誰でもわかるStable Diffusion その11:VAE
前回の記事まではStable Diffustionの心臓部であるU-Netについて解説してきました。
ただのノイズから画像を作りだしていくのはU-Netの役割ですが、これだけでは画像は完成しません。
なぜならU-Netが作り出すものは「圧縮された画像」だからです。
絵を完成させるためにはこの圧縮された画像を展開して、元のサイズに戻す必要があります。
この、絵を圧縮したり展開したりする機能を「Variational Autoencoder」(ヴァリエーショナル・オートエンコーダー)、略して「VAE」と言います。
Stable Diffusionのしくみを語るとき、U-NetやTransformerに目が行きがち(Lora、Dreamboothなどの追加学習がU-Net対象なせいもあるでしょう)で、Stable DiffusionのVAEの機能は見落とされがちですが、それでも非常に重要なモジュールです。
今回はこのVAEについて見ていきます。
- VAEとは
- VAEの進化
- Stable DiffusionのVAEの特徴
- Stable Diffusionの潜在空間ってどうなってるの
- VAEエンコーダーは画像生成には不要
- VAEデコーダーのしくみ
- まとめ
VAEとは
私たちがふだん目にする画像は「ピクセル」で描かれた「ピクセル画像」です。
Stable Diffusionで作りたい画像も「ピクセル画像」です。
しかし、ピクセル画像は解像度が上がるたびにデータ量がどんどん膨大になり、大規模なマシンがないと計算できなくなってしまいます。
そこでStable Diffusionは画像を圧縮した状態でデータを作り、最後にVAEで展開してピクセル画像に変換して出力しています。
圧縮された画像のタテヨコのサイズはそれぞれ8分の1になります。
(ただし画像の場合はR、G、Bの3つのチャンネルを持っていますが、圧縮状態の画像はチャンネルが4つに増えます。)
圧縮前の画像と圧縮後のデータを比べると、データ量は48分の1になっています。
例えば512x512x3ピクセルの画像(最後の3はRGBチャンネル)を作りたい場合、生成される圧縮データのサイズは64x64x4です。
下の図はVAEの構造です。
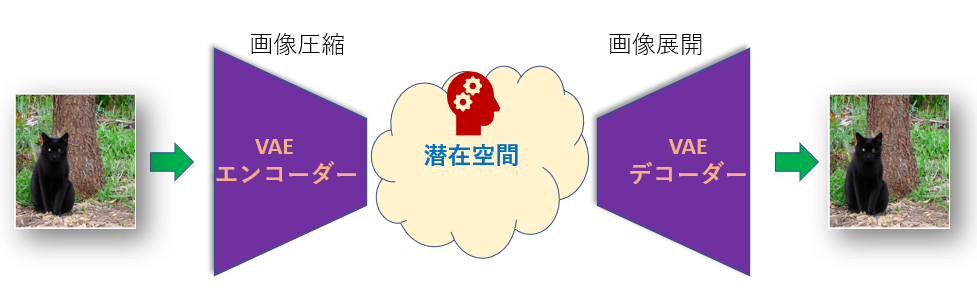
圧縮された画像は小さくなり、「Latent Space」(レイテント・スペース)、いわゆる「潜在空間」と呼ばれる情報空間に置かれます。
デコーダーは「潜在空間」にある画像を取り出して展開し、ピクセル画像に戻します。
VAEが作り出せるありとあらゆる画像データはこの「潜在空間」が保持しているわけです。
もともとVAEはStable Diffusionとはまったく別に提案された画像生成モデルです。
ここで、Stable Diffusionの構造を見てみましょう。

