誰でもわかるStable Diffusion LoRAを作ってみよう(実践編)
以前の記事でLoRAを作るためのKohya_ss導入の解説を書きました*1。
今回は、kohya_ssを使ったLoRA作成の実践編です。
LoRAの簡単な説明
「LoRA」とは、要するに「追加コンテンツ」です。「〇〇.ckpt」または「〇〇.safetensors」という名前で、1つのファイルにまとまっています。
Stable Diffusionは「モデル」(=Stable Diffusionの脳みそ)を読み込むことでいろいろな画像を描けますが、モデルが知らないモノを描くことは基本的にはできません。そこでLoRAの出番です。画像を描かせるときに特定のLoRAを読み込むと、そのLoRAが持っている特徴の画像を描くことができます。
LoRA作成には、「用意した画像をStable Diffusionに学習させる」という作業が必要です。学習した結果がLoRAファイルとして保存されます。このLoRAファイルをStable Diffusionに読み込ませることで、学習した画像を再現できる、という仕組みです。
学習の方法はいくつかありますが、現在の主流は「kohya_ss」というツールを使う方法です。そこで、この記事ではkohya_ssを使ったLoRA作成法について解説します。
LoRA作成の準備
学習前に以下のような準備をする必要があります。
- (まだ行っていないなら)PCのスペックを確認
- (まだ行っていないなら)kohya_ssのインストール
- 学習したい画像を用意する
- 必要なら正則化画像を用意する
- 画像にキャプションを付ける
PCのスペックを確認
まずお使いのPCがLoRA学習をできるかどうかチェックしましょう。一番重要なのは「グラフィックカードのスペック」です。
お使いのPCのグラフィックカードを見てみましょう。以下はWindows11のチェック法です。
Windowsの画面左下、窓マーク(4つの四角)のアイコンを右クリックし、「タスクマネージャー」を開きます。タスクマネージャーの左端に並ぶアイコンの上から二番目、波形の形をしたアイコンを選ぶと「パフォーマンス」が開きますので、そこの左側パネルにある「GPU」を探してクリックしましょう。クリックすると右側のパネルに詳細情報が現れます。
右上に表示されているのがお使いのグラフィックカードの名前です。「NVIDIA」製のグラフィックカードでない場合はLoRA学習はできません*2
下の方にスクロールすると、「専用GPUメモリ」という表示があり、「0.8/8.0 GB」のような形で数字が表示されています。この右側の数字(今の例だと8.0 GB)がお使いのPCに乗っている物理的なVRAMの容量です。この数字を覚えておきましょう。
6GBあれば一般的なLoRA学習は可能です。学習画像のサイズにもよりますが、4GBでもかろうじて動くかもしれません。2GBは未確認です。
kohya_ssのインストール
インストール法については以前の記事で説明しましたので、そちらを参考にしてください。
学習したい画像を用意する
kohya_ssをインストールしたら、いよいよLoRA作成です。
作成のために、学習画像を用意します。
何を表現したいのか考えよう
LoRAを使えば、自分の表現したいものをStable Diffusionで描き出すことができます。
では、あなたはLoRAで何を表現したいのでしょう?
バカげた質問に聞こえるかもしれませんが、考えてみると案外ぼんやりとしたイメージしか持っていないことも多いものです。ここで少しイメージを固めておくと、学習画像やキャプションのクオリティが上がり、LoRAの精度もより上がるでしょう。
あなたが表現したいものは?
- モチーフは人物?物?風景?画風?構図?
- 細かい部分?それとも大まかな部分?
- その表現を強力に前面に出したい?それともちょっとしたワンポイント程度?
- 写真のようなフォトリアルなイメージ?それとも2次元イラスト?
- ベースモデルにないもの?それともベースモデルのイメージを拡張するもの?
- ある1つの表現だけ?それとも複数の表現の組み合わせ?
