誰でもわかるStable diffusion その5:U-Net(IN0ブロックと畳み込み)
Stable Diffusionで使われるU-Netの最初のブロック、IN0層についての説明です。

IN0ブロックのやっていること
IN0ブロックは、最初に画像を受け取るブロックです*1。
画像は圧縮され、タテヨコがそれぞれ8分の1の大きさになっています。例えば512x512ピクセルの画像を描きたい場合、IN0ブロックには64x64のデータが入力されます。768x512ピクセルの時は96x64のデータが入力されます。
受け取って最初に行う処理が「畳み込み」(Convolution)です。畳み込みとは、簡単に言えば「特徴をサーチする処理」です。IN0ブロックはこの畳み込みを一回だけやって、処理後のデータを次のブロック(IN1ブロック)に送ります。
畳み込み処理とは
ここで使われる畳み込みを絵で表したのが下の図です。
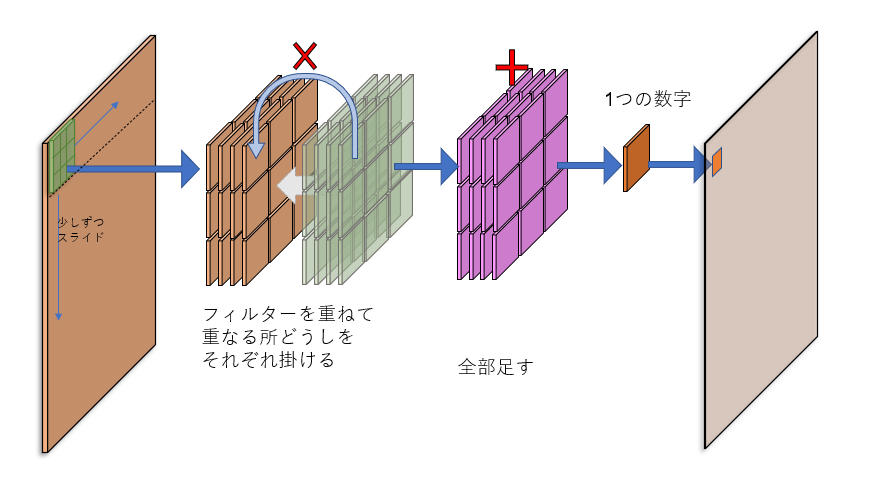
左の茶色い板はU-Netに入力した画像を表しています。板に厚みがあるのは、この画像が4つの「チャンネル」を持っているからです(本来画像はR、G、Bの3つのチャンネルを持っていますが、Stable Diffusionが画像を圧縮して処理する都合で、チャンネルが4つになっています)。
さて、畳み込みはこの画像の持つ特徴をサーチしますが、サーチするうえで重要になるのが「フィルター」の存在です(カーネルと言われたりもします)。図の緑色のパネルがフィルターで、大きさは3x3マス、厚さは4チャンネル(つまり入力画像と同じ厚さ)です。フィルターの厚さは必ず入力画像と同じでなければなりません。
このフィルターを、画像に重ねます。画像左上の3x3マスを見てみましょう。それぞれのマスはひとつの数字を持っています(デジタルデータはいつもそうです)。フィルターをそこにピッタリ重ねたら、重なったマスの数字どうしを掛けます(上の図の左から2番目)。
数字を掛けたら(上の図の紫のパネル)、これらのマスの数字を全部足します。そうすると、最終的には1つの数字が出てきます。
この数字こそが「その部分がどれだけフィルターに似ているか」を表す数字です。フィルターを重ねた画像部分がフィルターに似ていれば似ているほど数字は大きくなります。「似ている」というのは、つまり「フィルターの特徴をその部分が持っている」ということです。
このフィルターは画像の上を少しずつスライドし、左上から右下まで画像をくまなくスキャンします。それぞれ出てきた数字を並べていくと、スキャンした画像と同じ大きさの「特徴マップ」が完成します。
フィルターは「特徴発見機」で、畳み込みは「特徴サーチ」なのです。
畳み込みの具体例
まだ分かりにくいかもしれないので、例を挙げます。
ここでの例では、圧縮していない画像を入力に使います。シンプルにするためにチャンネルの数は1つにします。
「タテ線発見機」というフィルターを使ってみましょう。3x3マスの真ん中にタテ線が1本走っています。つまり、真ん中のタテ3マスが「1」で、あとのマスは「0」です。

