誰でもわかるStable Diffusion その8:AttentionとTransformer
前回はU-Netの「テキストを取り込む」機能であるAttentionブロックを見ましたが、その中で特に大切な「Attention」パートについては概要しか説明しませんでした。
今回はそのAttentionについて詳しく見ていきますが、その前にAttentionを行うメカニズムである「Transformer」についても少し説明します。
- はじめに:Attentionさえあれば
- Transformerのしくみ
- Attentionとは
- Stable DiffusionのSelf Attention
- Stable DiffusionのCross Attention
- まとめ
はじめに:Attentionさえあれば
2017年のことでした。グーグルの研究グループからある論文が発表されます。

タイトルは「Attention Is All You Need」、邦題をつけるなら「アテンションさえあれば」という感じです。ビートルズの曲名「Love Is All You Need」を意識してつけられたのでしょう。
ここで「Attention」という概念と「Transformer」というメカニズムが提唱されました。
文の中の言葉は1つ1つ独立しているわけじゃなく、お互いの関係や順番によって意味合いが変わります。だから言葉どうしや対になる文(翻訳など)との関係に注意を向けて(Attention)、それぞれの言葉が文中でどういう意味合いを持っているかを調べることが重要です。
この処理を行うことができる「Transformer」というアーキテクチャを提案します。
この論文は言葉を扱う人工知能の世界に革命を起こします。Transformerがあまりにも優秀だったため、あっというまに既存のメカニズムにとって代わり、2023年現在ではほとんどの人工知能がTransfomerを何らかの形で使用しています。
今話題のChatGPTもこれを使っています。
Transformerは最初は言葉を扱うために提案されたものですが、のちにこれが他のモダリティ、例えば画像や音声の処理にも使えることが分かってきました。
Stable Diffusionは「言葉と画像を比べる」処理にTransformerを使っています。
Transformerのしくみ

Transformerのしくみ
Stable Diffusionの画像処理では右側だけ使っています
上の図は論文の中で説明されたTransformerの中身ですが、左右二つのパーツで構成されていることが分かります。左のパーツは「エンコーダー」、右のパーツは「デコーダー」と呼ばれます。
Stable Diffusionでは、左側のエンコーダーは「入力されたテキスト(プロンプト)」の処理を行い、右側のデコーダーが「テキストを取り込んで画像を書き換える」処理をしています。
エンコーダーブロック
エンコーダーがやっているのは、「テキスト内の単語(トークン)を数字(ベクトル)に変換すること」です。
テキストデータは人工知能にとって扱いづらいので、数字化するのです。
ただし、ただ単純にトークンを決められたベクトルに変換するのではなく、テキストの中でそのトークンがどういう意味合いを持っているかを考慮して、それに見合ったベクトルを作り出しています。
この「トークンにふさわしいベクトルを作る」部分でAttentionが行われます。
ただ、Stable Diffusion自体はテキスト変換処理をやっていません。
よその処理プログラムを流用しているだけで、Stable Diffusionはエンコーダー部分にはノータッチなのです。
そのため、Stable Diffusionに画像やキャプションをどれだけ学習させても、テキスト処理は賢くなりません。
(ちなみに、学習しても賢くならないパーツは俗に「固まっている」(Frozen)と呼ばれたりします)
ほかのStable Diffusionの解説記事で「Text Encoder」(テキストエンコーダー)というパーツを見かけることがあると思いますが、まさにそれがここでいうエンコーダー部分です。
デコーダーブロック
デコーダーブロックはStable Diffusionが使っている部分です。
上の図はちょっと難しいので理解する必要はありません。
下の図はStable Diffusionの心臓部、U-Netの中にある「Attentionブロック」の構造ですが、これがTransformerのデコーダーブロックとほぼ同じことをやっています。