わかりやすい画像を選ぼう
あなたの表現したいもの(「ターゲット」と呼びます)が決まったら、ふさわしい画像を用意しましょう。すべての画像にターゲットが必ず含まれるようにします。それぞれの画像に写るターゲットの大きさや向きがバラバラであっても問題ありません。むしろバラバラの方がいいくらいです。画像のバリエーションは多ければ多いほど結果は良くなります。
今回、例として「猫耳セーラー服」をターゲットにしてLoRAを作ってみます。セーラー服を着た猫耳の女性の画像を用意します。

画像を整えよう
画像を用意したら、次にその画像を学習にふさわしい形に整えます。主な作業は「画像サイズをそろえること」と「画像を修正すること」です。
ー画像サイズをそろえる
LoRA作成に使う画像はどんなサイズでも構いません。また、サイズがバラバラであっても構いません。ただ、Stable Diffusionのモデルは、バージョン1系は512x512ピクセル、バージョン2系は768x768ピクセルの画像で学習していることが多いので、LoRA学習で使う画像もどちらかのサイズに合わせるのが無難です。
バラバラの画像サイズを使う場合は、バッチサイズ(同時に学習する枚数)に注意してください。バッチサイズを増やしたいなら同じサイズの画像を何枚ずつか用意する必要があります(同じサイズの画像でないと同時に読み込めないからです)。例えばバッチサイズを2にしたいなら、使用サイズそれぞれに対して2枚以上ずつ用意する必要があります。
画像のアスペクト比については特に決まりはありませんが、ほとんどのモデルはアスペクト比1:1の画像で学習されていますので、できれば1:1に合わせる方がいいでしょう。
kohya_ssでは画像サイズに関する設定がいくつかありますので、覚えておくとよいでしょう(kohya_ss設定については下の方にも説明があります)。
- Max resolution:画像の最大サイズをここで指定します。このサイズを超える画像は縮小されます。ただし「Don't upscale bucket resolution」オプションをオンにした場合は無視されます。
- Enable buckets:いろいろな画像サイズを学習できるようにするオプションです。画像サイズが統一されていない場合は必ずこのスイッチをオンにしましょう。
- Don't upscale bucket resolution:最大サイズのリミットを外すボタンです。このスイッチをオンにすると、どんなに大きなサイズの画像もそのまま読み込んで学習します。オフの場合は、最大サイズを超える画像は縮小されます。
- Bucket resolution steps:画像をサイズによってグループ分けするときに、何ピクセルごとにグループ分けするかを指定します。
特に注意しなければいけないのは「Bucket resolution steps」です。デフォルトは64ピクセルですが、これは準備する画像のピクセルサイズが(タテヨコどちらも)64で割り切れないといけないという意味です。もし割り切れない場合、余分なサイズは切り取られてしまいます。できればここは64のままにしておいて、画像サイズを合わせる(つまり64ピクセルで割り切れるサイズを使う)ようにしましょう。
今回の「猫耳セーラー服」の例では、画像を縮小して512x512に揃えました。画像枚数が少ないので1枚を何枚かに切り分けたりして枚数を水増ししています。

ー画像を修正する (オプション)
可能であればターゲット「のみ」写っている画像を用意するのが理想ですが、実際の学習画像にはターゲット以外のいろいろなものが写り込んでいるのが普通です。もし理想的な学習画像でなくても、あまり神経質になる必要はありません。キャプションを適切につければ学習はそれなりにうまくいきます(キャプション付けは後述)。
しかし、もし余計なものが映りすぎると感じたりキャプション付けが難しいと思うなら、画像から余計なものを消してしまいましょう。
例えば、もしターゲットが「服」であれば、その服だけが重要で、どこで誰が着ているかは重要ではないので、着ている人物の顔や背景などを消します。