VAEの構造とよく似ていることがわかります。違うのは「潜在空間」の部分にU-Netが挿入されているところです。
つまり「Stable DiffusionはVAEの一種とみることもできる」のです。
U-Netは「潜在空間」で画像を作り出しますが、VAE的に解釈すると、U-Netは「潜在空間の中を泳ぎ回ってふさわしい絵を探し出す」という作業をやっていることになります*1。
VAEの進化
VAEは数年で何度も改良を重ねてきました。
画像を生成する技術として、まず「Autoencoder」(オートエンコーダー)というものが提案されました。これを発展させたものがVAEです。
さらにVAEを発展させたもののとして、Vector Quantized VAE、略して「VQ-VAE」が提案されました。
さらにさらに、QV-VAEを発展させたものとして「VQ-GAN」と呼ばれるものが登場しました*2。
VQ-GANは「VAE」という単語が抜け落ちていますが、VAEの一種です(正確にはVQ-VAE + GANです)。
Stable Diffusionで一般にVAEと呼ばれているものは、この「VQ-GAN」のことです。
これらすべて、「画像を圧縮、展開する」ことに関しては同じですが、画像の情報をどう保持するか、画像をどう復元、生成するか、という手法が違っています。
詳細は省きますが、VQ-GANはより精細な画像を生成できるとされています。

VAEは上の図のように機能が置き換わったり追加されたりする形で進化してきましたが、VQ-GANではU-Netでも使われているTransformerという仕組みが追加されたり、GANという画像生成メカニズムが追加されたり、まさに「いいところどり」な形態です。
これらの機能はVAEが学習して賢くなる時に特に大きな威力を発揮します。次のセクションではそれらについて概要だけ解説しますが、Stable Diffusionで画像を生成するだけならあまり意識する必要がないので、興味がなければ読み飛ばしてください。
Stable DiffusionのVAEの特徴
VAE(正確にはVQ-GAN)がどういうしくみなのか、具体的な特徴を見てみましょう。
ここで説明していることは主にVAEが画像を学習するプロセスです。興味ない方は読み飛ばしてもらっても構いません。
VAEは異次元世界への扉
絵をVAEエンコーダーに入れるとデータが小さくなりますが、この時、画像は「潜在空間」という異次元世界に飛ばされたと考えることができます。
画像は潜在空間に入ると、まず細切れに切り分けられます。そしてそれぞれの細切れが、それぞれ別の場所に置かれます。例えば、ある細切れが置かれた場所を住所で表すと「1丁目1番地1」だとします。少し短く書くと、[1, 1, 1]となります。
この「潜在空間の住所」こそが「圧縮されたデータ」です。もし細切れひとつが8x8ピクセルだったとする(簡単のため色はグレーのみとします)と、8x8=64個のデータが3個のデータに圧縮されたことになります。
画像を展開するときは、「潜在空間」の「1丁目1番地1」にある画像を現実世界に持ってくればよいのです。VAEデコーダーがその役割を担います。
潜在空間は区画整備されている
VAEエンコーダーを通して「潜在空間」に絵を入れたとき、絵の細切れを適当にバラまいてしまったら空間内がゴチャゴチャになってしまいます。「潜在空間」は無限に広がる膨大な空間ですが、だからといって絵の細切れを適当に放り投げて適当に住所を割り振っていくのは賢い方法とは言えません。
ちなみにVAEの先祖にあたるAutoencoderは実際そんな感じで適当に絵を潜在空間に突っ込んでいました。)
絵を機能的な形で潜在空間に置くために、以下のような整備計画を立てます。
- 同じような特徴を持つ細切れは近い場所に置いて、特徴ごとにまとまるようにする。
- デタラメに住所の数字を発行せず、有効な数字をあらかじめ決めておいて、その住所しか使えないようにする。
- 似たような細切れは1つにまとめる
これらに従って転送されてきた細切れを整理していくと、潜在空間内もスッキリして、のちにここから絵を復元するときに効率よく復元できるようになります。
3つ目の項目に注目してください。もし入ってきた細切れがすでに存在する細切れに似ている場合、すでに存在する細切れで代用します。
代用なので、オリジナルとは違うものになります。しかし、汎用性を上げる(いろいろな絵を効率的に保持できるようにする)ために、ある程度のロスは許容します。
「贋作師」と「鑑定士」が腕を競い合う
さて、潜在空間に入ってきた絵は細切れにされますが、細切れをつなぎ合わせれば理屈としては再び絵になるはずです。しかし、上で書いた通り、細切れの情報はオリジナルとは違っています。オリジナルとは違うものをつなぎ合わせて作る絵は、いわば「贋作」(ニセモノ)です。
元の絵を作る時はこれらの細切れを「現実世界の絵」に修復して、絵にします。
こうした、いわば「贋作師」の仕事をするのがVAEデコーダーです。
一方、現実世界(つまりVAEデコーダーの処理後)に「鑑定士」(Discriminatorと呼ばれます)を配置しておきます。この「鑑定士」は送られてきた絵が本物かニセモノかを細切れごとに鑑定し、「本物」「ニセモノ」のラベルをつけていきます。
学習の最初のうちは「贋作師」は未熟なので、「鑑定士」にすべて「ニセモノ」と見破られてしまうでしょう。「贋作師」はこの結果をもとに少し学習します。すると、次に作った絵は少しだけ「鑑定士」をだませるかもしれません。「贋作師」はさらに学習して腕を上げようとします。「鑑定士」のほうも負けじと少し学習してニセモノを見破る技術を上げます。
こうして「贋作師」と「鑑定士」が競い合うようにして腕を上げていき、ついには「贋作師」(つまりVAEデコーダー)が本物と見分けがつかないような絵を作り出せるようになります。
この贋作師と鑑定士が競い合って生成画像のクオリティを上げていく方法を「GAN」(Generative Adversarial Network、ギャンと発音されることが多いです)といいます*3。

