誰でもわかるStable Diffusion リージョナルプロンプト
コメントでリクエストをいただいたので今回はStable Diffusion WebUIの拡張機能として提供されている「リージョナルプロンプト」について解説します。
(リクエスト引き続きお待ちしてます)
※このブログを読まれている方はもうご存じだと思いますが、この記事は「いい絵を生成する方法」は解説していません。あくまで「しくみ」の解説であることをご了承ください。
リージョナルプロンプトとは
Stable Diffusionに絵を描かせるとき、どんな絵を描きたいかを英語のテキストで指定します。このテキストの事を「プロンプト」と呼びます。
最近はプロンプトの書き方も研究が進んで、プロンプト技法をうまく使えば自分のイメージにかなり近い絵を描くことができます。
しかし、デフォルトのプロンプトではどうしてもうまく描けない構図があります。それは「複数のコンセプトを別々に描く」構図です。
例えば2匹の猫を描きたいとします。
2 cats
とプロンプトに書けばたいてい2匹のネコが描かれます。
しかし、この2匹のネコの特徴をそれぞれ指定したらどうなるでしょう?
「寝ている白ネコ、歩いている黒ネコ」と入力してみます。
sleeping white cat and walking black cat

なかなか思い通りの絵が出てきません。人間が読めば「白いネコは寝ていて、黒いネコは歩いている」と分かるのですが、Stable Diffusionはこういう「共通するコンセプト」を混ぜてしまいがちです。
Stable Diffusionでは「テキストエンコーダー」というプロンプト翻訳機能が使われます。テキストエンコーダーは本来、英語の文脈や文法も考慮してプロンプトを解読するので、上記のような単純なプロンプトは難なく翻訳してくれるはずなのですが、実際に出来上がった絵を見ると、その翻訳をうまく理解できていません。プロンプトが長くなるとどんどん文脈が複雑になるので、より思い通りの絵を描かせるのが難しくなってきます。
もちろん、プロンプトの文法を正しく書けばテキストエンコーダーがより正しく翻訳してくれる可能性は高くなります。しかし、Stable Diffusionの「混ぜ癖」はそれだけでは解決しません。
そこで提案されたのが「リージョナルプロンプト」です。
「リージョナルプロンプト」とは、要するに画像を区切ることです。
弁当箱をイメージしてください。区切りのない弁当箱にごはんやいろいろなおかずを詰め込んだら、全部混ざってしまいます。汁が出るおかずやソースのかかったおかずがあったら大変です。
弁当を1枚の絵とすると、混ざるプロンプトとは、弁当内の汁やソースに相当します。これらが混ざらないようにするために、仕切りを作って別々の区切りに別々のおかずを入れます。
リージョナルプロンプトも弁当と同じように「左はSleeping cat、右はWalking cat」というふうに区切りを作ってそれぞれの区切りごとに別のプロンプトを指定します。
「つまり、別々の画像を作ってくっつけてるだけ?」と思われたかもしれません。
その通りです。
しかし、ただ単純にくっつけただけではツギハギだらけの美しくない絵になってしまうので、「別々の画像を作る」手法と「くっつける」手法にちょっと工夫が必要です。
リージョナルプロンプトのはたらき
※注意
以下の説明は「Stable DiffusionのU-Netが『画像』を生成している」という体で解説をしています。実際はU-Netが生成しているのは「画像に乗っているであろうノイズ」です。何を言っているのか分からない方は気にしなくても結構です。
リージョナルプロンプトでは、画像を細かく切り分け、その区画ごとに違うプロンプトを指定します。ここまでは共通ですが、「画像の別々の区画に別々のプロンプトをどう取り込むか」の手法が2つあります。「Latent Couple」と「Attention Couple」です。
Latent Couple
Latent Coupleは単純です。要するに画像のそれぞれの区画ごとに画像を別々に作ります。これだけ聞くと複数画像をくっつけているだけのように思われるかもしれませんが、Latent Coupleの場合はもうちょっと手の込んだ2つの特徴があります。