消すときは、消したい部分をぼかすのでなく、真っ白に塗りつぶしましょう。真っ白い部分は学習されませんが、ぼかした部分は学習されてしまいます。もし顔をぼかしてしまうと、出来上がったLoRAは「ピンボケ顔」ばかり出力するおかしなLoRAになってしまいます。
「顔を塗りつぶして大丈夫?顔のない怪物になっちゃうんじゃないの?」と思われるかもしれませんが、大丈夫です。Stable Diffusionモデルはもう人体の構造を十分に学習しているので、「服の上には顔が来る」ということを知っています。このLoRAを使ってもちゃんと顔を描き上げてくれます。
背景も(必要なら)白く塗りつぶしましょう。
「猫耳セーラー服」の例では画像を修正せずにそのまま使います。
画像フォルダを作る
画像が用意できたら、それらをフォルダの中に置きます。kohya_ssに読み込ませるには、少し特殊なファイル構造が必要です。
まず、適当な場所にフォルダを1つ作りましょう。このフォルダが今回のLoRAを学習するためのおおもとのフォルダになります。例として「lora_test」というフォルダを作ってみます。

この「lora_test」フォルダの中に、もう1つフォルダを作ります。このフォルダの中に画像を入れます。
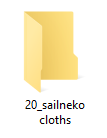
さて、このフォルダの名付け方には決まりがあります。「画像を読み込む繰り返し回数」をフォルダ名先頭に必ず書かなければいけないのです。例えば、フォルダ内のそれぞれの画像を10回繰り返し学習したい場合は、フォルダ名の先頭に「10_」と付けなければいけません。20回なら「20_」です。「‗」(アンダーバー)記号も忘れないようにしましょう。
この数字の後ろに加えるテキストですが、以下のルールがあります。
- 画像にキャプションをつけない場合:「キーワード クラス名 」(例「20_sailneko cloths」)
- 画像にキャプションをつける場合:何でもいい(例「20_sailneko」)
画像にキャプションをつけない場合、このフォルダ名がキャプション代わりになります。上の例では、最初の「sailneko」はターゲットを呼び出すときの「キーワード」になります。半角スペースを挟んで2つ目の「cloths」はターゲットのクラス(種類)を表します(もしターゲットが女性キャラならクラス名は「girl」とか「woman」)
名前の最初に必ず学習の繰り返し数をつけます
テキスト部分は「キーワード クラス名」(半角スペースで区切る)
フォルダ数はいくつでもOK
画像にキャプションをつけるときは、フォルダ名は無視されるのでどんな名前を付けても構いません。

名前の最初に必ず学習の繰り返し数をつけます、テキスト部分は何でもOK
フォルダ数はいくつでもOK
「数字付きの名前を持つフォルダ」を作ったら、その中に画像を入れましょう。
ちなみに、この「数字付きの名前を持つフォルダ」はいくつ作っても構いません。
例えば10回繰り返したい画像と20回繰り返したい画像があるなら、「10_fuku1」「20_fuku2」という感じでフォルダを2つ作って、それぞれの画像を繰り返したい数に応じて2つのフォルダに振り分けましょう。
「繰り返し回数が同じでも画像の内容に応じてフォルダを分けるべきなのか」という疑問ですが、画像にキャプションを付けない場合は、フォルダ分けしてもいいでしょう。学習時はフォルダ名の「キーワード」がその中に入っている画像のキャプションになります。
画像にキャプションを付けるのであれば、フォルダ分けには意味がありません。どうせ学習するときにはすべてのフォルダの画像が混ざります。
画像にキャプションを付ける
それぞれの画像に、説明文(キャプション)を付けます。必須ではありませんが、キャプションを付けた方がLoRAクオリティは飛躍的に上がるので、よほどの理由がない限りはキャプションを付けましょう。
キャプションは自動で書いてもらうこともできます。
キャプションの自動作成
画像にキャプションをつけるのはなかなか大変な作業です。英語で書かなければいけないうえに、画像内容を詳しく説明するのも簡単ではありません。そこで、自動的に画像のキャプションを書いてもらうツールを使ってみましょう。
