誰でもわかるStable Diffusion コントロールネット
またリクエストいただいたので今回はコントロールネットについて見てみましょう。
- コントロールネットとは
- U-Netのしくみをおさらい
- コントロールネットのはたらき
- コントロールネットのU-Net
- コントロールネットの入力って?
- コントロールネットのU-Netを実際に使うには
- まとめ
コントロールネットとは
コントロールネットは「絵の構図」に特化した追加学習モデルです。ただ、絵の構図をプロンプトで指定するのでなく、「棒人間のポーズ」や「深度画像」といった画像データで指定するのが大きな特徴です。
「画像データで描きたいものを指定できるの?」と疑問に思われるかもしれませんが、可能です。指定方法がテキストプロンプトであっても画像データであっても、数字の列に変換されてしまえばどちらもStable Diffusionにとっては同じようなものです*1。
追加学習といえば「Dreambooth」とか「LoRA」とかいろいろありますが、コントロールネットはそれらに比べて規模の大きい追加学習と言えるでしょう。
Stable Diffusionで絵を描くとき、「U-Net」というメカニズムが使われます。コントロールネットを使用すると、U-Netがもう一つ追加されます。そのため、コントロールネットを理解するにはU-Netの仕組みを知っておく必要があります。次の項でU-Netの構造について軽く解説し、そのあとでコントロールネットの説明をします。
U-Netは以前の記事でも説明していますので詳細はそちらをご覧ください。
U-Netのしくみをおさらい
U-Netは大まかに25個のブロックからできています。25個のブロックは数珠つなぎのように繋がっていて、データを第1ブロックに入れるとそのデータは次々とブロックを渡り歩いていき、最後は第25ブロックから出てきます。ブロック間を渡り歩く間にデータは次々と処理されていきます。
この25個のブロック3つのグループに分けることができて、第1ブロックから第12ブロックまでを「エンコーダーブロック」、第13ブロックを「ミドルブロック」、第14ブロックから第25ブロックまでを「デコーダーブロック」と呼びます。
簡単のため、それぞれ「エンコーダー」「ミドル」「デコーダー」と呼ぶことにします*2。
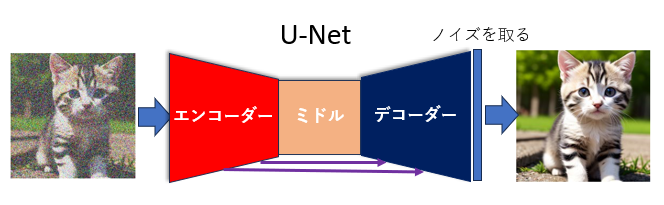
紫の細い矢印はスキップコネクション
それぞれのグループの働きを見てみましょう。
事前準備
以下の解説では、512x512ピクセルの画像を描くときの処理を例にして説明します。
最初に適当な砂嵐のような「ノイズ画像」を用意して、ここから完成絵まで画像を少しずつ変化させていきます。
さて、この画像はまずは64x64マスに「圧縮」されます。圧縮する方が計算量が少なくてすむからです。
エンコーダー
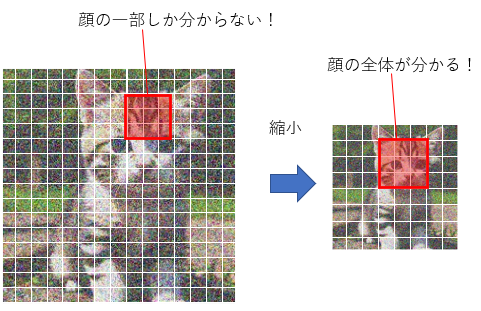
エンコーダーは、画像を小さくしながら画像の持つ特徴を取り出していくパートです。エンコーダーの最初のブロックである第1ブロックは64x64マスの画像データを受け取り、画像を作るための「処理」をします。これをバケツリレーのように第2ブロック、第3ブロック……と渡していきますが、画像がブロックを通るにつれて画像がさらに「圧縮」されて小さくなっていきます。第12ブロックを出るころには、画像サイズは8x8マスまで縮んでいます。縮んでいる間にも少しずつ完成に向かって画像を変化させているのですが、なぜ画像を縮める必要があるのでしょう?