- 背景画像も作れる
- 圧縮状態の画像を統合する
例えば2枚の別の画像があるとします。Latent Coupleでは、この2枚のほかにもう1枚「背景画像」を作ることができます(作らないこともできます)。以下、背景画像を作る場合の説明をします。
画像編集ソフトを思い浮かべると分かりやすいと思います。まず背景レイヤーに「2匹のネコ」と名前を付けます(レイヤー名がプロンプトに相当します)。この背景レイヤーに軽く下描きをして、どの辺にどういうネコがいるか、おおまかな構図を決めます。次に、背景レイヤーの上に同じ画像サイズの新たなレイヤーを2枚作り、1枚は左側に白ネコの絵を、もう1枚は右側に黒ネコの絵を描きます。2枚のネコ絵レイヤーは、それぞれ描画範囲が重ならないようにします。最後にレイヤーを統合すれば完成です。
別々の絵も背景に馴染ませればそれなりにキレイに見えるんじゃないか、というアイデアです。

2つ目の特徴は、完成したピクセル画像をくっつけるのでなく、圧縮状態(つまりLatentスペース)の画像をくっつけることです。
画像内のそれぞれの区画はレイヤーごとに別々に仕上げていくわけですが、それぞれのレイヤーを圧縮された状態のまま統合します。これによって、完成画像をくっつけるよりもより滑らかに画像統合できることが期待されます。
Latent Coupleを使って描いた画像は、それぞれの区画に指定プロンプトが詳細に反映されます。それぞれの区画が独立して描かれているので当然と言えば当然ですが、特定プロンプトで指定したものを他のプロンプトと混ざることなくかなりきっちり描いてくれます。
半面、Latent Coupleは処理が重くなります。
例えば3つのパートに画像を分けたとき、3枚の画像+背景画像1枚+ネガティブプロンプト画像1枚の計5枚の画像を別々に書く必要があり、結果的に1枚の画像を描くよりも5倍の処理が必要です。たとえ右半分に何もない左半分だけの絵でも、Stable Diffusionは何もない部分に「何もないようにする」という「処理」を行うので、結局1枚絵を描くのと変わらない労力が必要です。
なお、「バッチ処理」という手法によって5枚を並行して1度に描くので、5倍時間がかかるというわけではありません。それでも処理が重いので時間は多めにかかるでしょう。
Attention Couple
Attention CoupleはLatent Coupleの改良系として提案されました。
Latent Coupleの違いは、それぞれの区画を別々の画像として描かず、最初から1枚の画像として描く点です。このため、Latent Coupleのようにそれぞれの区画に1枚絵と同等の時間をかける必要がなく、1枚分の絵を描く処理ですべての区画を描いてくれます。
画像編集ソフトの例でいえば、Latent Coupleが「レイヤー分け」なら、Attention Coupleは「レイヤー分けせず範囲選択して描く」という感じです。
最初から1枚絵として描くので、画像内で整合性のとれた(つまりツギハギの目立たない)絵になることが期待できます。
その反面、それぞれの区画のプロンプトがあまりはっきり反映されない「ぼやけた」画像になる可能性もあります。これは、Stable Diffusionの心臓部である「U-Net」というしくみが、画像の拡大、縮小を繰り返しながら絵を描いていくからです。画像を縮小してしまうとそれぞれの区画が小さくなりすぎてほとんど区別がつかなくなってしまうのです。極端な例では区画が1マスまで縮んでしまいます。その1マス中に特定プロンプトを詰め込むのは非常に大変です。
Attention Coupleのしくみは「Attention」のしくみを知っていると分かりやすいので、以下に軽く解説します。そこまで興味がない方は読み飛ばしてください。
プロンプトが画像になるしくみをおさらい
※このセクションはちょっと複雑なので、リージョナルプロンプトについて軽く知りたいだけならここは読み飛ばしてください。
Stable Diffusionはどうやってプロンプトを画像に変換しているのでしょう?
