誰でもわかるStable Diffusion CFGスケールのしくみ
このブログでは人工知能全般について書くつもりでしたが、結局今までStable Diffusionのことばかり書いています。画像生成AIは今とてもホットな話題なのでしばらくはStable Diffusionの記事ばかりになるかもしれません。
※何か解説してほしいことのリクエストあればコメントで教えてください。
今回は「CFGスケール」について解説します。
AI画像生成ツールは現在「Stable Diffusion Web UI」をはじめいくつか出回っていますが、どれも「CFGスケール」という設定を持っています。これはいったい何なのでしょう?

これは一体何?
CFGスケールの大ざっぱな説明
Stable Diffusionの解説サイトに書かれているCGFスケールの説明はだいたい以下のようなものです。
- CFGスケールとは、「生成する画像にプロンプトをどれだけ強く反映するか」を決める値のこと。
- CFGスケールの値を大きくすればするほど、Stable Diffusionはよりプロンプトの文章に忠実に絵を描こうとする
- CFGスケールの値が小さいと、Stable Diffusionはよりプロンプトに縛られない創造性の高い絵を描こうとする
- CFGスケールを高くしすぎると絵のクオリティが下がる
- CFGスケールを低くしすぎるとプロンプトと違う絵になる
CFGスケールの値は大きすぎても小さすぎてもダメで、最適な値は一般的に「7~10」とされています。また、サンプリングステップ数を上げることによって高CFGスケールでも画像が破綻しづらくなる可能性があります。
絵を生成したいだけなら、この説明だけで十分です。
しかし、具体的なしくみを知りたい方は、以下の解説を読み進めてください。
CFGスケールの具体的な説明
解説の前提知識
解説をシンプルにするため以下のような前提を設けます。
- 解説に出てくる画像はすべて2ドットでできている
- 画像には色がなく、グレースケールで描かれる
- 画像生成は「Latent space」でなくピクセルそのままで行われる
普通の画像は512x512ピクセルといったサイズですが、この記事中の「画像」はたったの2ピクセルしかありません。しかも、画像はグレースケールです。
Stable Diffusionは本来は画像を「圧縮」された状態で生成して、最後にデータを「展開」して画像に戻す、という処理をしています。この「圧縮」状態を「Latent space」といいます。しかし本記事の画像は2ピクセルしかないので、「圧縮」せずにピクセルのままの状態(Pixel spaceと呼ばれたりします)で生成を行うことにします。
理想の絵を求めてさまようAI
普通「絵を描く」といえば真っ白なキャンバスに色を乗せていく作業のことです。しかしStable Diffusionがやっているのはその逆で、適当な色でゴチャゴチャに塗られたキャンバスから色を取り除いていく作業をしています。最初のゴチャゴチャの色を「ノイズ」と呼びます。
今回はもう少し違う見方をしてみましょう。デジタル画像の場合、「色」とは「数字」です。例えばグレースケールでは0は真っ黒、255は真っ白の点を表します。
この数字を使って、2ピクセル画像を「2つの数字を持つベクトル」で表せます。
例えば、[0 0]とはどんな絵でしょう?これは2ピクセルどちらも真っ黒の絵です。[255 255]は真っ白の絵です。[127 127]なら白と黒の中間のグレーの絵に、[0 255]なら左側は真っ黒、右側は真っ白の絵となります。

では、画像を生成します。まずノイズだらけの絵を用意します。適当な数字を選んだら、[8 30]が出てきました。これを初期の「ノイズ絵」とします。ちなみに実際のStable Diffusionではこの適当な数字は「Seed」によって決まります。同じSeedを使えば毎回同じ数字が出てきます。
一方、あなたの描きたい絵は[200 180]だとします。意味の分からない絵ですがあなたにとってはこれが「理想の絵」だと思ってください。
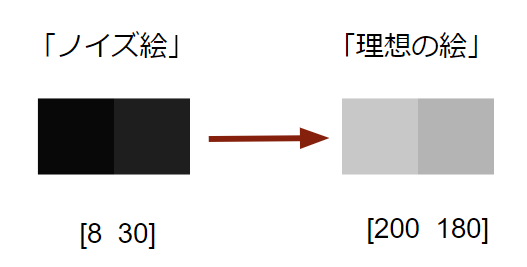
ノイズ絵と理想の絵は数字からできているので、それぞれをグラフに表してみましょう。

まるで地図のように見えると思います。
Stable Diffusionがやっているのは、スタート地点(ノイズ絵)からいろいろさまよってゴール(理想の絵)までたどり着くさすらいの旅です*1。この地図上のあちこちには画像が眠っていて、たとえば「ネコの絵ゾーン」があったり「イヌの絵ゾーン」があったりします。Stable Diffusionはある程度の絵の知識を持っているので、「あっちに行けば絵っぽいものがあるかな」というアタリをつけてそっちのほうに向かっていこうとします。しかし、そちらの方向が理想の絵に向かっているとは限りません。そこで、あなたはStable Diffusionに「正しい方向」を教えてやる必要があります。それが「プロンプト」です。ちょうどマップアプリの経路探索と同じようなものです。
良いナビと悪いナビ
上で解説した通り、あなたのプロンプトは理想の絵に向かうための「ナビゲーション」になります。その仕組みはこうです。
理想の絵を説明したプロンプトを打ち込むと、Stable Diffusionで使われている「テキストエンコーダー」がそのプロンプトを解読して数字に変換します。Stable Diffusionは変換された数字を見て、現在の位置と照らし合わせて、ゴールがどっちかを推測します。
もしあなたのプロンプトが完璧であれば推測ゴール地点はきっちり[200 180]を指し示すはずですが、そううまくはいきません。もしかしたら[165 140]あたりを指し示すかもしれません。ゴール地点とは程遠いですが、少なくともそちらの方向に向かえばゴールに近づくことはできそうです。それでもゴール地点とは違うので、ちょっとだけそっちの方向に移動して、移動した後にまたナビを見直すことにします。もし現在地と推測ゴールとの距離が[100 80]で、20分の1の距離だけ移動するとしたら、[100/20 80/20] = [5 4]だけ進むことになります。
移動後の地点は少しゴールに近寄っているので、そこでナビを見直したらもう少し正確なゴール地点の推測ができるかもしれません。
こうしてStable Diffusionはゴール地点を目指して少しずつ移動していくのです。

この「目標に向かって移動する」ことをStable Diffusionでは「サンプリング」といいます。「ナビを何回見直すか」を決めるのが「Sampling steps」です。「1度にどれだけ移動するか」を決めるのが「Sampling method」(またはスケジューラー)です。

一方、Stable Diffusionには「絶対に行ってはいけない方向」を指し示す「悪いナビゲーション」も存在します。それが「ネガティブプロンプト」です。ネガティブプロンプトもテキストエンコーダーに送られ、数字に変換されます。Stable Diffusionはネガティブプロンプトの数字を見て「あっちの方向には行っちゃダメだな」と判断します。
ちなみにネガティブプロンプトが空の場合、「悪いナビゲーション」は何かの絵がありそうな方角を適当に指し示します。何の絵かは分かりませんが、Stable Diffusionが知っている何かです。これが理想の絵である可能性は非常に低いので、やはりその方角も「行ってはいけない方角」です*2。
CFGスケールはブースター
試しに、悪いナビに従ったらどっちの方向に行くかを計算してみます。次の推測地点は現在地から[1 3]離れた距離を示したとします。すると[1 3]だけ移動することになります。
良いナビの移動距離は(上で計算したように)[5 4]でした。良いナビと悪いナビの移動の差を取ってみると
[5-1 4‐3] = [4 1]
となりました。
この良いナビと悪いナビの移動差が何を意味するかというと、「正しい方向に向かってネガティブプロンプトから離れる移動」、いわば「補正移動」です。良いナビに従う移動だけでなく、この補正移動も行うことで、より正しいゴール位置に向かうことができます。
この「補正移動」をどれくらい行うかを決めるのがCFGスケールなのです。