kohya_ssにBLIP、GIT、WD14というツールが用意されています。まずはこれを使ってキャプションを作成しましょう。
WD14は「black, cat, face, tail」などのように、コンマで区切られた単語を並べるスタイルでキャプションが作られます。GIT、BLIPを使った場合は「a black cat is sitting on a chair」のようにより文章に近いスタイルでキャプションが作られます。
どちらがいいのかは一概に言えません。
Stable Diffusionにキャプションを取り込む「Text Encoder」というモジュールは、もともと文章スタイル(つまりGIT、BLIPスタイル)でキャプションを分析するようにできていて、画像生成も文章スタイルのプロンプトの方が画像品質が良いとの情報があります。しかし、今では多くのモデルがコンマ区切りスタイル(つまりWD14スタイル)で画像を学習していて、画像を生成するときもコンマ区切りスタイルでプロンプトを書く手法が主流なので、そちらのスタイルを好む人も多いようです。
今回の例では、コンマ区切りスタイルを使うことにします。
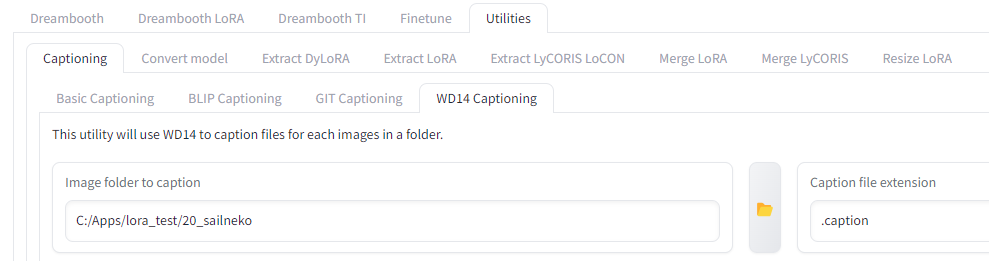
kohya_ssの一番上に並ぶタブの一番右、「Utilities」タブを選択します。
するとそのすぐ下にまたタブが並ぶので一番左の「Captioning」を選びましょう。
またしてもすぐ下にタブが並ぶので一番右の「WD14 Captioning」を選びます。
ここで指定すべきは2つだけ、「Image folder to caption」と「Caption file extension」です。
「Image folder to caption」は「キャプションをつけたい画像が入っているフォルダ」を指定します。上の例でいえば「20_sailneko」といった「数字で始まる名前のフォルダ」です。
「Caption file extension」は「.caption」と書きます(学習設定と合わせるためです)。
これだけ指定したら「Caption images」ボタンを押しましょう。
初回は処理に必要なファイルがダウンロードされることがあるので待ちましょう。
しばらく待つと「captioning done」というメッセージがプロンプト(黒背景に白い文字が並ぶウィンドウ)に表示されます。
できたキャプションはテキストファイルとして画像と同じ場所に画像と同じ名前で保存されます。例えば「f001.png」という名前の画像のキャプションは「f001.caption」という名前で保存されます。
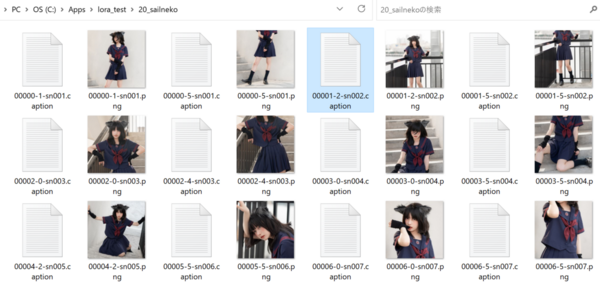
キャプションの手直し
自動作成されたキャプションをそのまま使っても構わないのですが、細かくチェックしてみると決して完ぺきなキャプションとは言えません。もし精度にこだわるなら、手直しをしましょう。
- ターゲット名をつける
- ターゲット以外のものを「全部」キャプションに書く
- 表記ゆれを直す
例として、この写真につけられた自動キャプションを見てみます。

1girl, solo, long hair, looking at viewer, smile, bangs, skirt, shirt, black hair, gloves, animal ears, closed mouth, school uniform, short sleeves, pleated skirt, serafuku, day, black gloves, cat ears, fingerless gloves, black skirt, sailor collar, lips, blue skirt, neckerchief, hand on hip, blue shirt, blue sailor collar, red neckerchief, black serafuku, realistic, railing, red lips, blue serafuku
なかなかの精度ですが、同じ単語が何度も出てきたり、説明が重複しているところもあります。これを直します。