変換するうえでとても大きな役割を果たしているのが「テキストエンコーダー」と「Attention」です。
これについては以前の記事で詳しく解説しているのでそちらもご覧ください。
ここでは概要を説明します。
Stable Diffusionがプロンプトから画像を作るしくみは、おおまかに2つのパートから成り立っています。
- プロンプトを数字に変換する「テキストエンコーダー」
- 数字になったプロンプトを画像に取り込む「Attentionブロック」
テキストエンコーダーの仕事
プロンプトとは、人間が読めるテキストです。Stable Diffusionはテキストが読めず、数字しか読めません。そこで「テキストエンコーダー」がプロンプトを数字の列に変換します。
まず、プロンプトのそれぞれの単語を、さらに細かい単語に切り分けます。切り分けられた後の小さな単語を「トークン」と呼びます。トークンになって初めて、テキストエンコーダーがその意味を理解できるようになります。
例えば「xformers」という単語は短いにもかかわらず「x」「form」「ers」の3トークンに切り分けられます。
もちろん単語がいつも切り分けられるわけではありません。「cat」という単語はもうこれ以上切り分けられないのでそのままです。
次に、それぞれのトークンを768個の数字列(ベクトルと言います)に変換します。「x」だろうと「cat」だろうと、トークンの長さに関係なくすべて必ず768個の数字になります。テキストエンコーダーはかなり賢く、単語の順番、重要度、意味などをすべて考慮して、それらをすべて含んだ最適な数字の列をそれぞれのトークンに対して作り出します。
人間の側としては「ただの数字列にそんないろいろな情報を詰め込めるの?」と感じてしまいますが、Stable Diffusionにとってはその数字列こそが情報の宝庫なのです。

さて、ここからが重要ですが、テキストエンコーダーはそれぞれのトークンから768個の数字列を3つ作るのです。
3つのベクトルにはそれぞれ名前がついていて、「Q」「K」「V」と呼ばれます。
※Qは「クエリ(Query)」の略、Kは「キー(Key)」の略、Vは「値(Value)」の略です。
この3つのベクトルはそれぞれまったく違う数字が入っていますが、3つとも完全にリンクしています。
そして、この3つの中で一番重要なのは「V」です。Vはまさに「トークンに対応する画像データ」なのです。
Attentionブロックの仕事
Stable Diffusionには「Attentionブロック」というモジュールが16個も使われています。たくさんありますが、どれも働きはだいたい同じです。画像生成では1ステップごとにこの16個のモジュールが順に実行されて、だんだん絵ができてきます。
Attentionブロックには以下の2つの情報が入力されます。
上でも説明したように、トークンはそれぞれQ、K、Vベクトルになっています。これを画像に取り込みたいのですが、そのためにAttentionブロックは生成途中の画像もそれぞれのマスごとにQ、K、Vの3つのデータに分裂させます。
つまり、Attentionブロックでは「トークンのQ、K、V」と「画像のQ、K、V」の合計6つのデータが現れるのです!しかし、これらを全部使うわけではありません。使うのは「トークンのK、V」と「画像のQ」の3つだけです。
さて、トークンの情報を画像に取り込みます。