青矢印は「ゴール地点」へ向かう移動
今回の例では本来のゴール地点は[200 180]なのですが、ネガティブプロンプトを入れた影響でゴール地点がずれて[210 175]とかになるかもしれません。ネガティブプロンプト要素を絵から取り除くせいで絵が変わってしまうからです。「補正移動」はこのゴール地点を補正する意味合いがあります。
CFGスケールが1のときは、補正は行いません*3。
CFGスケールが増えるたびに補正移動にブーストがかかり、一度の移動距離が伸びます。「CFGスケール値-1」の倍数がブーストによる移動距離です。例えば補正移動距離が[4 1]でCFGスケールが値が3の場合、まず良いナビによる移動[5 4]を行って、そこからさらに[4x(3-1) 1x(3-1)] = [8 2]だけ補正移動を行います。
CFGスケールの最適値
CFGスケール値はどれくらいの値がいいのかは、どれほどプロンプトを重視したいかによります。上でも書いた通り、適正なCFGスケールは「7~10」とされています。Stable DiffusionのCFGスケールのデフォルト値は7です。「なぜ7なのか?」と思われるかもしれませんが、私にもわかりません…経験的に決められた値のようです。
プロンプトは通常いろいろな要素を詰め込むので、その要素すべてを絵に表現するにはどれか特定の要素だけをゴールにするわけにはいきません。
CFGスケールを上げると良いナビ(つまりプロンプトの指定)の方向に大きく移動するのでプロンプトが反映されやすくなりますが、ブーストをかけすぎるとピーキーになり、移動のたびにプロンプトのいろいろな要素にあちこち振り回されて絵が破綻してしまう可能性があります。「指定に一貫性のある美しいプロンプト」であれば、移動の方角がきれいに定まってCFGスケールを上げても破綻しづらくなるかもしれませんが、プロンプトのテキストが長くなると一貫性を保つのが難しくなります。
逆にCFGスケールを下げすぎるとなかなか理想のエリアに近づけず、プロンプトがあまり反映されないぼんやりした絵になってしまう恐れがあります。「7」というCFGスケール値はプロンプト要素のどれにも近すぎず遠すぎずちょうどいいバランスのようですが、「いまいちプロンプト通りに描いてくれない」と感じたときはCFGスケールを上げてみてもいいでしょう。
個人的な使用感を言うと、ある程度プロンプトを整理して書けばCFGスケールを20あたりまで上げても以外にも破綻なく描いてくれることが多いですが、値を大きくすると色飛びしたり細部がつぶれたりするので、上げるとしても20あたりが限界だと思います。
実際の画像生成はもっと複雑
上の例では画像が2ピクセルしかなかったので2次元の地図のように表すことができましたが、実際のStable Diffusionではもっと大きな画像を扱うので、次元数は比べ物にならないほど大きくなります。例えば512x512ピクセルの画像を生成するとき、次元数は16384次元!!これではもはや地図のような図で表すことはできません。
さらに、実際のStable Diffusionでの移動空間は「Latent space」とよばれる「圧縮空間」なので、各次元の数字も単純に「色の濃さ」を表すわけではありません。データを圧縮しないとデータが大きすぎてとてもPCで動かないので、仕方がありません。
しかし、「ナビを頼りに理想の絵に近づいていく」という処理やCFGスケールの基本的な考えは何次元であっても同じです。CFGスケールによって、ネガティブプロンプト画像エリアから離れてプロンプト画像エリアに近づくためのブーストをかけるのです。
まとめ
今回はCFGスケールについてまとめました。画像生成の時にはそこまで意識して設定することはないと思いますが、仕組みを知っておけばプロンプト指定と生成画像の関係性をより理解しやすくなるのではないかと思います。
誰でもわかるStable Diffusion テキストエンコーダー:CLIPのしくみ
以前の記事でStable Diffusionがどのように絵を描いているか順番に解説しました。
その中で特に重要な働きをするモジュール「テキストエンコーダー」については少し紹介しただけであまり詳しく解説しなかったので、今回はテキストエンコーダーについて少し詳しく見てみます。
テキストエンコーダーとは
テキストエンコーダーとは、その名の通り「テキスト」を「エンコード」(つまり変換)するモジュールです。
テキストとは、「picture of black cat」のような、人間が理解できる文章のことです*1。テキストエンコーダーはこれを「ベクトル」の集まりに変換します。
ベクトルとは数字の集まりです。通常は[0.5 0.2 0.3]のように数字をカッコでくくって、これを1つのベクトルと呼びます。カッコの中の数字の数は「次元」と呼ばれます。数字を3つ持つベクトルは「3次元ベクトル」です。次元が増えれば持てる情報量も増えます。

テキストエンコーダーがやってるのはこれだけ
なぜテキストをベクトルに変換するのかといえば、数字の方が機械にとって扱いやすいからです。数字であれば計算できます。また、絵とテキストをどちらもベクトルに変換すれば、それらが似ているか、違うならどれくらい違うか、などを数字で直接比較できるようになります。
Stable Diffusionでのテキストエンコーダーの役割
テキストエンコーダーはStable Diffusion内ではどういう風に使われるのでしょう?
Stable Diffusionは「プロンプト」と呼ばれるテキストをユーザーから受け取り、それをもとに絵を描きます。Stable Diffusionが絵を描くには、まずプロンプトに何が書かれているかをStable Diffusionが理解しなければいけません。Stable Diffusionが唯一理解できる言葉、それはベクトルです。つまりプロンプトをベクトルに「翻訳」する必要がありますが、Stable Diffusion本体にはその機能はありません。そこで、テキストエンコーダーにプロンプトを翻訳させるのです。
つまり、テキストエンコーダーはStable Diffusion自体の機能ではありません!そのため、テキストエンコーダーをどこか他から持ってくる必要があります。Stable Diffusionはそれを「CLIP」という別の仕組みから借りてきています。

CLIPは実際はテキストエンコーダーのほかに「イメージエンコーダー」(後述)を持っていますが、Stable Diffusionはテキストエンコーダーのみを利用しています。
ちなみにバージョン1系とバージョン2系のStable Diffusionは使っているテキストエンコーダーが違います。バージョン2系のテキストエンコーダーは「OpenCLIP」という、もともとのCLIPをさらにグレードアップさせたものを使っています。
CLIPとは
「CLIP」とは、「与えられた画像にテキストラベルをつけてクラス分けする」ために作られたモデルです。ChatGPTで有名なOpenAI社が2021年に発表しました。
例えば学習済み(つまり完成版の)CLIPにネコの絵を入れると、「cat」というラベルをつけてくれます。どんなネコの絵を入れても、だいたい「cat」というラベルをつけてくれるようになっています(もちろん完璧というわけではありませんが)。そのほか、学習したいろいろな画像をもとに、複雑な画像を的確にラベル付けしてくれる優秀なモデルです。

私はワカモレなんて知らなかった…
上でも説明した通り、CLIPは「テキストエンコーダー」と「イメージエンコーダー」からできています。テキストエンコーダーの機能は上で説明した通り、テキストをベクトルに変換することです。一方、イメージエンコーダーは画像をベクトルに変換する機能を持ちます。つまり、CLIPはテキストと画像の両方を読み込むことができるのです。
CLIPが賢くなるしくみ
さて、CLIPは他の人工知能と同じく、最初は何もできません。テキストも画像も何も知らないからです。そこで、賢くするために学習を行う必要があります。
学習には「テキストラベル付き画像」を使います。これを大量に読み込ませて、少しずつ賢くします。
学習は以下のような手順で行われます。
- 大量のラベル付き画像から決まった数だけランダムに取り出し、それらを1つにまとめる(ラベル集、画像集)。
- ラベル集をテキストエンコーダーに、画像集をイメージエンコーダーに入れる。
- テキストエンコーダーから、それぞれのラベルに応じたベクトル(テキストベクトル集)が出てくる。
- 同時に、イメージエンコーダーから、それぞれの画像に応じたベクトル(画像ベクトル集)が出てくる。
- テキストベクトル集と画像ベクトル集を比べる。ペアになっているラベルと画像のベクトルが似たベクトルとなるように、テキストエンコーダーとイメージエンコーダーを調整する。
- 大量の画像を使って学習を膨大な数繰り返す

しつこいようですが、CLIPはStable Diffusionではありません。CLIPの学習はStable Diffusionとは全く別に行われたもので、Stable Diffusionは学習済みのCLIPテキストエンコーダーを使っているだけです。そのため、Stable Diffusionモデルの学習ではテキストエンコーダーは全く変化しません*2。
CLIPの利用法
学習後のCLIPは、テキストエンコーダーとイメージエンコーダーがよく協調して、ペアになるラベルと画像を入れるとどちらのエンコーダーも似たようなベクトルを出力するようになります。つまり画像「だけ」を入れたときにイメージエンコーダーから出てくるベクトルと、ラベル「たけ」を入れたときにテキストエンコーダーから出てくるベクトルを比べることで、それが何の画像か判断できるわけです。例えば、ある画像を入れて出てきたベクトルが「dog」というラベルのベクトルとよく似ていれば、その画像は「犬の画像」といえるわけです。
こんな感じでCLIPは画像のラベル付けができるわけですが、そのほかにもStable Diffusionにとって重要な特徴があります。それが「分類化」です。
「分類化」とは、「似たような画像は似たようなベクトルに、似てない画像は全然似てないベクトルに」画像を変換する性質です。ラベルについても同様に、「似たような概念は似たようなベクトルに、似ていない概念は全然似てないベクトルに」変換されます。
先ほどの「dog」画像のベクトルですが、もしかしたら「cat」画像のベクトルともちょっとは似ているかもしれません。一方「house」というラベルのベクトルとは全然似ていないでしょう。dogとcatの画像ベクトルが少し似ているのは、どちらも4つの脚を持つ毛の生えた哺乳類動物だからです。houseは生き物でなく形も特徴も犬と全然違うので、全然違うベクトルになるでしょう。
Stable Diffusionはこのような性質を応用して「学習したことがない画像」を描き出すことができます。「cat」と「dog」の中間ぐらいのベクトルであれば、どちらの特徴も取り入れて「ネコっぽくもあり犬っぽくもある」絵を描きます。
テキストエンコーダーのしくみ
テキストエンコーダーとイメージエンコーダは「Transformer」というメカニズムによってベクトル変換を行っています。Transformerの概要については以前の記事で中身を説明したので読んでみてください。
イメージエンコーダーはStable Diffusionでは使わないので、テキストエンコーダーのみ仕組みの概要を説明します。
テキストエンコーダーは「Tokenizer」と「Transformerのデコーダーブロック」からなっています。
※Transformerは本来「エンコーダー」と「デコーダー」の2つのブロックからできていますが、ここでは「デコーダーブロック」のみ使っています。