まず「ターゲット」となるものに名前を付けましょう。これがLoRA使用時にプロンプトでターゲットを呼び出す「キーワード」になります。
ターゲットが独特なものなら、ターゲット名を自分で発明してしまいましょう。なるべく使われていない意味のない単語を選ぶようにします(例えばtzwとかbksとか)。推奨は「アルファベット3文字程度」となっていますが、別に3文字でなくても構いません。分かりやすい単語でももちろん構いません*3。
もしターゲットが画風の場合は、「〇〇 style」というふうに書けばいいと思います。
ターゲット名はキャプションの先頭に持ってきましょう。
今回の例では、ターゲットを「sailneko」という名前(猫耳セーラー服なので)にしてみます。
次に、「ターゲットでないもの」が「全部」書かれているかを確認します。書かれていないならキャプションにどんどん付け足していきます。例えば、ある人がセーラー服を着ている画像の場合、服はターゲットですが、それを着ている人物はターゲットでないので、「1girl」と付け足します。その他、「ターゲットでない」ものを気づく限りできるだけ多く書き足しましょう。これが詳細であればあるほどLoRAの精度が上がります。
同時に、「ターゲットに含まれる要素」の単語は取り除きましょう。例えば「猫耳と服」がターゲットの場合、ターゲットを(何でもいいんですが)「sailneko」と名付けたとして、ターゲットの要素はその「sailneko」に入っているので、「animal ears」「cat ears」とか「skirt」「school uniform」といった単語はもういりません。それらの単語は消します。手袋は「sailneko」要素にしたくないので、「gloves」のような単語は残しておきます。
上の写真の自動キャプションを直した結果、以下のようなキャプションになりました。
sailneko, 1girl, solo, long black hair, bangs, closed mouth, red lips, looking at viewer, smile, day, black fingerless gloves, hand on hip, realistic, railing, stairs
このような感じですべての画像のキャプションを直していきます。
すべての画像のキャプションで同じ表現を使うようにしましょう。例えば女性の画像を自動キャプション付けした場合、「woman」だったり「girl」だったり「person」だったり、画像によっていろいろな単語が使われているかもしれません。これらは統一しておきましょう。
キャプションはLoRAのクオリティを上げるためにとても重要なので、しっかり書きましょう。「何を表現したいのか」というイメージがしっかりまとまっていれば、キャプションも適切につけられるようになります。
注意:キャプション内の単語は全部学習される
LoRA学習は、ターゲットだけでなく、キャプションに書かれた単語すべてを新たに学びます。しかも、その学習が非常に「強力」なので、以前覚えていた概念を上書きしてしまうこともあります。
例えばある学習画像の背景に火星(mars)が映っていて、そのキャプションに「mars」と書いてあれば、LoRAは(たとえそれがターゲットでなくても)「火星の絵」も新たに学びます。このLoRAを使った時、「mars」とプロンプトに指定すれば、新たに学んだ火星が描かれます。新たに覚えた「火星」がそれまで覚えていた「火星」を上書きしてしまうのです。ただ、プロンプトに「mars」と書くことはあまりないので、この「火星」学習の影響は少ないでしょう。
しかし、「girl」の場合はどうでしょう?プロンプトでもキャプションでも「girl」と指定することは結構あります。もしLoRAが「girl」の概念を新たに学んでいたら、このLoRAを使ってプロンプトに「girl」と指定するたびに「学習画像に映っていた女性」の絵ばかり出てきてしまいます。それでは困るのです。その女性はターゲットではないからです。
では、その特定の「girl」をどうやって取り除けばいいのでしょう?