トークンのKとVはガッチリとペアになっています。Kは箱に貼ってあるラベルのような役割を果たし、Vは箱の中身です。画像のQは「ほしいものリスト」のようなものです。つまり、画像のそれぞれのマスが「こんなトークン欲しいな」というリストを持っているわけです。
トークンはプロンプトごとに「トークン集」として1まとめで扱われます。いわばカタログです。
それぞれのマスはトークン集のK(ラベル)を見て、自分のQ(ほしいものリスト)と比べます。ほしいラベルが見つかったら、その本体であるVを取り込みます。そうして、画像のそれぞれのマスがトークンのVに染まります。もともと画像のマス自体も自分の「V」を持っていたのですが、トークンのVを取り込んだ後は元のVは完全に捨てられます。
Attentionブロックの処理によって、作っている途中の画像データは、トークンたちが持ってきたVのデータに完全に置き換わってしまうのです。
ちなみに、この一連の処理を「Cross Attention」と呼びます。
画像のそれぞれのマスすべてがこの処理を行っている、ということを覚えておいてください。
Attention CoupleでK、Qをすり替え
Attention Coupleの話に戻ります。
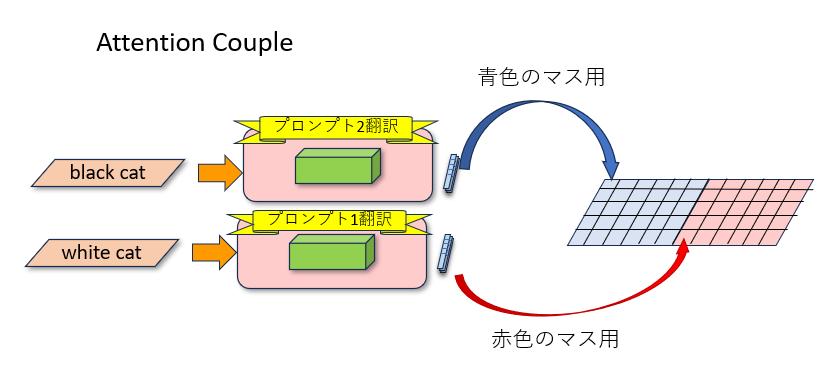
上で説明した通り、画像内のそれぞれのマスすべてがトークン集のK、Vを見るなら、それぞれのマスの場所ごとに違うトークン集を渡せば、違うプロンプトを違う場所に反映できます。トークン集(つまりプロンプト)がカタログなら、「この区画にはカタログ1を渡し、別の区画にはカタログ2を渡す」という感じです。
例えばプロンプトが左右2つ用意されたとします。それぞれのプロンプトからKとVのカタログが作られます(この処理は1回だけでオッケーです)。この2つのペア、「K左、V左」カタログと「K右、V右」カタログをAttentionブロックに渡します。すると作りかけの画像内のそれぞれのマスがカタログを見に来ますが、左側にあるマスは「K左、V左」カタログを、右側にあるマスは「K右、V右」カタログを見るようにします。
区画ごとに別々に1枚絵を描く必要がないのは、区画ごとに反映させるプロンプトを変えているからです。
どっちがいいの?
結局は用途によるところが大きいですが、継ぎ目が多少ぎこちなくてもちゃんとプロンプトどおりに詳細を描きたいならLatent Couple、より自然に見える絵を描きたいならAttention Coupleという感じです。別々の場所に別の個体を描きたいなら継ぎ目はあまり気にする必要はないでしょうが、たとえば「上半身」「下半身」というように同じ物体を区切りたいなら滑らかな継ぎ目も考慮する必要があるかもしれません。また、スピードは断然Attention Coupleの方が速いので、速度を気にされる方はAttention Coupleを選びましょう。
どちらを選んだとしてもStable Diffusionはなるべく矛盾のない絵を描こうと努力してくれますので、別々の絵をくっつけただけの画像よりもはるかによい結果を得られます。
まとめ
今回はリージョナルプロンプトについて解説しました。
Stable Diffusionで大きなサイズの画像を描こうとすると、構図や物体、人物の構造が破綻してしまう可能性が高くなります。これは、学習画像よりも大きな画像を描こうとすると、構造の繰り返し、いわゆる「カスケード」が起きてしまうからです。
リージョナルプロンプトを使うと、画像を小さく区切って区画ごとに描けるので、より破綻のない、思い通りの構図の絵が描けるようになります。ぜひ試してみましょう。