の時は、ノイズの量がほんの少し(1ノイズ分)なので、見た目は元の「正解画像」とあまり変わりません。ニューラルネットもきっと簡単に学習して、ノイズを予測できるようになるでしょう。しかしノイズの量が100、200と増えていくにつれてどんどん元の「正解画像」が不明瞭になっていきます。
「1000ノイズ画像」ではもはや元々何が描いてあったのか全く分からなくなってしまいます。こんな画像からいきなり1000ノイズ分を予測するのは不可能ですが、1ノイズ分ならなんとか予測できそうなので、がんばって学習してもらいます。

このニューラルネットのすごいところは、ノイズの量が変化しても単体でそれに対応できることです。ノイズ量に応じて違うニューラルネットを用意する、という必要がなく、このニューラルネットだけですべてのノイズ量に対応します。
※「ノイズってなんだ?」と思われるかもしれませんが、Stable Diffusionでいうところの「ノイズ」とは「ガウス雑音」と呼ばれる、単純な数式として表せるノイズです。ガウス雑音が選ばれたのは、これが計算で一番扱いやすいからです。ガウス雑音には「平均」と「分散」という2つのパラメータがあって、「平均」が0、「分散」が1に近づいていくにつれてノイズがどんどん多くなります。「ノイズを乗せる」とは、最初の絵にガウス雑音を少しずつ浸食させていき、最終的にガウス雑音によって絵を乗っ取ってしまおう、という処理です。
画像生成は学習の逆
十分な学習の後、今度は学んだことを生かして画像を描いてもらいます。
画像生成は冒頭でも少し説明しましたが、以下のような処理です。
- 最初にノイズだらけの画像を用意する。これは実質「1000ノイズ画像」とみなされる
- 与えられたプロンプトから「正解画像」を何となく予想する。例えば「cat」というプロンプトならネコの写っている絵を「正解画像」と予想する。
- 学んだことを生かし、「こういうノイズを取ればネコの絵になりそう」と予想し、「予測ノイズ」を作って出力する。
- 「ノイズ画像」から「予測ノイズ」を引く。するとノイズ画像から少しノイズが取り除かれる。例えば1000ノイズ画像だったのが999ノイズ画像になる、という感じ。
- 上の2~5の処理を「1ステップ」として、最終的に「0ノイズ画像」になるまでステップを繰り返してノイズをどんどん減らしていく。
- もし予測された「正解画像」が正しければ、「0ノイズ画像」=「理想の絵」となっているはず。
1000ノイズ画像からいきなり0ノイズ画像(つまり正解画像)にすることは不可能なので、少しずつノイズを引いていきます。

では、完成画像にたどり着くまでに1000回もノイズを予測しなければいけないのでしょうか?1枚の画像を作るのにいちいちそんな膨大な作業を行っていたら、時間がかかりすぎてとても使い物になりません。
そこで、1回の処理で1ノイズだけ引くのではなく、10とか20とか、ノイズをある程度まとめて引くことを考えます。最近の研究で、ノイズをある程度まとめて引いても結構うまく画像を作れることが分かってきました。
ここで「ある程度まとまったノイズ」がどれくらいなのか、そのノイズをどう作るのかを決めるのが「サンプラー」です。
サンプラーによって各ステップのノイズ量が変わります。例えばあるサンプラーは毎ステップ50ノイズずつノイズ量を減らすとします。すると950、900、850…とノイズ量が減っていきます。別のサンプラーでは最初は多めに、終盤は少なめにノイズを減らすかもしれません。その場合、920、840、……50、20、10というようなノイズの減り方になると思います。
取り除くノイズ量が変わると、「予測ノイズ」も変わり、それを引いた後の画像も変わってきます。つまり、ステップごとのノイズ量を管理するサンプラーは「予測ノイズ」に影響を与え、その結果、完成画像にも影響を与えます。
※専門的に言うと、サンプラーとは「微分方程式を解くための手法」です。詳しくは解説しませんが、Diffusionモデルのプロセスを数学的に眺めると、画像生成とは「確率微分方程式(SDE)」または「常微分方程式(ODE)」を解くことと同義であることが分かりました。そのため、Stable Diffusionではいろいろな微分方程式の解法をサンプラーとして使用しているのです。
Stable Diffusion Web UIのサンプラー
現在、PC上でStable Diffusionを利用するときに最もよく使われるツールが「Stable Diffusion Web UI」です。このツールには「Sampling method」という設定があり、ここでサンプラーを決めることができます。
一般的に、以下のようなルールがあります。
- 「a」または「SDE」が付くものはランダム要素が入る
- 「2」と付くものはEulerサンプラーと比べて時間が2倍かかる(ただしDPM++ 2MはEulerと同じ時間)
- 「++」は「改良版」という意味
- 「Karras」が付くものは、付かないものよりも精度がいい
初期のサンプラー