本質的にはTransformerのデコーダーと同じ
Attentionブロックに関しては前回の記事を参考にしてください。
ここで最も重要な処理は「Self Attention」と「Cross Attention」です。
Attentionとは
では、いよいよAttentionについて詳しく見ていきましょう。
まず、Cross AttentionとSelf Attentionが何をしているかをたとえで説明してみます。
Attentionについて分からなくなったら例えを(もし参考になるなら)参考にしてください。
Cross Attentionを婚活に例えると
あなたが結婚相談所に登録するとします。
そこには3人のアドバイザー、Qさん、Kさん、Vさんがいます。
- Qさんはあなたに「相手に対する希望」をまとめるためのアドバイスをします。
- Kさんはあなたに「自分のプロフィール」をまとめるためのアドバイスをします。
- Vさんはあなたに「相手に見せたい自分自身」を準備するようアドバイスします。
3人のアドバイザーはとても優秀なので、相談所のメンバーは絶対にウソをつけません。そうしてメンバー全員、完璧に準備を整えます。
さて、あなたは「相手に対する希望」(仮にQ文書と呼びます)と候補者から送られてきた「プロフィール」(仮にK文書と呼びます)を比べます。
自分のQ文書と相手のK文書がよくマッチする候補者もいれば、ほとんどマッチしない候補者もいるでしょう。とにかく候補者全員のK文書と自分のQ文書を比較します。
比較した後で、相談所主催のイベントに出席して候補者全員と会うことにします。
あなたは自分のQ文書とよくマッチしたK文書を持つ候補者を重要視し、「よく知りたい」と思うでしょう。逆にそれほどマッチしなかった候補者にはあまり関心を示さないでしょう。
実際に会ってみると、候補者たちはVさんのアドバイスに従って「相手に見せたい自分」(仮にVと呼びます)をあなたに見せてくれます。
イベント終了後、あなたは候補者たちについて思い返します。
QとKがよくマッチした候補者の印象Vが、あなたの心に強烈に焼き付いています。あまりマッチしなかった候補者のことは、ほとんど忘れているでしょう。
もし同じぐらいマッチした候補者が2人いたら、その2人の印象Vが半分ずつ混ざり合って心に残ります。
こうして、あなたの心に「混ざり合ったV」が生まれるのです。
Cross Attentionの目的は、この「混ざり合ったV」を生み出すことです*1。
Self Attentionを婚活に例えると
さて、前の例えでは「自分の希望」と「婚活相手のプロフィール」を比べました。
しかし、あなたはこの相談所にいるライバル(つまり同性)たちのプロフィールも気になっています。
あなたにとってより理想的なプロフィールを持ったライバルを真似たいものです。
そこで、あなたはアドバイザーにそのことを相談します。
するとアドバイザーQさんが「では、なりたい自分についてまとめてみましょう」と言いました。あなたは「なりたい自分」を正直に書き出し、まとめます(今回はこれをQ文書と呼びます)。
「なりたい自分」を書き出した後、ライバル全員の「プロフィール」(K文書)と比べます。QとKがよくマッチしたライバルのことは結構気になります。
さて、イベントであなたはライバル全員を見かけることになります。QとKがよくマッチしたライバルがいたら、その人物が持つ「見せたい自分」(V)をよく観察します。あまりマッチしなかったライバルについてはそれほど観察する必要はないでしょう。
イベント後、ライバルたちについて思い返します。参考にすべきVは大いに参考にし、あまり興味のないVはほどほどに、そうして自分の中で「混ざり合ったV」を作り出して自分磨きに使います。
Self Attentionも結局はこの「混ざり合ったV」を作るのが目的です。
CrossとSelfの違いは、「誰と比較するか」ということだけです。
ただしCross Attentionのアドバイザー3人とSelf Attentionのアドバイザー3人は別人であることに注意してください。
Stable DiffusionのSelf Attention
以上の例を踏まえて、Stable DiffusionのAttentionがどういう処理をしているか見ていきましょう。まずはSelf Attentionから。