入力されたテキスト(プロンプト)はまずTokenizer(トークナイザー)に送られます。トークナイザーは与えられたテキストを「トークン」に切り分けます。トークンとはテキストエンコーダーが処理できる単語の最小単位です。なぜ単語のままでなくてトークンに切り分けるかは、その方が機械にとって都合がいいから、というだけです。
CLIPのテキストエンコーダーで一度に処理できるトークンは77個が最大です。もしトークン数が77を超える場合、超えた分は次回の処理に回されます。
※この77個ルールで別々になってしまったトークンはまったく別のテキストとして扱われるため、つながりが無くなってしまいます。Stable Diffusionのプロンプトで長い文章を入力するときは注意しましょう。
トークナイザーは49408個のトークンを含むトークン辞書を持っています。単語や記号(スペースは除く)はこの辞書に従ってトークンごとに「トークンID」に変換されます*3。このIDはひとつの数字で、ベクトルではありません。例えば「cat」というトークンのIDは「1481」です。
トークンIDは次に、ベクトルに変換されます。まず0を49408個含んだベクトル(49408次元ベクトル)を用意します。このベクトルに並ぶ0のうち、ID+1番目だけを1にします。catでいうと1482番目の0を1に変えます。このように、IDに対応する数字だけを1にすると49408通りのベクトルが作れるので、これらのベクトルによってトークンを表現することができます。
このトークンベクトルをトークンの数だけ作ります。もしトークンが3つあれば49408次元ベクトルが3つ作られます。
トークナイザーで作られたこれらのベクトルは、いっぺんにTransformerに送られます。トークンの順番は非常に重要なので、順番を保ったまま送られます。
Transformerはこのトークンの順番ごとに番号を割り振ります。Stable Diffusionでは前のほうに書かれた単語が重要視されますが、その重要度はここで振られた番号によって決められます。
Transformerのこれ以上の詳しい説明はしませんが、入力されたベクトルはいろいろな処理を経て変換され、768次元ベクトルに変換されます(Stable Diffusionバージョン1系の場合)。これがStable DiffusionのU-Netに送られて画像生成に使われます。
まとめ
Stable Diffusionに入力されたプロンプトは、処理しやすくするためにベクトルに変換されますが、それを行うのがCLIPのテキストエンコーダーです。
CLIPはStable Diffusionとは全く別の仕組みで、画像をテキストラベルによってクラス分けするために提案されたものです。CLIPはテキストエンコーダーとイメージエンコーダーからなり、ペアになる画像とラベルで似たようなベクトルを出力するように学習されます。Stable Diffusionはこのテキストエンコーダーだけを使って画像生成を行っています。
テキストエンコーダーの中身は実質Transformerです。Transformerについて少し詳しく知りたい方は以前の記事をご覧ください。
誰でもわかるStable Diffusion LoRAを作ってみよう(実践編)
以前の記事でLoRAを作るためのKohya_ss導入の解説を書きました*1。
今回は、kohya_ssを使ったLoRA作成の実践編です。
LoRAの簡単な説明
「LoRA」とは、要するに「追加コンテンツ」です。「〇〇.ckpt」または「〇〇.safetensors」という名前で、1つのファイルにまとまっています。
Stable Diffusionは「モデル」(=Stable Diffusionの脳みそ)を読み込むことでいろいろな画像を描けますが、モデルが知らないモノを描くことは基本的にはできません。そこでLoRAの出番です。画像を描かせるときに特定のLoRAを読み込むと、そのLoRAが持っている特徴の画像を描くことができます。
LoRA作成には、「用意した画像をStable Diffusionに学習させる」という作業が必要です。学習した結果がLoRAファイルとして保存されます。このLoRAファイルをStable Diffusionに読み込ませることで、学習した画像を再現できる、という仕組みです。
学習の方法はいくつかありますが、現在の主流は「kohya_ss」というツールを使う方法です。そこで、この記事ではkohya_ssを使ったLoRA作成法について解説します。
LoRA作成の準備
学習前に以下のような準備をする必要があります。
- (まだ行っていないなら)PCのスペックを確認
- (まだ行っていないなら)kohya_ssのインストール
- 学習したい画像を用意する
- 必要なら正則化画像を用意する
- 画像にキャプションを付ける
PCのスペックを確認
まずお使いのPCがLoRA学習をできるかどうかチェックしましょう。一番重要なのは「グラフィックカードのスペック」です。
お使いのPCのグラフィックカードを見てみましょう。以下はWindows11のチェック法です。
Windowsの画面左下、窓マーク(4つの四角)のアイコンを右クリックし、「タスクマネージャー」を開きます。タスクマネージャーの左端に並ぶアイコンの上から二番目、波形の形をしたアイコンを選ぶと「パフォーマンス」が開きますので、そこの左側パネルにある「GPU」を探してクリックしましょう。クリックすると右側のパネルに詳細情報が現れます。
右上に表示されているのがお使いのグラフィックカードの名前です。「NVIDIA」製のグラフィックカードでない場合はLoRA学習はできません*2
下の方にスクロールすると、「専用GPUメモリ」という表示があり、「0.8/8.0 GB」のような形で数字が表示されています。この右側の数字(今の例だと8.0 GB)がお使いのPCに乗っている物理的なVRAMの容量です。この数字を覚えておきましょう。
6GBあれば一般的なLoRA学習は可能です。学習画像のサイズにもよりますが、4GBでもかろうじて動くかもしれません。2GBは未確認です。
kohya_ssのインストール
インストール法については以前の記事で説明しましたので、そちらを参考にしてください。
学習したい画像を用意する
kohya_ssをインストールしたら、いよいよLoRA作成です。
作成のために、学習画像を用意します。
何を表現したいのか考えよう
LoRAを使えば、自分の表現したいものをStable Diffusionで描き出すことができます。
では、あなたはLoRAで何を表現したいのでしょう?
バカげた質問に聞こえるかもしれませんが、考えてみると案外ぼんやりとしたイメージしか持っていないことも多いものです。ここで少しイメージを固めておくと、学習画像やキャプションのクオリティが上がり、LoRAの精度もより上がるでしょう。
あなたが表現したいものは?
- モチーフは人物?物?風景?画風?構図?
- 細かい部分?それとも大まかな部分?
- その表現を強力に前面に出したい?それともちょっとしたワンポイント程度?
- 写真のようなフォトリアルなイメージ?それとも2次元イラスト?
- ベースモデルにないもの?それともベースモデルのイメージを拡張するもの?
- ある1つの表現だけ?それとも複数の表現の組み合わせ?
わかりやすい画像を選ぼう
あなたの表現したいもの(「ターゲット」と呼びます)が決まったら、ふさわしい画像を用意しましょう。すべての画像にターゲットが必ず含まれるようにします。それぞれの画像に写るターゲットの大きさや向きがバラバラであっても問題ありません。むしろバラバラの方がいいくらいです。画像のバリエーションは多ければ多いほど結果は良くなります。
今回、例として「猫耳セーラー服」をターゲットにしてLoRAを作ってみます。セーラー服を着た猫耳の女性の画像を用意します。

画像を整えよう
画像を用意したら、次にその画像を学習にふさわしい形に整えます。主な作業は「画像サイズをそろえること」と「画像を修正すること」です。
ー画像サイズをそろえる
LoRA作成に使う画像はどんなサイズでも構いません。また、サイズがバラバラであっても構いません。ただ、Stable Diffusionのモデルは、バージョン1系は512x512ピクセル、バージョン2系は768x768ピクセルの画像で学習していることが多いので、LoRA学習で使う画像もどちらかのサイズに合わせるのが無難です。
バラバラの画像サイズを使う場合は、バッチサイズ(同時に学習する枚数)に注意してください。バッチサイズを増やしたいなら同じサイズの画像を何枚ずつか用意する必要があります(同じサイズの画像でないと同時に読み込めないからです)。例えばバッチサイズを2にしたいなら、使用サイズそれぞれに対して2枚以上ずつ用意する必要があります。
画像のアスペクト比については特に決まりはありませんが、ほとんどのモデルはアスペクト比1:1の画像で学習されていますので、できれば1:1に合わせる方がいいでしょう。
kohya_ssでは画像サイズに関する設定がいくつかありますので、覚えておくとよいでしょう(kohya_ss設定については下の方にも説明があります)。
- Max resolution:画像の最大サイズをここで指定します。このサイズを超える画像は縮小されます。ただし「Don't upscale bucket resolution」オプションをオンにした場合は無視されます。
- Enable buckets:いろいろな画像サイズを学習できるようにするオプションです。画像サイズが統一されていない場合は必ずこのスイッチをオンにしましょう。
- Don't upscale bucket resolution:最大サイズのリミットを外すボタンです。このスイッチをオンにすると、どんなに大きなサイズの画像もそのまま読み込んで学習します。オフの場合は、最大サイズを超える画像は縮小されます。
- Bucket resolution steps:画像をサイズによってグループ分けするときに、何ピクセルごとにグループ分けするかを指定します。
特に注意しなければいけないのは「Bucket resolution steps」です。デフォルトは64ピクセルですが、これは準備する画像のピクセルサイズが(タテヨコどちらも)64で割り切れないといけないという意味です。もし割り切れない場合、余分なサイズは切り取られてしまいます。できればここは64のままにしておいて、画像サイズを合わせる(つまり64ピクセルで割り切れるサイズを使う)ようにしましょう。
今回の「猫耳セーラー服」の例では、画像を縮小して512x512に揃えました。画像枚数が少ないので1枚を何枚かに切り分けたりして枚数を水増ししています。

ー画像を修正する (オプション)
可能であればターゲット「のみ」写っている画像を用意するのが理想ですが、実際の学習画像にはターゲット以外のいろいろなものが写り込んでいるのが普通です。もし理想的な学習画像でなくても、あまり神経質になる必要はありません。キャプションを適切につければ学習はそれなりにうまくいきます(キャプション付けは後述)。
しかし、もし余計なものが映りすぎると感じたりキャプション付けが難しいと思うなら、画像から余計なものを消してしまいましょう。
例えば、もしターゲットが「服」であれば、その服だけが重要で、どこで誰が着ているかは重要ではないので、着ている人物の顔や背景などを消します。
消すときは、消したい部分をぼかすのでなく、真っ白に塗りつぶしましょう。真っ白い部分は学習されませんが、ぼかした部分は学習されてしまいます。もし顔をぼかしてしまうと、出来上がったLoRAは「ピンボケ顔」ばかり出力するおかしなLoRAになってしまいます。
「顔を塗りつぶして大丈夫?顔のない怪物になっちゃうんじゃないの?」と思われるかもしれませんが、大丈夫です。Stable Diffusionモデルはもう人体の構造を十分に学習しているので、「服の上には顔が来る」ということを知っています。このLoRAを使ってもちゃんと顔を描き上げてくれます。
背景も(必要なら)白く塗りつぶしましょう。
「猫耳セーラー服」の例では画像を修正せずにそのまま使います。
画像フォルダを作る
画像が用意できたら、それらをフォルダの中に置きます。kohya_ssに読み込ませるには、少し特殊なファイル構造が必要です。
まず、適当な場所にフォルダを1つ作りましょう。このフォルダが今回のLoRAを学習するためのおおもとのフォルダになります。例として「lora_test」というフォルダを作ってみます。