それは、画像が「部分ごと」に処理されるからです。3x3マスをひとつのかたまりとして、このかたまりごとに特徴を取り出していきます。64x64マスの中の3x3マスといえば、全体のほんの一部分でしかありません。もしこれが絵だったら、この3x3マスではとても全体像を捉えられません。ネコの絵だったら、3x3に収まるのはせいぜい目とか耳とか毛くらいでしょう。
しかし、よりプロンプトに忠実な絵を描くためには、例えば背景とか、ネコがどんなポーズをしているかとか、全体像を処理する必要もあります。そこで画像を縮小するのです。最終的には8x8マスまで縮むので、3x3マスのかたまりでも十分全体を捉えることができます。
ミドル
ミドルでは、画像が最小の8x8マスになっていますが、画像の特徴が2560個も取り出されています。この画像サイズのまま、さらに特徴を抽出し、またプロンプトの情報も組み込みます。
デコーダー
デコーダーでは、今まで抽出した特徴をまとめていき、小さくなっている画像を拡大して元の大きさに戻していきます。ここでもプロンプト情報の取り込みは行われますが、重要なのは「画像が大きくなるにしたがって特徴量が減っていく」という点です。エンコーダーやミドルで抽出した特徴たちをまとめて画像内の情報をとらえ、それをもとに構築した新たな情報を画像に反映させていくのがデコーダーブロックの働きといえるでしょう。
さて、デコーダー内のブロックたちもエンコーダーやミドルと同じように、処理された画像を前のブロックから受け取り、自分のブロックで処理し、次のブロックに渡していきます。しかし、デコーダーのブロックたちはそのほかにエンコーダーのブロックから「直接」情報を受け取っています。
例えば、デコーダー内の最初のブロックである第14ブロックは、エンコーダー内の最後のブロックである第12ブロックから「直接」画像データを受け取っています。
この、デコーダーブロックがエンコーダーブロックから画像データを受け取る仕組みを「スキップコネクション」といいます。
U-Netで処理している間も画像はどんどん内容が変わっていくので、バケツリレー方式でデータを受け渡していると後になるにしたがって最初の方の情報が消えていってしまいます。これを防ぐため、画像の最初の方の情報を後ろの方のブロック(つまりデコーダー)に伝える仕組みがスキップコネクションです。
この「スキップコネクション」はコントロールネットで大きな役割を果たすので、覚えておいてください。
コントロールネットのはたらき
では、コントロールネットを追加してみましょう。
コントロールネットをオンにすると、U-Netによく似たモジュールがもう一つ現れます。
コントロールネットのU-Net
以下の図はコントロールネットの論文に載っている図です。左の方の灰色のブロックたちはStable Diffusion本体のU-Netを表しています。右の方の水色のブロックたちはコントロールネットで新たに追加されるU-Netです。

左はStable Diffusion本体のU-Net、右はコントロールネットのU-Net
デコーダーの構造がちょっと違う
Stable Diffusion本体のU-Net(本体U-Netと呼ぶことにします)と違って、コントロールネットのU-Net(コントロールU-Netと呼ぶことにします)では、デコーダー内のブロックは画像処理を行わず、データを次のブロックに渡すこともしません。その代わり、デコーダーブロックは「データを出力する」という機能を持っています。
通常のU-Netはデータ出力は一か所だけ、最終ブロックである第25ブロックだけがデータを出力します(上の図、左下の「Output」が出力です)。残りのブロックは処理したデータを次のブロックに渡すだけなので、U-Netの外に出力はされません。
ところが、コントロールU-Netはミドルとデコーダーのブロックがそれぞれデータを出力します。出力したデータはどこに行くのかというと、本体U-Netの中の対応するブロックに突っ込まれます(上の図の右から左に向かう水色の矢印)。
例えばコントロールU-Netの第14ブロック(デコーダーの最初のブロック)が出力したデータは、本体U-Netの第14ブロックに入力されます。
ゼロ畳み込み
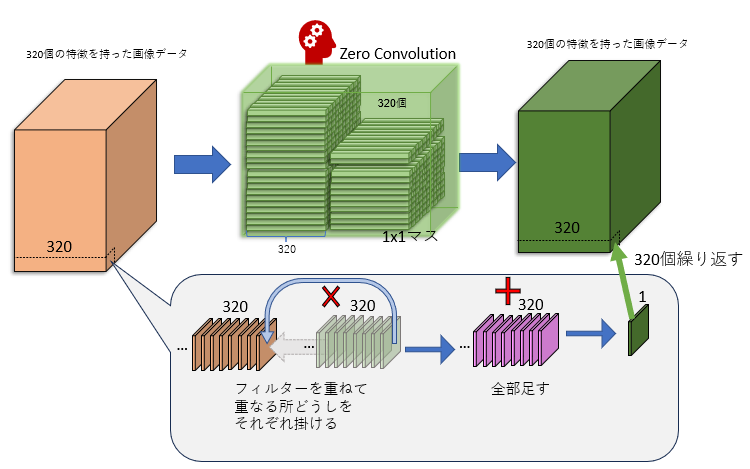
コントロールU-Netのデコーダーは本体U-Netと同じく12個のブロックからなっていますが、これらのブロックはすべて「ゼロ畳み込み」(zero convolution)というモジュールに置き換わっています。