以下はIN1ブロックのSelf Attentionの説明です(ブロックが変わるとデータのサイズが変わりますが、行う処理は一緒です)。
入力される画像のサイズは、ここでは64x64とします。これは320個の「特徴チャンネル」を持っています。
1.データをフラットに
まず、このデータを平べったくします。64x64x320の3次元データを4096x320の2次元データに再構成します。積みあがったブロックを平べったく並べ替えるだけです。

これをAttention処理に入力します。

2.マルチヘッド化
平べったくなった画像データを3つに複製します。それらをそれぞれ、タテに8つ*2に切り分けます。
ここでは、40個の特徴チャンネルごとにグループ分けされたことになります。
以降、これら8つのデータは別々に処理されます。複数に切り分けて別々に処理する仕組みを「Multi Head Attention」と呼びます。
3.Q、K、Vに変換
この後の処理が非常に重要です。
複製されたデータはそれぞれ別のニューラルネットワーク(歯車のついた頭のアイコン)を通り、クエリ(Q)、キー(K)、バリュー(V)というデータに変換されます。これら全部、変換前と変換後のサイズは同じ(4096x40)です。
- Qは比較するためのデータ
- Kは比較されるためのデータ
- Vは置き換え用のデータ
です。
4.QとKを比較
変換後、すべてのマス(4096個)同士で自分のQと相手のKを比較します。比較するとは、数学的に言えば「内積を計算する」ということです。
内積を知りたい人向け:計算法は以下の通りです。
今回は、それぞれのマスが40個の数字を持っています。マス1とマス2を比べたい場合、それぞれが持つ40個の数字を重ね合わせ、重なる数字どうしを掛け、それらを全部(40個)足します。
計算結果として、1つの数字が出てきます。
40個の数字の並びが似ている場合、計算結果は大きな数字になります(本質的には畳み込みと同じです)。
こうして、それぞれのマスが(自分自身も含め)すべてのマスと比較した結果、4096x4096の比較マップが出来上がります。
これはエクセルの表と同じです。行が自分のマス、列が比較対象のマスを表し、それぞれのセルの中の数字が「どれだけ関係が深いか」を表します。
この中に入っている数字が大きいほど「そのマス同士の関係が深い」ということになります。
次に比較マップ内の数値を小さくします。
今回、各マスが持っている数字(特徴)は40個の数字ですが、これが80個、160個…と増えていったら、比較マップの中の数値もどんどん大きくなります。なので、比較マップ内の全部の数字を特徴数に応じて割り算することで、数値を一定範囲に抑えます。
具体的には、特徴数の平方根で割ります。
数字を一定範囲に抑えたら、今度は正規化します。
これには「SoftMax」という方法を使います。これによって比較マップ内の全ての数字が0から1の範囲に収まり、しかも同じ行の数字をすべて足すと必ず1になります。
SoftMaxを知りたい人向け
同じ行のすべての数を指数関数に代入し、この結果を使って同じ行内で正規化します。
つまり、数字が大きくなればなるほど指数関数的に重みが増えます。
5.Vを重み付けて足す
さて、いよいよ最後です。これが最も重要な処理です。
上の図のVの処理を見てください。Vは4096x40のデータです。このVこそが「元のデータに置き換わるデータ」です。
具体的には、比較マップとVデータを掛け算します。
行列計算を忘れてしまった人向けに説明すると、4096x4096のデータと4096x40のデータ掛け算すると、結果は4096x40になります。
Vデータ内の4096行すべてが足しこまれるのですが、ここで、比較マップはVデータのそれぞれの行を「重み付け」する役割を果たしています。
つまり、関係の深い行はより多く、関係の薄い行はより少なく、足しこみます。
上の婚活の例えでいえば「混ざり合ったV」を作る作業です。
6.マルチヘッドを再結合

上のQ、K、V処理はヘッドごとに別々に行われます。処理後、それぞれの結果をまたくっつけて、8つの4096x40のデータを1つの4096x320のデータに戻します。
これでSelf Attention処理は終了です。出てきたものは「混ざり合ったV」です。
つまり「Vこそが新しいデータの本体」なのです。
Stable DiffusionのCross Attention
Cross Attentionもやっている処理自体はSelf Attentionとほとんど同じですが、扱うデータが違います。