本来、GANはVAEとは全く別に提案されたメカニズムです。
「VAEとGANを一緒に使ったらいいものができるんじゃないか」という発想で生まれたのがVQ-GANです。
Stable Diffusionの潜在空間ってどうなってるの
VAEの仕組みの概要を説明しましたが、実際Stable Diffusionの潜在空間のデータがどうなっているのか見てみましょう。
Stable Diffusionに以下のネコの画像を生成してもらいました。

サイズは512x512ピクセル、色チャンネルはRGBの3チャンネルです。
この画像のデータは潜在空間ではどうなっているのでしょう?
上でも解説した通り、潜在空間では画像データは圧縮されているのですが、強引に画像として出力してみると…

左は全チャンネル合成、右はCYMKチャンネルとして出力
思ったより画像っぽい?
タテヨコサイズは8分の1(64x64ピクセル)、チャンネルは4つです。
圧縮データとはいうものの、ネコの形も木の形もはっきり分かって、結構画像っぽいですね。
これを見ると、「画像をデザインするのはVAEでなくU-Net」だということが分かります。
ちなみに、潜在空間の各チャンネルを別に画像として表示させると以下のような感じ。

何となーく規則性が見えるような気がします。
VAEエンコーダーは画像生成には不要
上で書いた通り、VAEは「エンコーダー」と「デコーダー」でできているのですが、画像生成の時は「エンコーダー」は使いません。
今までの記事を読まれた方は、「画像を作る時にまずノイズ画像を用意するんじゃないの?」と思われるかもしれませんが、ノイズ画像は潜在空間で作られるのでVAEエンコーダーは必要ないのです。
つまり、例えば512x512ピクセルの画像を生成したい場合、512x512ピクセルのノイズ画像を用意してから潜在空間のデータに圧縮するのではなく、初めから潜在空間で64x64マスのノイズ画像データを作ってしまいます。
というわけで、エンコーダーは使用しないので説明は省略して、デコーダーの解説をします。
VAEデコーダーのしくみ
さて、潜在空間のデータはもう十分画像っぽいので、単純に8倍に拡大すればもう普通の画像になりそうなものですが、当然そんなに簡単ではありません。
具体的にStable Diffusionがどうやって潜在空間のデータを画像に戻しているのか見てみましょう。
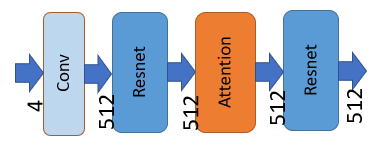
上の図は、VAEデコーダーが最初に行う処理です。矢印の下に書かれた数字は画像データの特徴チャンネルの数です。
U-Netの処理を終えた画像データは4つの特徴チャンネルを持っています。このデータがVAEデコーダーに送られ、VAEの処理が始まります。
まず、畳み込みを行います(畳み込みについては過去の解説を見てください)。
補足:
畳み込み前のチャンネルは4、畳み込み後のチャンネルは512です。ここで画像データから512個の特徴が取り出されたことになります。
次に「Resnet」、「Self Attention」、再び「Resnet」という3つの処理が行われます。
ResnetやAttentionはU-Netでも出てきましたのでリンク先の過去の記事を参考にしてください。Resnetは「特徴データの処理」、Attentionは「画像内の他の場所との関係を考慮したデータ変換」を担います。
U-Netのブロックとは詳細な処理内容は微妙に違いますが、やっていることはだいたい同じです。
次にデータは、たくさんの「Resnet」の流れ処理の中を通ります。