Eulerは、数あるサンプラーの中でも一番シンプルなサンプラーです。毎回同じ量のノイズを取り除いて、最終ステップで0ノイズ画像になるようにします。
HeunはEulerサンプラーの改良版です。精度を上げるためにEulerの計算を2回(つまりノイズ予測を2回)行います。そのためEulerサンプラーに比べて2倍の処理時間がかかります。
LMS(Linear Multi-Step Method)はEulerサンプラーと同等のスピードでより精度を上げるように提案されたサンプラーです。過去数回分のノイズ除去の結果から次のノイズ除去量を決める、という処理を行っています。
DDIM(Denoising Diffusion Implicit Model)はDiffusionモデルを効率化するために提案されたサンプラーのうち、最も初期のものです。
PLMS(Pseudo Linear Multi-Step Method)はいわばDDIMの発展形で、ニューラルネット用に調整したものです。
DPMサンプラー
DPM(Diffusion Probablistic Model)サンプラーはStable Diffusionに搭載された新しいサンプラーです。画像生成の精度を上げると言われていますが、処理時間は一般的にEulerサンプラーよりも遅くなります。
DPMサンプラーには様々なバリエーションがあります。
DPM Fastは処理時間がEulerサンプラーと同程度の速さですが、精度は他のDPMサンプラーに比べて低くなります。
DPM++は、オリジナルの改良版です。
DPM2は、オリジナルよりも2倍時間がかかります。
「Karras」サンプラー
Karrasとは人の名前です。2022年、NVIDIAのKarrasさんのグループが発表した論文で「ノイズをいつどれくらい取り除くか」(ノイズスケジューラー)が新たに提案されました。ここで提案された手法はStable Diffusionの各スケジューラーにも取り入れられ、「Karrasサンプラー」と呼ばれることになりました。
Karrasサンプラーの特徴は画像完成に近づくにつれてノイズ除去がより繊細になることです。例えばLMSは普通のLMSサンプラーとKarras版LMSサンプラーがありますが、一般的にKarras版の方が結果が良いとされています。
「a」サンプラー、SDEサンプラー
いくつかのサンプラーには「a」という記号がついています。これは「ancestral」の略ですが、Diffusionモデルではこのネーミングは大した意味を持ちません。
aサンプラーの最大の特徴は生成画像が収束しないことです。一般的にDiffusionモデルでは「正解画像」に向かって真っすぐ近づいていくように画像を生成しますが、aサンプラーは「ノイズを少し余計に引いた後、余計に引いた分を埋め合わせるようにまたノイズを加える」という作業を行うので「正解画像」に近寄ったり離れたりします。このせいで画像が処理終盤になっても収束せず、いきなり画像の内容がガラッと変わったりすることがあります。
なお、「埋め合わせるために加えるノイズ」は毎回ランダムに決まるので、同じ条件で画像を再度生成しても、aサンプラーを使っている場合は毎回微妙に違う画像が生成されます。
SDEサンプラーも同様に生成画像が収束しません。これはこのサンプラーが確率微分方程式を解いているからです(詳細は省略)。
UniPCサンプラー
Stable Diffusion Web UIで最近導入されたサンプラーです。このサンプラーの特徴は収束が速いことで、10程度のステップ数でもある程度完成した画像を生成してくれます。ただしクオリティを上げるには他のサンプラーと同程度のステップ数が必要になるようです。
迷ったら「DPM++ 2M Karras」
結局どれがいいの?という話ですが、現在スピードと品質を両立するもっともよいサンプラーは「DPM++ 2M Karras」です。これはEulerサンプラー(もっとも単純で最速)と同等のスピードでありながら画像精度が高い、優れたサンプラーです。
「DPM++ SDE Karras」も評判の良いサンプラーです。このサンプラーは画像が収束せず、ステップごとの時間もDPM++ 2M Karrasの2倍かかりますが、ステップ数を少なめにしても精度の高い画像ができるようです。
逆に「a」が付いたサンプラーは生成画像にランダム要素が入るので避けた方が無難だと思います。
まとめ
今回はサンプラーについて大まかな解説をしました。
ノイズを取り除いて画像を作っていくStable Diffusionでは、どのようにノイズを取り除くかが最終的な画像のクオリティに大きな影響を与えます。この「ノイズを取り除くプロセス」を決めるのがサンプラーですが、それぞれのサンプラーにはスピードや質に関して一長一短あります。
もちろん生成画像のクオリティは主観も入るので「これが決定版サンプラーだ」というようなものはありませんが、サンプラーによっぽどこだわりたい人以外はKarras系サンプラーを使っておけば間違いないでしょう。