さて、入力画像の中にタテ線があるとします(上の図の茶色のパネル)。ここにタテ線発見機フィルターを重ねて畳み込み(重なった所をかけて、全部足す)をすると「3」という数字が出てきます。重ねた部分がタテ線発見機に似ていたので、大きい数字が出てきました。つまり、「タテ線を発見した」のです。
では、斜め線があるところにこのタテ線発見機フィルターを重ねると…

最終的には「1」という数字が出てきます。ど真ん中のマスしか重ならないので、小さい数字になります。この斜め線を発見するには、「斜め線発見機」フィルターを新たに作らなければなりません。
IN0ブロックは320個の特徴発見機
IN0ブロックは、フィルターを320個持っています。つまり、320個の特徴を発見できます。
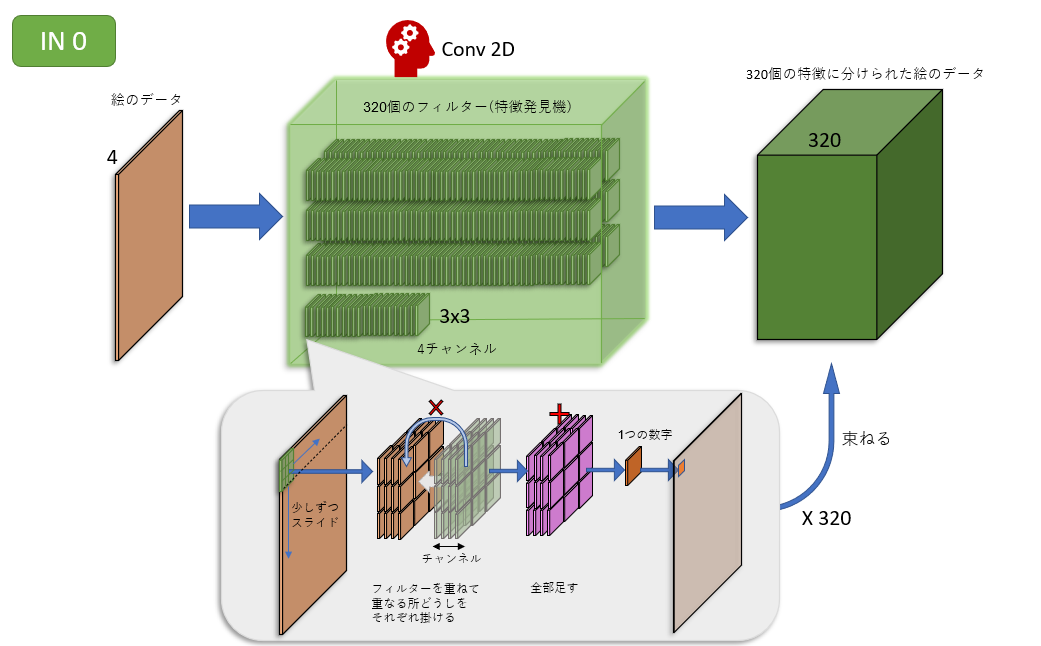
入力したときは4チャンネルだった画像が、出てくるときには320チャンネルに増えています。ちなみにタテヨコのサイズは変わりません。
つまり、チャンネルとは特徴のことです。タテ線に特化したチャンネルもあれば、ヨコ線に特化したチャンネルもあるでしょう。その他いろいろな特徴が320個、IN0ブロックからまとめて出てきます。
「そんなたくさんの特徴って、具体的に何?」と思われるでしょう。それは分かりません。人間が特徴を具体的に指定するのではなく、ニューラルネットワークが学習を通して320個の特徴発見機を改良していくからです。
上の図の中にある「歯車のついた頭のアイコン」は、そこが「学習を通して賢くなる」事を表しています。最初は全然絵の特徴をつかめないかもしれませんが、何度も学習を重ねるうちに、うまく絵の特徴を捉えられるようになります。
Stable Diffusion用に公開されている「モデル」と言われているものは、学習後のフィルターの情報を含んでいます。フィルターの種類が変われば発見できる特徴の種類も変わり、結果的に描かれる絵の特徴も変わります。
まとめ
IN0ブロックはU-Netの最初の処理を行う場所です。ここでは畳み込みが行われ、画像から320個の特徴が抽出されます。
ここで抽出されたデータは次のブロックへ送られ、さらに多くの特徴が抽出されていきます。
U-Net内では畳み込みが何度も行われますが、しくみは基本的に同じなので、ここで畳み込みを理解しておけばU-Netの理解が楽になると思います。
*1:実際のStable DiffusionはLatent Spaceという画像圧縮を使うので、厳密には画像データではありませんが。