この「lora_test」フォルダの中に、もう1つフォルダを作ります。このフォルダの中に画像を入れます。
さて、このフォルダの名付け方には決まりがあります。「画像を読み込む繰り返し回数」をフォルダ名先頭に必ず書かなければいけないのです。例えば、フォルダ内のそれぞれの画像を10回繰り返し学習したい場合は、フォルダ名の先頭に「10_」と付けなければいけません。20回なら「20_」です。「‗」(アンダーバー)記号も忘れないようにしましょう。
この数字の後ろに加えるテキストですが、以下のルールがあります。
- 画像にキャプションをつけない場合:「キーワード クラス名 」(例「20_sailneko cloths」)
- 画像にキャプションをつける場合:何でもいい(例「20_sailneko」)
画像にキャプションをつけない場合、このフォルダ名がキャプション代わりになります。上の例では、最初の「sailneko」はターゲットを呼び出すときの「キーワード」になります。半角スペースを挟んで2つ目の「cloths」はターゲットのクラス(種類)を表します(もしターゲットが女性キャラならクラス名は「girl」とか「woman」)
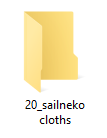
名前の最初に必ず学習の繰り返し数をつけます
テキスト部分は「キーワード クラス名」(半角スペースで区切る)
フォルダ数はいくつでもOK
画像にキャプションをつけるときは、フォルダ名は無視されるのでどんな名前を付けても構いません。

名前の最初に必ず学習の繰り返し数をつけます、テキスト部分は何でもOK
フォルダ数はいくつでもOK
「数字付きの名前を持つフォルダ」を作ったら、その中に画像を入れましょう。
ちなみに、この「数字付きの名前を持つフォルダ」はいくつ作っても構いません。
例えば10回繰り返したい画像と20回繰り返したい画像があるなら、「10_fuku1」「20_fuku2」という感じでフォルダを2つ作って、それぞれの画像を繰り返したい数に応じて2つのフォルダに振り分けましょう。
「繰り返し回数が同じでも画像の内容に応じてフォルダを分けるべきなのか」という疑問ですが、画像にキャプションを付けない場合は、フォルダ分けしてもいいでしょう。学習時はフォルダ名の「キーワード」がその中に入っている画像のキャプションになります。
画像にキャプションを付けるのであれば、フォルダ分けには意味がありません。どうせ学習するときにはすべてのフォルダの画像が混ざります。
画像にキャプションを付ける
それぞれの画像に、説明文(キャプション)を付けます。必須ではありませんが、キャプションを付けた方がLoRAクオリティは飛躍的に上がるので、よほどの理由がない限りはキャプションを付けましょう。
キャプションは自動で書いてもらうこともできます。
キャプションの自動作成
画像にキャプションをつけるのはなかなか大変な作業です。英語で書かなければいけないうえに、画像内容を詳しく説明するのも簡単ではありません。そこで、自動的に画像のキャプションを書いてもらうツールを使ってみましょう。
kohya_ssにBLIP、GIT、WD14というツールが用意されています。まずはこれを使ってキャプションを作成しましょう。
WD14は「black, cat, face, tail」などのように、コンマで区切られた単語を並べるスタイルでキャプションが作られます。GIT、BLIPを使った場合は「a black cat is sitting on a chair」のようにより文章に近いスタイルでキャプションが作られます。
どちらがいいのかは一概に言えません。
Stable Diffusionにキャプションを取り込む「Text Encoder」というモジュールは、もともと文章スタイル(つまりGIT、BLIPスタイル)でキャプションを分析するようにできていて、画像生成も文章スタイルのプロンプトの方が画像品質が良いとの情報があります。しかし、今では多くのモデルがコンマ区切りスタイル(つまりWD14スタイル)で画像を学習していて、画像を生成するときもコンマ区切りスタイルでプロンプトを書く手法が主流なので、そちらのスタイルを好む人も多いようです。
今回の例では、コンマ区切りスタイルを使うことにします。
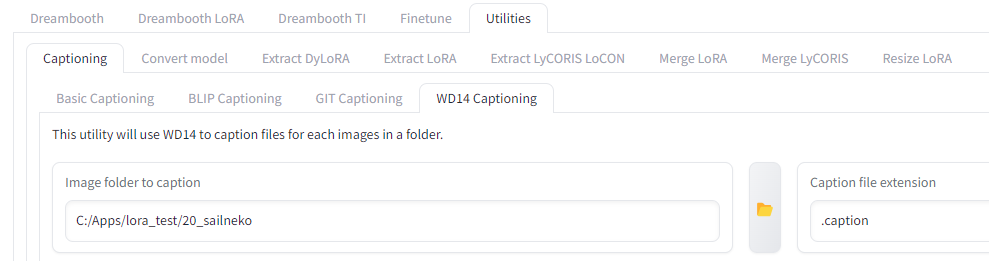
kohya_ssの一番上に並ぶタブの一番右、「Utilities」タブを選択します。
するとそのすぐ下にまたタブが並ぶので一番左の「Captioning」を選びましょう。
またしてもすぐ下にタブが並ぶので一番右の「WD14 Captioning」を選びます。
ここで指定すべきは2つだけ、「Image folder to caption」と「Caption file extension」です。
「Image folder to caption」は「キャプションをつけたい画像が入っているフォルダ」を指定します。上の例でいえば「20_sailneko」といった「数字で始まる名前のフォルダ」です。
「Caption file extension」は「.caption」と書きます(学習設定と合わせるためです)。
これだけ指定したら「Caption images」ボタンを押しましょう。
初回は処理に必要なファイルがダウンロードされることがあるので待ちましょう。
しばらく待つと「captioning done」というメッセージがプロンプト(黒背景に白い文字が並ぶウィンドウ)に表示されます。
できたキャプションはテキストファイルとして画像と同じ場所に画像と同じ名前で保存されます。例えば「f001.png」という名前の画像のキャプションは「f001.caption」という名前で保存されます。
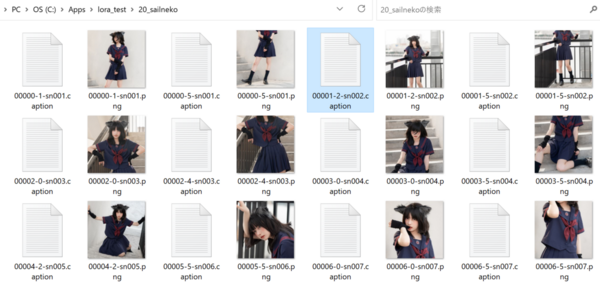
キャプションの手直し
自動作成されたキャプションをそのまま使っても構わないのですが、細かくチェックしてみると決して完ぺきなキャプションとは言えません。もし精度にこだわるなら、手直しをしましょう。
- ターゲット名をつける
- ターゲット以外のものを「全部」キャプションに書く
- 表記ゆれを直す
例として、この写真につけられた自動キャプションを見てみます。