まず思いつくのは「キャプションにgirlと書かない」という方法です。キャプションに書いてなければ新たに「girl」を学習することはありません。しかし、これは別の問題を生みます。「girlとして学習されなかった女性のイメージ」がほかの単語にくっついてしまうのです。もしそれが「ターゲット名」にくっついた場合、事態はさらに悪化します。「ターゲット名」をプロンプトで指定するたびに、その女性しか出てこなくなるからです*4。いろいろな女性を生成したいのに…。
そこで別の方法が提案されました。それが「正則化画像」です。
正則化画像を用意する (オプション)
「正則化画像」とは、「LoRA学習をかく乱させるための妨害情報」みたいなものです。上の例では、「girl」とキャプション付けられた別人女性の画像を大量に用意することによって、「girl」が特定の女性にならないようにします。
「正則化画像」の対象となる単語は、
- 学習画像のキャプション内で頻繁に使われている単語
- 画像生成時にプロンプトでよく使われる単語
を基準に選ぶのがいいと思います。例えば「mars」はそれほどプロンプトで使われないうえ学習画像にもあまり出てこないので正則化は不要でしょう。
「girl」のような「大まかな概念」(「クラス」とも呼ばれます)は頻繁に出てくるので正則化が好ましいかもしれません。「LoRAを使った時に学習画像の女性しか出てこなくなっても全然オーケー」というならもちろん正則化は不要ですが。
「めんどくさいので正則化画像は使わない」というのも一つの手です。「このLoRAを使ったらこういう絵ばかり出るんだ、そういう仕様なんだ」と割り切ってしまうのも、それはそれでアリです。
もし正則化画像を使うのであれば、画像の内容はバラバラであればあるほどいいとされています。かく乱が目的なので、ある特定の特徴に偏らないようにしましょう。枚数は「学習画像の枚数x繰り返し数」と同じくらいの数がいいようです。例えば学習画像が20枚で、それぞれ10回繰り返す場合、20x10=200枚が基準です。ただ、それより少ない枚数でも学習自体に問題はありません。正則化画像の繰り返し学習数を増やす(後述)のも手です。
正則化画像は、専用にフォルダを用意して、そこに入れます。このフォルダ構造は学習画像と同じです。
まず、正則化画像のおおもとになるフォルダを作ります。これは学習画像とは全く別のフォルダです。「reg_sailneko」とでもしておきます。
次に、このreg_sailnekoフォルダの中にまた新しいフォルダを作り、そのフォルダに正則化画像を入れます。このフォルダは名付け方に規則があり、「1_girl」のように「学習を繰り返す回数_正則化したいキーワード」という方式で名前を付けます。正則化画像は通常、数字は1(つまり繰り返さない)で構いませんが、画像数が少ない場合は繰り返し数を増やしてください。また、正則化画像にキャプションは必要ありません。キャプションがない場合はフォルダ名にあるキーワード(ここではgirl)が使われます。
今回の例では正則化画像を使わないことにします。
Kohya_ssで学習設定をする
画像とキャプションが用意できたので、ついにkohya_ssを使ってLoRA学習を実行します。
kohya_ssを立ち上げたら、「Dreambooth LoRA」タブを選びましょう。このタブを選ばずに間違って「Dreambooth」タブで設定をしてしまうことが多いので気をつけましょう。
設定には「Source model」「Folders」「Training parameters」の3つのセクションを設定する必要があります。
![]()
Source model
ここで学習のベースとなるモデルを選択します。LoRAはここで選んだモデルに付け足される形で学習されるので、モデルと学習画像のスタイルがあまりにもかけ離れていると、写真にマンガを描くようないびつな学習になるのでモデル選びは慎重に行いましょう。出来上がったLoRAはどんなモデルとも一緒に使えるので、使用するときにどのようなモデルと一緒に使われるかを想定して選ぶのも重要です。
「Save trained model as」は「safetensors」にしてください。

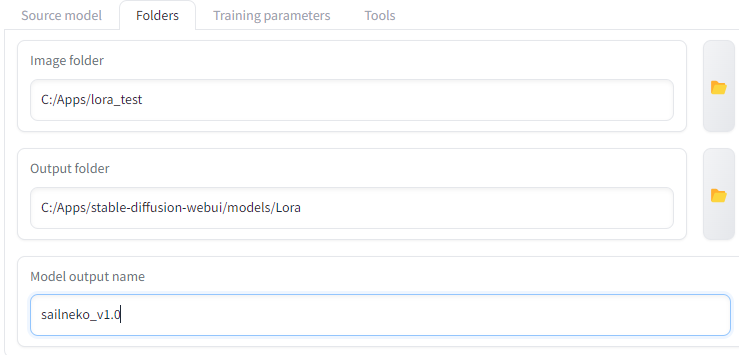
Folders
ここで学習画像のフォルダとLoRA出力先フォルダを指定します。
「Output folder」(LoRA出力先フォルダ)はどこでも構いません。適当に決めましょう。
「Image folders」(学習画像のフォルダ)は、画像の入ったフォルダ(「20_abc」のような、名前の先頭に数字のついたフォルダ)ではなく、その1つ上のフォルダを選んでください。