「ゼロ畳み込み」は何も難しいことはしていません。「ゼロ」と名付けられてはいますが、やっていることは「1x1マスの畳み込み」です*3。
「1x1マスの畳み込み」とは、各マスごとに、特徴をいろんなパターンで混ぜてみる、という作業です。例えば1つのマスが320個の特徴を持っているとすると、マス内の320個の特徴を「ある値」で掛けて、(そして別の「ある値」を足して)、全部足す、ということを320パターン繰り返します。パターンごとに「ある値」は変わります。
畳み込みの結果、データの内容は変わります。しかし画像サイズは変わりません。320個の特徴は相変わらず320個の特徴のままです(320パターン計算したので)。
ゼロ畳み込みは本体U-NetにないコントロールU-Net独特のもので、この部分が棒人間画像などの構図データを学習(後述)します。本体U-Netのモデルからコピーして使っているだけのエンコーダーやミドルは学習しても全く変化しないので、ゼロ畳み込みモジュールこそがコントロールネットの「賢くなる部分」です。
ゼロ畳み込みを通った画像データは本体U-Netに送られます。
「スキップコネクション」が重要
コントロールU-Netのデコーダーブロックは隣のブロックにデータを送らない、ということを上で説明しましたが、例えばもし第14ブロックが次のブロックにデータを送らないなら、第15ブロックはどこからデータを受け取るのでしょう?
それが上でも説明した「スキップコネクション」です。コントロールU-Netのデコーダーブロックは、エンコーダーブロックから「直接」データを受け取っています(上の図の上から下に向かう水色の矢印)E。
つまりデコーダーブロックが出力しているデータは、エンコーダーブロックが処理したデータ(を少し変換したもの)なのです。
本体のU-Netに情報提供
さて、本体U-Netのデコーダーブロックは、「本体U-Net内のブロック」と「コントロールU-Netのデコーダーブロック」からそれぞれ同じサイズのデータを受け取ります。
入力された2つのデータは、足しあわされて混ざります。
つまりコントロールネットとは、絵を並行して2枚作り、生成中の2枚の絵をそのつど混ぜ合わせていく、というプロセスです。力関係としては本体U-Netの影響の方がコントロールU-Netよりも強力なので、完成した絵もそちらの影響の方が強く出ますが、コントロールU-Netに入力された「構図」情報も完成絵によく反映されます。
コントロールネットの入力って?
上の図の「入力」部分をちょっと拡大してみてみましょう。

コントロールネットを使う場合、3つのデータが入力されます。
- 画像データ(Input)
- プロンプト(Prompt)
- 構図データ(Condition)
画像データ入力
左の本体U-Netには「Input」というものが入力されています。これは「処理前の画像データ」です。上でも説明したように、最初は砂嵐のような画像を用意してInputとして本体U-Netに突っ込みます。砂嵐はU-Netを1回通るとちょっとノイズの減った画像になります。その画像をまたInputとして同じ本体U-Netに突っ込みます。これを指定ステップ数繰り返して、絵を生成していきます。
プロンプト入力
本体U-Netには、「プロンプト」も入力されています。これはユーザーが指定するテキストです。「Cat」とか「Dog」とか、描いてほしいものをテキストとして入力するとU-Netがそれを翻訳して、指定された絵を描いてくれます。
構図データ入力
図の右側のコントロールU-Netには「Condition」というものが入力されていますが、これは「絵の構図」を指定するデータです。ここでいう「構図」とは、例えば棒人間だったり、深度情報だったり、輪郭だったり、かなり抽象的な画像です。
他にも「処理前の画像データ」のコピーがコントロールU-Netに送られます(「Input」から伸びている矢印)。
構図と画像データコピーは、コントロールU-Netに入る前に統合されます。
(上の図では統合される前に構図画像が「zero convolution」を通っていますが、これは構図画像の透明度を調整するものだと思ってください)
なお、コントロールU-Netにも「プロンプト」が入力されます。
つまり本体U-NetとコントロールU-Netは、(少なくともエンコーダーは)同じような生成処理を並行して行っているのです。ただ、両者の入力画像データは微妙に違って、コントロールU-Netに突っ込まれる画像には構図情報もぼんやりと入っています。例えば構図が棒人間の場合、入力画像データにうっすらと棒人間が映っています。