1girl, solo, long hair, looking at viewer, smile, bangs, skirt, shirt, black hair, gloves, animal ears, closed mouth, school uniform, short sleeves, pleated skirt, serafuku, day, black gloves, cat ears, fingerless gloves, black skirt, sailor collar, lips, blue skirt, neckerchief, hand on hip, blue shirt, blue sailor collar, red neckerchief, black serafuku, realistic, railing, red lips, blue serafuku
なかなかの精度ですが、同じ単語が何度も出てきたり、説明が重複しているところもあります。これを直します。
まず「ターゲット」となるものに名前を付けましょう。これがLoRA使用時にプロンプトでターゲットを呼び出す「キーワード」になります。
ターゲットが独特なものなら、ターゲット名を自分で発明してしまいましょう。なるべく使われていない意味のない単語を選ぶようにします(例えばtzwとかbksとか)。推奨は「アルファベット3文字程度」となっていますが、別に3文字でなくても構いません。分かりやすい単語でももちろん構いません*3。
もしターゲットが画風の場合は、「〇〇 style」というふうに書けばいいと思います。
ターゲット名はキャプションの先頭に持ってきましょう。
今回の例では、ターゲットを「sailneko」という名前(猫耳セーラー服なので)にしてみます。
次に、「ターゲットでないもの」が「全部」書かれているかを確認します。書かれていないならキャプションにどんどん付け足していきます。例えば、ある人がセーラー服を着ている画像の場合、服はターゲットですが、それを着ている人物はターゲットでないので、「1girl」と付け足します。その他、「ターゲットでない」ものを気づく限りできるだけ多く書き足しましょう。これが詳細であればあるほどLoRAの精度が上がります。
同時に、「ターゲットに含まれる要素」の単語は取り除きましょう。例えば「猫耳と服」がターゲットの場合、ターゲットを(何でもいいんですが)「sailneko」と名付けたとして、ターゲットの要素はその「sailneko」に入っているので、「animal ears」「cat ears」とか「skirt」「school uniform」といった単語はもういりません。それらの単語は消します。手袋は「sailneko」要素にしたくないので、「gloves」のような単語は残しておきます。
上の写真の自動キャプションを直した結果、以下のようなキャプションになりました。
sailneko, 1girl, solo, long black hair, bangs, closed mouth, red lips, looking at viewer, smile, day, black fingerless gloves, hand on hip, realistic, railing, stairs
このような感じですべての画像のキャプションを直していきます。
すべての画像のキャプションで同じ表現を使うようにしましょう。例えば女性の画像を自動キャプション付けした場合、「woman」だったり「girl」だったり「person」だったり、画像によっていろいろな単語が使われているかもしれません。これらは統一しておきましょう。
キャプションはLoRAのクオリティを上げるためにとても重要なので、しっかり書きましょう。「何を表現したいのか」というイメージがしっかりまとまっていれば、キャプションも適切につけられるようになります。
注意:キャプション内の単語は全部学習される
LoRA学習は、ターゲットだけでなく、キャプションに書かれた単語すべてを新たに学びます。しかも、その学習が非常に「強力」なので、以前覚えていた概念を上書きしてしまうこともあります。
例えばある学習画像の背景に火星(mars)が映っていて、そのキャプションに「mars」と書いてあれば、LoRAは(たとえそれがターゲットでなくても)「火星の絵」も新たに学びます。このLoRAを使った時、「mars」とプロンプトに指定すれば、新たに学んだ火星が描かれます。新たに覚えた「火星」がそれまで覚えていた「火星」を上書きしてしまうのです。ただ、プロンプトに「mars」と書くことはあまりないので、この「火星」学習の影響は少ないでしょう。
しかし、「girl」の場合はどうでしょう?プロンプトでもキャプションでも「girl」と指定することは結構あります。もしLoRAが「girl」の概念を新たに学んでいたら、このLoRAを使ってプロンプトに「girl」と指定するたびに「学習画像に映っていた女性」の絵ばかり出てきてしまいます。それでは困るのです。その女性はターゲットではないからです。
では、その特定の「girl」をどうやって取り除けばいいのでしょう?
まず思いつくのは「キャプションにgirlと書かない」という方法です。キャプションに書いてなければ新たに「girl」を学習することはありません。しかし、これは別の問題を生みます。「girlとして学習されなかった女性のイメージ」がほかの単語にくっついてしまうのです。もしそれが「ターゲット名」にくっついた場合、事態はさらに悪化します。「ターゲット名」をプロンプトで指定するたびに、その女性しか出てこなくなるからです*4。いろいろな女性を生成したいのに…。
そこで別の方法が提案されました。それが「正則化画像」です。
正則化画像を用意する (オプション)
「正則化画像」とは、「LoRA学習をかく乱させるための妨害情報」みたいなものです。上の例では、「girl」とキャプション付けられた別人女性の画像を大量に用意することによって、「girl」が特定の女性にならないようにします。
「正則化画像」の対象となる単語は、
- 学習画像のキャプション内で頻繁に使われている単語
- 画像生成時にプロンプトでよく使われる単語
を基準に選ぶのがいいと思います。例えば「mars」はそれほどプロンプトで使われないうえ学習画像にもあまり出てこないので正則化は不要でしょう。
「girl」のような「大まかな概念」(「クラス」とも呼ばれます)は頻繁に出てくるので正則化が好ましいかもしれません。「LoRAを使った時に学習画像の女性しか出てこなくなっても全然オーケー」というならもちろん正則化は不要ですが。
「めんどくさいので正則化画像は使わない」というのも一つの手です。「このLoRAを使ったらこういう絵ばかり出るんだ、そういう仕様なんだ」と割り切ってしまうのも、それはそれでアリです。
もし正則化画像を使うのであれば、画像の内容はバラバラであればあるほどいいとされています。かく乱が目的なので、ある特定の特徴に偏らないようにしましょう。枚数は「学習画像の枚数x繰り返し数」と同じくらいの数がいいようです。例えば学習画像が20枚で、それぞれ10回繰り返す場合、20x10=200枚が基準です。ただ、それより少ない枚数でも学習自体に問題はありません。正則化画像の繰り返し学習数を増やす(後述)のも手です。
正則化画像は、専用にフォルダを用意して、そこに入れます。このフォルダ構造は学習画像と同じです。
まず、正則化画像のおおもとになるフォルダを作ります。これは学習画像とは全く別のフォルダです。「reg_sailneko」とでもしておきます。
次に、このreg_sailnekoフォルダの中にまた新しいフォルダを作り、そのフォルダに正則化画像を入れます。このフォルダは名付け方に規則があり、「1_girl」のように「学習を繰り返す回数_正則化したいキーワード」という方式で名前を付けます。正則化画像は通常、数字は1(つまり繰り返さない)で構いませんが、画像数が少ない場合は繰り返し数を増やしてください。また、正則化画像にキャプションは必要ありません。キャプションがない場合はフォルダ名にあるキーワード(ここではgirl)が使われます。
今回の例では正則化画像を使わないことにします。
Kohya_ssで学習設定をする
画像とキャプションが用意できたので、ついにkohya_ssを使ってLoRA学習を実行します。
kohya_ssを立ち上げたら、「Dreambooth LoRA」タブを選びましょう。このタブを選ばずに間違って「Dreambooth」タブで設定をしてしまうことが多いので気をつけましょう。
設定には「Source model」「Folders」「Training parameters」の3つのセクションを設定する必要があります。
![]()
Source model
ここで学習のベースとなるモデルを選択します。LoRAはここで選んだモデルに付け足される形で学習されるので、モデルと学習画像のスタイルがあまりにもかけ離れていると、写真にマンガを描くようないびつな学習になるのでモデル選びは慎重に行いましょう。出来上がったLoRAはどんなモデルとも一緒に使えるので、使用するときにどのようなモデルと一緒に使われるかを想定して選ぶのも重要です。
「Save trained model as」は「safetensors」にしてください。

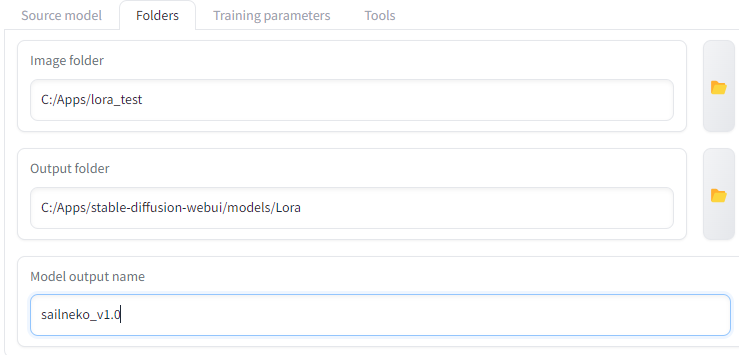
Folders
ここで学習画像のフォルダとLoRA出力先フォルダを指定します。
「Output folder」(LoRA出力先フォルダ)はどこでも構いません。適当に決めましょう。
「Image folders」(学習画像のフォルダ)は、画像の入ったフォルダ(「20_abc」のような、名前の先頭に数字のついたフォルダ)ではなく、その1つ上のフォルダを選んでください。
「Regularisation folder」(正則化画像のフォルダ)も同じように、画像フォルダの1つ上のフォルダを選んでください。正則化画像を使わないならフォルダ指定欄は空にします。
「Logging folder」は学習ログを保存するためのフォルダです。これも適当に決めてかまいません。空のままにしておくと、実行パスにログフォルダが作成されます。
「Model output name」は学習後に作成されるLoRAの名前です。「sailneko_v1.0」のようにターゲット名とバージョン番号をつけておくと後で見やすくなります。
Training parameters
kohya_ssには設定がたくさんあり、混乱してしまいそうですが、初めはほぼデフォルト設定のままで構いません。こだわりたくなったらいろいろ設定を変えてみましょう。
各設定については以下の記事で詳しく解説していますので見てください。
以下は独断による推奨設定です。
- Train batch size:2~4
- Epoch:2~3
- Mixed & Saved precision:bf16またはfp16
- Seed:何か数字を入れておく(何でもいい)
- LR Scheduler:constantまたはcosine
- Optimizer:AdamWまたはAdamW8bit
- Network Rank(dimention):8~32(大きいほど精度がいい)
- Network Alpha:Network Rankと同じ数字
- Clip skip:2次元系画像なら2、3次元系画像なら1
- Memory efficient attention:もしVRAMが8GB未満ならチェック
あとの設定はデフォルト値でいいと思います。
「猫耳セーラー服」LoRAの作成では、設定値は
- Train batch size:2
- Epoch:2
- Mixed & Saved precision:fp16
- Seed:1234
- LR Scheduler:constant
- Optimizer:AdamW8bit
- Network Rank & Network Alpha:32
- Clip skip:1
にしました。また、ターゲットが左右対称なので、「Flip augmentation」(学習時にランダムに画像を左右反転させる)オプションもオンにしました。
設定が終わったら、この設定を将来のために保存しておきましょう。
「Configuration file」の項目を押すと、「Save」ボタンが出てくるのでどこか適当なところに設定をセーブします。将来的にこの設定を使いたいときは、同じConfiguration file項目から「Load」を押して設定ファイルを読み込みます。設定ファイルを読み込んだ後も、画像フォルダやLoRA名を毎回変えなければいけない事に注意してください。
学習開始
さて、いよいよ学習の開始です。画面下の「Train model」というオレンジ色のボタンを押してください。学習が始まります。
学習の進行具合はkohya_ssの画面ではなく「コマンドプロンプト」(黒い背景に白い文字がたくさん表示されるウィンドウ)に表示されます。ここにプログレスバーが出るので、このバーが右側いっぱいまで伸びるのを待ちましょう。
1つのLoRA学習の目安は5分~30分です。長く学習すればいいというわけでもありません。
学習が終わると、指定した出力先フォルダにLoRAファイルができています。
このファイルをStable Diffusion Web UI内の「models」→「Lora」フォルダの中に入れると、このLoRAが使えるようになります。
今回の例で作成したLoRAは学習回数が240回、時間にして4分ほど、とかなり少なめですが、それでも完成したLoRAを使ってみると「猫耳セーラー服」要素をかなりよく再現しています。ただ、よく見るとデザインが違っていたり、正則化画像を使っていないので学習画像の女性の要素も混ざりがちです。完璧なLoRAを作るのはここからさらに試行錯誤が必要です。