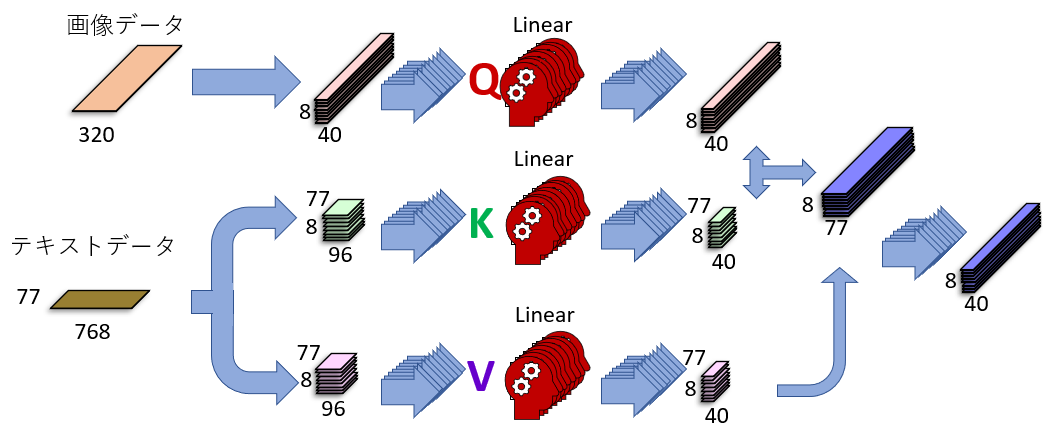
上の図を見てください。KとVがテキストデータから来ていることが分かります。
以下でSelf Attentionの違いを見ていきましょう。
テキストは75トークンごとに処理
Stable Diffusionではテキスト(プロンプト)の長さに上限はありませんが、処理される時は75トークンごとに切り分けられて、それに開始記号と終端記号が足され、合計77トークンをひとまとめとして処理されます。
プロンプトが短く、例えば3トークンしかない場合も、余白のトークンは終端記号で埋め尽くされ、必ず77トークンのデータとして処理されます。
75トークンごとに切り分けられた時、別々のトークングループに入ってしまった単語は関係が完全に切れてしまいます!関係を持たせたい単語はプロンプト内で近くに書きましょう。切り分け場所も意識する必要があるかもしれません。
各トークンは768個の特徴数を持っています。つまり入力されるテキストデータのサイズは77x768です。
上でも書いた通り、このデータを作るのはStable Diffusionではありません。
テキストから数字データへの変換はほかの処理系が行います。
テキストK、Vはサイズが変わる
画像データもテキストデータもマルチヘッド化で8つに切り分けられます。画像データは4096x320が8個の4096x40に、テキストデータは77x768が8個の77x96に分割されます。
その後、画像データはQ、テキストデータはKとVに変換されます。
Qに変換された画像データはサイズが変わりませんが、KとVの場合、変換前のテキストデータサイズ77x96がニューラルネットワークによる変換後には77x40に縮小されています。
なぜこんなことをするのかというと、画像由来のQとサイズを合わせるためです。
比較するためには(行列計算の性質上)特徴数を同じにする必要があるので、テキストデータの特徴数を96から40に圧縮しています。
画像のQとテキストのKを比較する
画像とテキストで特徴数が一致したので、比較することができます。
画像は4096マス、テキストは77トークンなので、比較マップは4096x77になります。
この比較マップが「それぞれのトークンが画像の各マスとどれほど深い関係を持っているか」を表しています。
Self Attentionと同じように、Cross Attentionでも比較マップを正規化します。正規化後の比較マップはVを重み付けする役割を担っています。
出力データは入力データとサイズが同じ
比較マップとVを掛け合わせ、重み付けされたVを足し込んで出力します。
ここでのVはテキスト由来です。テキストのVのサイズは77x40なので、比較マップ4096x77と掛けると出てくるデータのサイズは4096x40になります。これは入力データのサイズと全く同じです。
最後に8つのヘッダをくっつけて、4096x320にします。
これでCross Attention処理は終了です。出てきたものは「混ざり合ったV」です。
テキスト由来のデータが画像に埋め込まれる
ここでも「Vこそが新しいデータの本体」ですが、注目すべきは「Vがテキスト由来」という点です。
つまり画像データがテキストデータに置き換わっているのです!
厳密にはこのあと「処理前の画像データ」が足される(上の「Transformerブロック」セクションにある「Attentionブロック」図の茶色矢印)ので、画像データが完全になくなるわけではありませんが、それでもデータの一部はテキスト由来になります。
この処理でいかにテキストが画像に影響を及ぼすかお分かりいただけると思います。
まとめ
少し長くなりましたが、Attentionについて詳しく見ました。
Attentionを行うためのメカニズムが「Transformer」とよばれるアーキテクチャです。Stable Diffusionではこのうちのデコーダー部分を使って画像を処理しています。
デコーダーでは「Self Attention」と「Cross Attention」の二つの処理を行いますが、Self Attentionは画像のマス同士、Cross Attentionでは画像のマスとテキストをそれぞれ比較し、関係の深いデータをより重視して新たなデータを作り出します。
とくにCross Attentionでは画像データがテキスト由来のデータに置き換わるので、ここで画像にテキストを反映させています。