Resブロックと拡大の繰り返し
矢印の上に書かれた数字は画像データの特徴チャンネルの数です。
「Resnet」というブロックが12回繰り返し処理を行っていることが分かります。
そして、Resnetが3回処理を行うごとに「Up」ブロックがタテヨコサイズを2倍に拡大しています。
この「Up」ブロックでは、非常に単純な拡大を行い、そのあと特徴チャンネル数の変わらない畳み込みを1回行います。
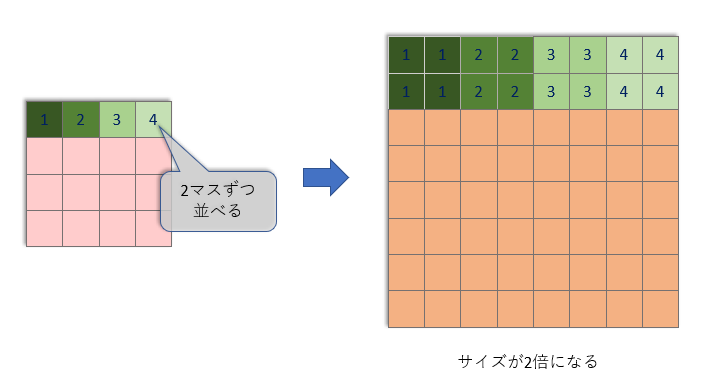
しかし、こんな単純な拡大(と畳み込み)だけでは、ぼんやりとした、色の薄い画像になってしまいます。
そこで、「Resnet」ブロックが「ぼんやりとした小さな画像」から「精細で大きな画像」を作り出す役割を果たします。この記事の上の方で書いた「贋作師」の仕事です。
上の流れ図を見ると、Upブロックを2回通った後で、特徴チャンネル数が減っていくことが分かります。特徴チャンネルを512チャンネルからだんだんまとめていき、最後には128チャンネルにまでまとめます。
そして、128チャンネルにまとまった画像データ(サイズはこの時点ですでに最終画像サイズになっています)は下の図で示された最終処理に送られます。

「Group Norm」では、128の特徴チャンネルは32チャンネルずつ、4グループに分けられ、グループごとに正規化されます。
「SiLU」は「非線形な要素」を入れるために使われます。
これらについて詳しく知りたい方は、過去の記事をご覧ください。
最後に畳み込みを行って128の特徴チャンネルをRGBの3チャンネルにまとめます。
以上がVAEデコーダーの変換処理です。
「潜在空間のデータを展開」と聞くと何か特殊な処理に聞こえますが、実際のところ畳み込みを繰り返して特徴をまとめ上げていく処理を行っているだけで、何も特別なことはありません。
まとめ
Stable Diffusionは「潜在空間」と呼ばれる圧縮された状態で画像生成を行います。
このおかげで大きなサイズの画像も比較的軽い処理で生成できます。
画像を潜在空間上のデータへ圧縮したり、逆にデータを展開して画像に戻す処理は「VAE」が行います。Stable DiffusionのVAEは「VQ-GAN」という手法を使っています。
画像を生成するときに使われるのは「VAEデコーダー」ですが、これは連続する畳み込み処理の集合にすぎません。
指定された絵を描き出していくのは主にU-Netが行いますが、潜在空間で作り出された画像データが最終的にきれいに出力されるには、VAEの処理も非常に重要なのです。