まとめ
今回はLoRA作成の実践編として、LoRA学習のための画像の準備の仕方からkohya_ssの設定法までを解説しました。
LoRAはかなりパワフルな追加学習法ですが、ただ単にLoRAを作ればいいというものではありません。LoRAの学習には学習画像、キャプション、学習設定と様々な要素がからむので、理想的なLoRAを完成させるには試行錯誤が必要です。
あなたの理想の画像を出力できるようになるために、いろいろなLoRA学習を試してみてください。
誰でもわかるStable Diffusion Kohya_ssを使ったLoRA学習設定を徹底解説
前回の記事では、Stable Diffusionモデルを追加学習するためのWebUI環境「kohya_ss」の導入法について解説しました。
今回は、LoRAのしくみを大まかに説明し、その後にkohya_ssを使ったLoRA学習設定について解説していきます。
※今回の記事は非常に長いです!
この記事では「各設定の意味」のみ解説しています。
「学習画像の用意のしかた」とか「画像にどうキャプションをつけるか」とか「どう学習を実行するか」は解説していません。学習の実行法についてはまた別の記事で解説したいと思います。
- LoRAの仕組みを知ろう
- kohya_ssを立ち上げてみよう
- LoRA学習の各設定
- LoRA設定のセーブ、ロード
- Source modelタブ: 学習に使うベースモデルの設定
- Foldersタブ: 学習画像の場所とLoRA出力先の設定
- Training parametersタブ: 学習の詳細設定
- LoRA type
- LoRA network weights
- DIM from weights
- Train batch size
- Epoch
- Save every N epochs
- Caption Extension
- Mixed precision
- Save precision
- Number of CPU threads per core
- Seed
- Cache latents
- Cache latents to disk
- Learning rate:
- LR Scheduler:
- LR warmup
- Optimizer
- Optimizer extra arguments
- Text Encoder learning rate
- Unet learning rate
- Network Rank(Dimension)
- Network alpha:
- Max resolution
- Stop text encoder training
- Enable buckets
- Advanced Configuration
- Weights、Blocks、Conv
- Weights: Down LR weights/Mid LR weights/Up LR weights
- Weights: Blocks LR zero threshold
- Blocks: Block dims, Block alphas
- Conv: Conv dims, Conv, alphas
- No token padding
- Gradient accumulation steps
- Weighted captions
- Prior loss weight
- LR number of cycles
- LR power
- Additional parameters
- Save every N steps
- Save last N steps
- Keep n tokens
- Clip skip
- Max Token Length
- Full fp16 training (experimental)
- Gradient checkpointing
- Shuffle caption
- Persistent data loader
- Memory efficient attention
- Use xformers
- Color augmentation
- Flip augmentation
- Min SNR gamma
- Don't upscale bucket resolution
- Bucket resolution steps
- Random crop instead of center crop
- Noise offset type
- Noise offset
- Adaptive noise scale
- Multires noise iterations
- Multires noise discount
- Dropout caption every n epochs
- Rate of caption dropout
- VAE batch size
- Save training state
- Resume from saved training state
- Max train epoch
- Max num workers for DataLoader
- WANDB API Key
- WANDB Logging
- Sample images config
- まとめ
LoRAの仕組みを知ろう
kohya_ssの各設定の意味を知るには、LoRAがどういうメカニズムで追加学習をするのか知っておく必要があります。
追加学習の対象である「モデル」とは何なのかも合わせて説明します。
「モデル」とは
Stable Diffusionは「モデル」と呼ばれるモジュールを読み込んで使います。モデルとはいわば「脳みそ」で、その正体は「ニューラルネットのウェイト情報」です。
ニューラルネットはたくさんの「ニューロン」からできていて、ニューロンのまとまりが何層もの「レイヤー」を形作っています。あるレイヤーのニューロンは違うレイヤーのニューロンと線でつながっていて、そのつながりの強さを表すのが「ウェイト」です。膨大な絵の情報を保持しているのは、この「ウェイト」なのです。
LoRAは小さいニューラルネットを追加する
LoRAは「追加学習」の一種ですが、追加学習とはニューラルネットをバージョンアップすることです。
その方法はいろいろありますが、まず思いつくのは下の図のようにモデル全部を学習しなおす方法です。
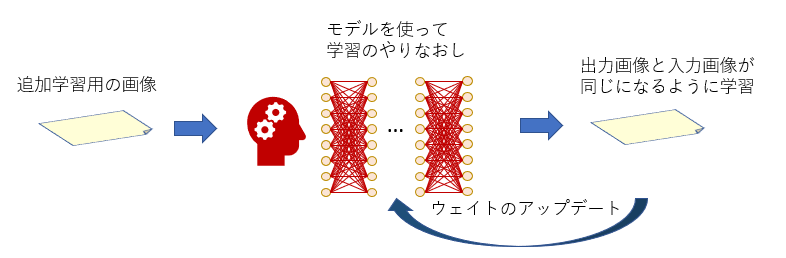
「DreamBooth」という追加学習法がこの方法を使っています。
この方法だと、もし追加学習データを公開したい場合、追加学習で新しくなったモデルを丸ごと配布する必要があります。
モデルのサイズは通常2G~5Gバイトあり、配布はなかなか大変です。
これに対して、LoRA学習ではモデルには手を付けず、新しい「小さなニューラルネット」を学習したい位置ごとに作ります。追加学習は、この小さなニューラルネットを対象にして行われます。
LoRAを配布したいときはこの小さなニューラルネットだけを配布すればいいので、データサイズが少なく済みます。
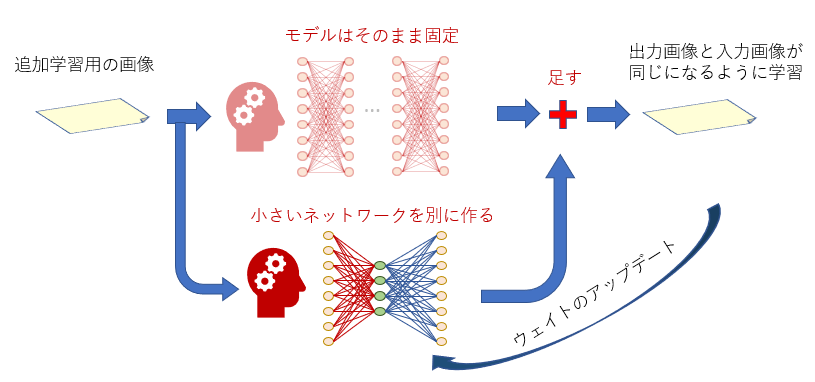
小さいニューラルネットの構造
LoRAの小さいニューラルネットは3つの層からできています。左の「入力層」、右の「出力層」のニューロンの数は、ターゲットのニューラルネットの「入力層」「出力層」のニューロン数と同じです。真ん中の層(中間層)のニューロン数は「ランク数」(または次元数)と呼ばれ、この数は学習するときに自由に決めることができます。
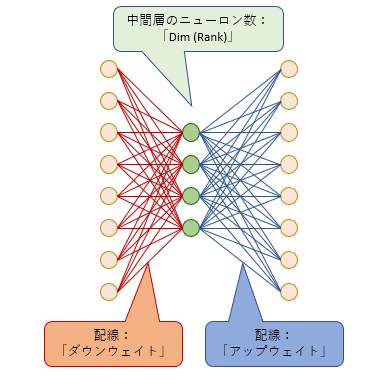
では、この小さなニューラルネットはどこに追加されるのでしょう?
LoRA学習対象1:U-Net
下の図はStable Diffusionの心臓部である「U-Net」というメカニズムです。
U-Netは「Down」(左半分)「Mid」(一番下)「Up」(右半分)に分けられます。
そして、Down12ブロック、Mid1ブロック、Up12ブロックの合計25ブロックからできています。
ここの中の赤い矢印の部分(オレンジ色のブロック)がLoRA学習対象です。つまり、この赤い矢印のブロックに小さなニューラルネットが追加されます。
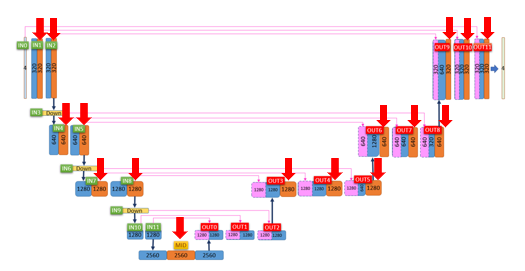
オレンジ色のブロックでは「テキスト処理」、つまりプロンプトとして与えられたテキストを画像に反映させる処理を行っています。
このブロックをさらに細かく見ると、以下のような処理を行っています。
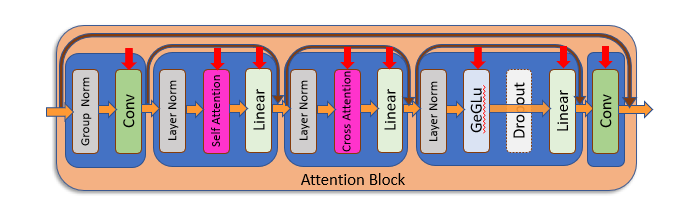
ここにも赤い矢印がいくつもついていますが、この赤い矢印の処理全部にそれぞれ別のニューラルネットワークが追加されます。
ここに追加されるニューラルネットのことをKohya_ssでは単純に「UNet」と呼んでいます。
RoLA学習対象2:テキストエンコーダー
LoRAがニューラルネットを追加するのはここだけではありません。
上の図の「Cross Attention」というブロックは、「テキストエンコーダー」というモジュールからテキスト情報を受け取ります。この「テキストエンコーダー」は、テキストデータであるプロンプトを数字の列(ベクトル)に変換するという役割があります。
テキストエンコーダーは1つしかなく、U-Net内のすべてのAttentionブロックで共通で使われます。このテキストエンコーダーは本来Stable Diffusion内では「完成品」として扱われ、モデル学習の対象にはなりませんが、LoRAによる追加学習ではこれも学習対象です。
LoRAでアップデートしたテキストエンコーダーはすべてのAttentionブロックで使われるので、ここに追加されるニューラルネットは完成画像にとても大きな影響を及ぼします。
ここに追加されるニューラルネットの事をKohya_ssでは「Text Encoder」と呼んでいます。
kohya_ssを立ち上げてみよう
LoRA学習のしくみを見たので、いよいよkohya_ssを使ってみましょう。
kohya_ssフォルダ内にある「gui.bat」をダブルクリックすると、コマンドプロンプト(黒背景の文字だけのウィンドウ)が立ち上がります。しばらくするとそこにURLが表示されるので、それをウェブブラウザのURL欄に入力してリターンを押すとkohya_ssの画面がブラウザ上に表示されます。
kohya_ssを立ち上げると、UIの上部にタブがいくつか現れます。この中の「Dreambooth LoRA」を選びましょう。これがLoRA学習のためのタブです。