「Regularisation folder」(正則化画像のフォルダ)も同じように、画像フォルダの1つ上のフォルダを選んでください。正則化画像を使わないならフォルダ指定欄は空にします。
「Logging folder」は学習ログを保存するためのフォルダです。これも適当に決めてかまいません。空のままにしておくと、実行パスにログフォルダが作成されます。
「Model output name」は学習後に作成されるLoRAの名前です。「sailneko_v1.0」のようにターゲット名とバージョン番号をつけておくと後で見やすくなります。
Training parameters
kohya_ssには設定がたくさんあり、混乱してしまいそうですが、初めはほぼデフォルト設定のままで構いません。こだわりたくなったらいろいろ設定を変えてみましょう。
各設定については以下の記事で詳しく解説していますので見てください。
以下は独断による推奨設定です。
- Train batch size:2~4
- Epoch:2~3
- Mixed & Saved precision:bf16またはfp16
- Seed:何か数字を入れておく(何でもいい)
- LR Scheduler:constantまたはcosine
- Optimizer:AdamWまたはAdamW8bit
- Network Rank(dimention):8~32(大きいほど精度がいい)
- Network Alpha:Network Rankと同じ数字
- Clip skip:2次元系画像なら2、3次元系画像なら1
- Memory efficient attention:もしVRAMが8GB未満ならチェック
あとの設定はデフォルト値でいいと思います。
「猫耳セーラー服」LoRAの作成では、設定値は
- Train batch size:2
- Epoch:2
- Mixed & Saved precision:fp16
- Seed:1234
- LR Scheduler:constant
- Optimizer:AdamW8bit
- Network Rank & Network Alpha:32
- Clip skip:1
にしました。また、ターゲットが左右対称なので、「Flip augmentation」(学習時にランダムに画像を左右反転させる)オプションもオンにしました。
設定が終わったら、この設定を将来のために保存しておきましょう。
「Configuration file」の項目を押すと、「Save」ボタンが出てくるのでどこか適当なところに設定をセーブします。将来的にこの設定を使いたいときは、同じConfiguration file項目から「Load」を押して設定ファイルを読み込みます。設定ファイルを読み込んだ後も、画像フォルダやLoRA名を毎回変えなければいけない事に注意してください。
学習開始
さて、いよいよ学習の開始です。画面下の「Train model」というオレンジ色のボタンを押してください。学習が始まります。
学習の進行具合はkohya_ssの画面ではなく「コマンドプロンプト」(黒い背景に白い文字がたくさん表示されるウィンドウ)に表示されます。ここにプログレスバーが出るので、このバーが右側いっぱいまで伸びるのを待ちましょう。
1つのLoRA学習の目安は5分~30分です。長く学習すればいいというわけでもありません。
学習が終わると、指定した出力先フォルダにLoRAファイルができています。
このファイルをStable Diffusion Web UI内の「models」→「Lora」フォルダの中に入れると、このLoRAが使えるようになります。
今回の例で作成したLoRAは学習回数が240回、時間にして4分ほど、とかなり少なめですが、それでも完成したLoRAを使ってみると「猫耳セーラー服」要素をかなりよく再現しています。ただ、よく見るとデザインが違っていたり、正則化画像を使っていないので学習画像の女性の要素も混ざりがちです。完璧なLoRAを作るのはここからさらに試行錯誤が必要です。


まとめ
今回はLoRA作成の実践編として、LoRA学習のための画像の準備の仕方からkohya_ssの設定法までを解説しました。
LoRAはかなりパワフルな追加学習法ですが、ただ単にLoRAを作ればいいというものではありません。LoRAの学習には学習画像、キャプション、学習設定と様々な要素がからむので、理想的なLoRAを完成させるには試行錯誤が必要です。
あなたの理想の画像を出力できるようになるために、いろいろなLoRA学習を試してみてください。