コントロールU-Netはこの入力された棒人間入りの画像データを見て、「おっ、人間っぽいのがいるな」という感じで構図に沿った特徴を拾っていきます。この情報は本体U-Netに送られ、「人間っぽいのがいるぞ」と本体U-Netに教えます。すると本体U-Net(のデコーダーブロック)はその情報をもとに絵を仕上げるので、結果的に構図情報が反映された絵になっていきます。
絵から構図への変換はおまけ機能
上で解説した通り、コントロールネットは「構図情報」を受け取って処理します。
そのため、コントロールU-Netを使うには構図画像データを事前に用意する必要があります。「用意」とは、例えば人の映っている写真を棒人間の画像に変換したり、輪郭だけの画像に変換したり、といった処理です。

だいたい一緒に使うので付属機能みたいなもんです
ここで注意すべきなのは、構図画像への変換はコントロールネットの機能ではない、ということです。構図変換はあくまで「コントロールネットに入力する構図を用意するための前処理」です。
ただ、Stable Diffusion WebUIなどのアプリでは構図情報への変換もコントロールネットと一緒に提供されるので、まあ変換処理もコントロールネットの「付属機能」といっても差し支えないかもしれません。
Stable Diffusion WebUIでは、「Preprocessor」というリストから「どのタイプの構図画像に変換したいか」を選ぶことができます。

コントロールネットのU-Netを実際に使うには
さて、コントロールU-Netはもちろん最初から棒人間を「人間」だと知っているわけではありません。事前にそういう風に学習させたので「人間」として認識するだけで、「輪郭」しか知らないコントロールU-Netに棒人間画像を見せても「人間」とは思ってくれません。
そういうわけで、それぞれの「構図情報」に特化したコントロールU-Netを個別に用意する必要があります。「棒人間専用U-Net」とか「輪郭専用U-Net」という具合です。
Stable Diffusion WebUIでは、「Model」リストからモデル(つまりU-Net)を選択できますが、使用モデルは構図画像のタイプに合わせる必要があります。

合わせる必要があります
Stable Diffusion WebUIにはコントロールネットのモデル(コントロールU-Net)は付属していませんので、初期状態ではコントロールネットのモデルは空っぽです。
使いたいモデルがリストにない場合はダウンロードする必要があります。
さて、コントロールネットを使いたいなら「学習済み」のモデルをダウンロードしてきて使えばいいわけですが、もしモデルを自分で作りたい場合は(そんな人はあまりいないでしょうが)、モデルを学習して作る必要があります。
それぞれのU-Netは以下のような学習を行って構図情報の意味を勉強します。
- 元となるモデル(本体U-Net)を用意して、それをコピーし、コピーを元にコントロールU-Netを作る。
- テキスト付き画像を用意する。
- 画像を学習対象(「ポーズ」とか「深度」など)の「構図情報」に変換し、それをコントロールU-Netに入力する。
- 本体U-NetとコントロールU-Netを使って絵を生成する。プロンプトをもとに絵を生成することもあれば、プロンプトを完全に無視することもある。
- 絵が完成する。この絵を元のと比べて、なるべく似るようにコントロールU-Netの「ゼロ畳み込み」部分を修正する。
こうしてできたコントロールU-Netは、たとえば「棒人間専用コントロールネット」とか「深度専用コントロールネット」という感じで、別々に配布されます。
コントロールU-Netは本体U-Netと構造が違うとはいえ、U-Netであることに変わりはないので、ファイルサイズも通常は5ギガバイトを超えるほど大きいものになります。
まとめ
今回はコントロールネットについて解説しました。コントロールネットは追加学習の一種ですがそのパワフルさから多くのStable diffusionウェブアプリで標準搭載されるようになっています。
コントロールネットを使うと2つのU-Netが並行して実行され、1つは通常の生成処理、もう1つは「構図情報」を使って生成処理を行い、処理途中に何度も2枚の画像をミックスしながら1枚の画像を完成させます。そのため、両者の特徴が出た画像を作ることができます。