LoRA学習の各設定
「Dreambooth LoRA」タブを選ぶと、たくさんの設定が出てきます。それらをここで解説します。
LoRA設定のセーブ、ロード
一番上にあるのは「コンフィグファイル」です。ここでLoRA設定をコンフィグファイルとしてセーブ、ロードすることができます。

設定をコンフィグファイルに保存しておけば後でそのコンフィグファイルをロードして設定を復元できるので、お気に入りの設定はなるべく保存しておきましょう。
次に、4つのタブがあります。最初の3つについてそれぞれ詳しく見ていきます。
(「Tools」タブはLoRA学習時には使わないので説明は省略します。)

Source modelタブ: 学習に使うベースモデルの設定
Pretrained model name or path
ここにベースモデルの場所を指定します。最初に説明した通り、LoRAは既存のモデルに小さなニューラルネットを追加します。つまり、LoRA学習とは「ベースモデル+α」の「+α」の部分を作る作業です。
LoRA学習はベースモデルの特徴に大きな影響を受けるので、
- 学習する画像と相性のいいベースモデル
- 画像生成時に使う(と想定される)モデルと相性のいいベースモデル
を選ぶ必要があります。例えば学習画像が実写のような画像なら、実写生成が得意なモデルを選ぶといいでしょう。学習画像が2次元調でも実写調の画像生成を想定しているなら、2次元調と3次元調の混合モデルを選ぶべきかもしれません。
なお、学習後にできたLoRAファイルは「追加されたニューラルネット」のデータのみで、ベースモデルのデータは入っていません。そのため、完成したLoRAファイルを使って画像を生成するときは、ここで指定したベースモデルだけでなく、どんなモデルとも一緒に使うことができます。
Model Quick Pick
ここでモデルを選ぶと、学習実行時にそのモデルが自動的にネット経由でダウンロードされ、ベースモデルとして使用されます。Pretrained model name or pathの指定は無視されます。
もしモデルがPCに保存されていない場合や、どのモデルを使っていいのか分からない場合は、ここで選択できるモデルを選んで使いましょう。
「runwayml/stable-diffusion-v1-5」が使われることが多いようです。
自分で用意したモデルを使いたい場合はcustomにしましょう。
Save trained model as
学習済みのLoRAファイルをどのファイル形式で保存するかを指定できます。
ckptはかつてStable Diffusionで使われていた主流の形式でしたが、この形式にはセキュリティ上問題があったため、safetensorsというより安全なファイル形式が生まれました。現在ではsafetensorsが主流となっています。
特別な理由がない限りsafetensorsを選びましょう。
v2
Stable Diffusionのモデルは「バージョン1系」と「バージョン2系」の2つのバージョンがあり、これらはデータ構造がそれぞれ違います。バージョン2系は(2023年5月時点で)まだ普及しておらず、ほとんどの有名モデルは「バージョン1系」です。
しかし、「バージョン2系」のモデルをベースモデルとして使う場合はこのオプションをオンにしましょう。
デフォルトはオフです。
v_parameterization
v-parameterizationとは「バージョン2系」モデルで導入された手法で、従来よりも少ないサンプリングステップで安定して画像を生成するためのトリックです。
「バージョン1系」のモデルを使用するときはこのオプションはオフで構いませんが、お使いのベースモデルがv-parameterizationを導入していることが分かっている場合はここをオンにしてください。これをオンにするときは必ずv2もオンにしましょう。
デフォルトはオフです。
Foldersタブ: 学習画像の場所とLoRA出力先の設定
Image folder
学習画像を含むフォルダ(「10_cat」のような名前のフォルダ)がある場所を指定します。
「画像がある場所」ではありません!「画像を含むフォルダがある場所」を指定しましょう。
Output folder
完成後のLoRAファイルの出力先を指定します。学習の途中経過のLoRAを出力する場合(後述)も、ここで指定した出力先に出力されます。
Regularisation folder
LoRA学習では、学習画像の特徴が意図しない単語に強く結びつきすぎてしまい、その単語を入れるたびに学習画像に似た画像しか生成しなくなる、ということがしばしば起こります。
そこで「正則化画像」という「学習画像っぽくない」画像を一緒に学習させることで、特定の単語に学習対象が強く結びついてしまうのを防ぐことができます。
正則化画像の使用は必須ではありませんが、もし正則化画像を学習に使う場合は、ここで正則化画像を含んだフォルダの場所を指定します。
Logging folder
学習時の処理をログとして出力して保存したい場合、その場所を指定します。
ここで指定した名前のフォルダが作業フォルダ内に作成され、さらにその中に学習日時を表す名前のフォルダができます。ログはそこに保存されます。
なお、ログファイルは「tensorboard」というツールまたは「WandB」というオンラインサービス(後述)でグラフ化できます。
Model output name
完成したLoRAファイルの名前をここで指定します。拡張子をつける必要はありません。
「〇〇_ver1.0」(〇〇は学習対象の名前)のようにバージョン番号付きの名前にすると分かりやすいでしょう。
なお、名前には日本語を使わないようにしましょう。
Training comment
完成したLoRAファイルには「メタデータ」としてテキストを埋め込むことができます。もし埋め込みたいテキストがある場合はここに記述します。
なお、メタデータはStable Diffusion WebUIのLoRA選択画面でⓘマークをクリックすると見ることができます。
Training parametersタブ: 学習の詳細設定
このタブではLoRA学習のためのほぼすべてのパラメータを設定します。
LoRA type
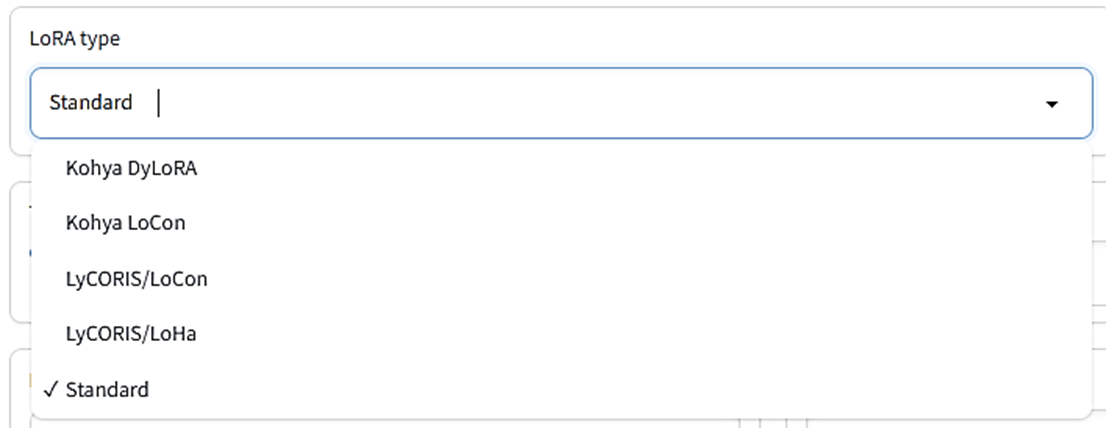
LoRA学習のタイプを指定します。上で解説したLoRAは「スタンダード」タイプです。「DyLoRA」は指定したRank以下の複数のランクを同時に学習するので、最適なランクを選びたいときに便利です。LoHaは高効率なLoRA、LoConは学習をU-NetのResブロックまで広げたものです。
最初はStandardタイプで問題ありません。学習がうまくいかないときはほかのタイプを選んでみましょう。
LoRA network weights
既に学習済みのLoRAファイルを使ってさらに追加学習をしたいときは、ここでLoRAファイルを指定します。
ここで指定したLoRAは学習開始時に読み込まれ、このLoRAの状態から学習がスタートします。学習後のLoRAはまた別のファイルとして保存されるので、ここで指定したLoRAファイルが上書きされることはありません。
DIM from weights
これはLoRA network weightsで追加学習を行うとき限定のオプションです。
上の図にある通り、LoRAは小さなニューラルネットを追加しますが、その中間層のニューロン数(ランク数)はNetwork Rank(後述)で自由に設定することができます。
しかし、このオプションをオンにすると、作成するLoRAのランク数がLoRA network weightsで指定したLoRAと同じランク数に設定されます。ここをオンにしたときはNetwork Rankの指定は無視されます。
例えば追加学習に使うLoRAのランク数が32の時、作成するLoRAのランク数も32に設定されます。
デフォルトはオフです。
Train batch size
バッチサイズを指定します。バッチとは「いっぺんに読み込む画像の枚数」です。バッチサイズ2なら、一度に2枚の画像を同時に学習します。違う絵を複数同時に学習すると個々の絵に対するチューニング精度は落ちますが、複数の絵の特徴を包括的にとらえる学習になるので、最終的な仕上がりはかえって良くなる可能性があります。
(特定の絵にチューニングしすぎると応用の利かないLoRAになってしまいます。)
複数の絵を一度に学習するのでバッチサイズを上げれば上げるほど学習時間が短くなりますが、チューニング精度が下がるうえウェイト変更数も減るので、場合によっては学習不足になる可能性があります。
(バッチサイズを上げるときは学習率(Learning rate、後述します)も上げた方がいいという報告もあります。例えばバッチサイズ2なら学習率を2倍にする、といった感じです。)
また、バッチサイズを上げるほどメモリを多く消費します。お使いのPCのVRAMのサイズに合わせて決めましょう。
VRAMが6GBあればバッチサイズ2もかろうじて可能でしょう。
デフォルトは1です。
※バッチごとに同時に読み込む画像はすべて同じサイズでなければならないので、学習画像のサイズがバラバラだと、ここで指定したバッチ数よりも少ない枚数しか同時処理しないことあります。
Epoch
1エポックは「1セットの学習」です。
例えば50枚の画像をそれぞれ10回ずつ読み込んで学習したいとします。この場合、1エポックは50x10=500回の学習です。2エポックならこれを2回繰り返すので、500x2=1000回の学習になります。
指定されたエポック数の学習が終わった後に、LoRAファイルが作成され、指定の場所に保存されます。
LoRAの場合、2~3エポックの学習でも十分効果を得られます。
Save every N epochs
ここで指定したエポック数ごとに、途中経過をLoRAファイルとして保存することができます。
例えば「Epoch」で10と指定し、「Save every N epochs」を2に指定すると、2エポックごと(2、4、6、8エポック終了時)に指定フォルダにLoRAファイルが保存されます。
途中経過のLoRA作成が不要の場合は、ここの数値を「Epoch」と同じ数値にしましょう。
Caption Extension
もし画像ごとにキャプションファイルを用意している場合、そのキャプションファイルの拡張子をここで指定します。
ここが空欄の場合、拡張子は「.caption」になります。もしキャプションファイルの拡張子が「.txt」の時は、ここに「.txt」と指定しておきましょう。
キャプションファイルがない場合は、無視してかまいません。
Mixed precision
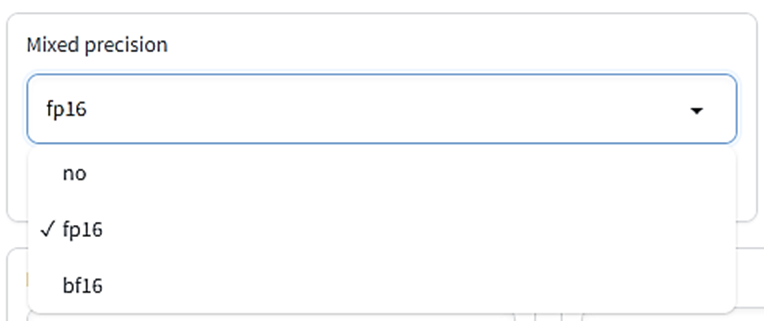
学習時のウェイトデータの混合精度のタイプを指定します。
本来ウェイトデータは32ビット単位(no選択の場合)ですが、必要に応じて16ビット単位のデータも混ぜて学習するとかなりのメモリ節約、スピードアップにつながります。fp16は精度を半分にしたデータ形式、bf16は32ビットデータと同じ数値の幅を取り扱えるよう工夫したデータ形式です。
fp16で十分精度の高いLoRAを得られます。
Save precision
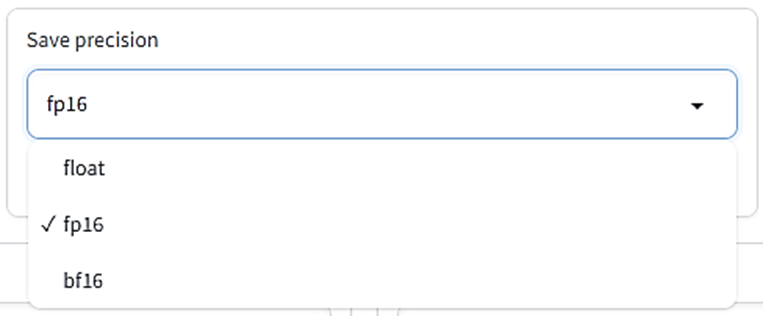
LoRAファイルに保存するウェイトデータのタイプを指定します。
floatは32ビット、fp16とbf16は16ビット単位です。下の二つの方がファイルサイズが小さくなります。
デフォルトはfp16です。
Number of CPU threads per core
学習時のCPUコアごとのスレッドの数です。基本的に数値が大きいほど効率が上がりますが、スペックに応じて設定を調節する必要があります。
デフォルトは2です。
Seed
学習時には「どういう順番で画像を読み込むか」や「学習画像にノイズをどれくらい乗せるか(詳細は省略)」など、ランダムな処理がいくつもあります。
Seedはそのランダム処理の手順を決めるためのIDのようなもので、同じSeedを指定すれば毎回同じランダム手順が使われるので学習結果を再現しやすくなります。
ただ、このSeedを使わないランダム処理(例えば画像をランダムに切り抜く処理など)もあるので、同じSeedを指定しても必ず同じ学習結果が得られるとは限りません。
デフォルトは空欄です。指定しなければ学習実行時にSeedが適当に設定されます。
結果をなるべく再現したいなら適当に(1234とか)数字を設定しておいて損はありません。
Cache latents
学習画像はVRAMに読み込まれ、U-Netに入る前にLatentという状態に「圧縮」されて小さくなり、この状態でVRAM内で学習されます。通常、画像は読み込まれるたびに毎回「圧縮」されますが、Cache latentsにチェックを入れると、「圧縮」済みの画像をメインメモリに保持するよう指定できます。
メインメモリに保持するとVRAMのスペース節約になり、スピードも上がりますが、「圧縮」前の画像加工ができなくなるので、flip_aug以外のaugmentation(後述)が使えなくなります。また、画像を毎回ランダムな範囲で切り抜くrandom crop(後述)も使えなくなります。
デフォルトはオンです。
Cache latents to disk
Cache latentsオプションと似ていますが、ここにチェックを入れると、圧縮画像データを一時ファイルとしてディスクに保存するよう指定できます。
kohya_ssを再起動した後もこの一時ファイルを再利用できるので、同じデータで何度もLoRA学習をしたい場合はこのオプションをオンにすると学習効率が上がります。
ただし、これをオンにするとflip_aug以外のaugmentationとrandom cropが使えなくなります。
デフォルトはオフです。
Learning rate:
学習率を指定します。「学習」とは、与えられた絵とそっくりな絵を作れるようにニューラルネット内の配線の太さ(ウェイト)を変えていくことですが、毎回絵が与えられるごとにゴッソリ配線を変えてしまうと、与えられた絵のみにチューニングしすぎて、他の絵がまったく描けなくなってしまいます。
これを避けるため、毎回、与えられた絵をちょっとだけ取り込むように、ちょっとだけウェイトを変えます。この「ちょっとだけ」の量を決めるのが「学習率」(Learning rate)です。
デフォルト値は0.0001です。
LR Scheduler:
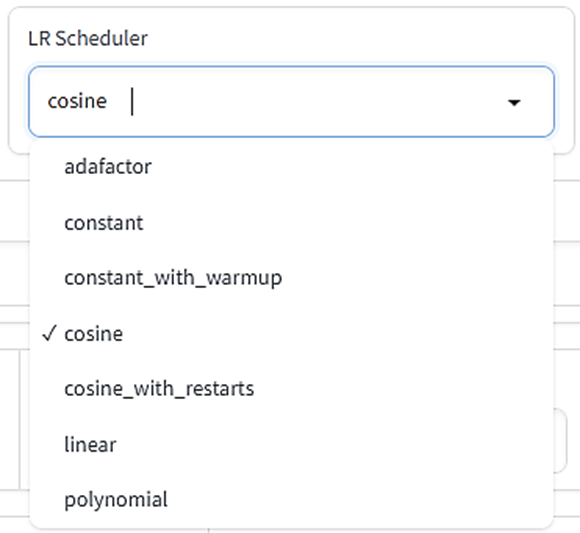
学習の途中で学習率(Learning rate)を変えることができます。スケジューラーとは「どういうふうに学習率を変えていくかの設定」です。
- adafactor:オプティマイザー(後述)をAdafactorに設定する場合はこれを選択する。VRAM節約のため状況に応じて学習率を自動調節しながら学習
- constant:学習率は最初から最後まで変わらない
- constant_with_warmup:最初は学習率0から始めてウォームアップ中にLearning rate設定値に向けてだんだん増やし、本学習の時はLearning rate設定値を使う
- cosine:波(コサインカーブ)を描きながら学習率をだんだん0に向けて減らす
- cosine_with_restarts:cosineを何度も繰り返す(LR number of cyclesの説明も見てください)
- linear:最初はLearning rate設定値で始め、0に向けて一直線に減らす
- polynomial:挙動はlinearと同じ、減らし方が少し複雑(LR powerの説明も見てください)
学習率をLearning rate設定値に固定したいならconstantにしてください。
デフォルトはcosineです。
LR warmup
スケジューラーでconstant_with_warmupを選択した場合、ウォームアップをどれくらいの回数行うかをここで設定します。
ここで指定する数値は全体のステップ数のパーセントです。
例えば、50枚の画像をバッチサイズ1で10回学習、これを2エポック行うとき、総ステップ数は50x10x2=1000です。もしLR warmupを10に設定すると、総ステップ1000のうち最初の10%、つまり100ステップがウォームアップになります。
スケジューラーがconstant_with_warmupでないならここは無視して構いません。
デフォルトは10です。
Optimizer
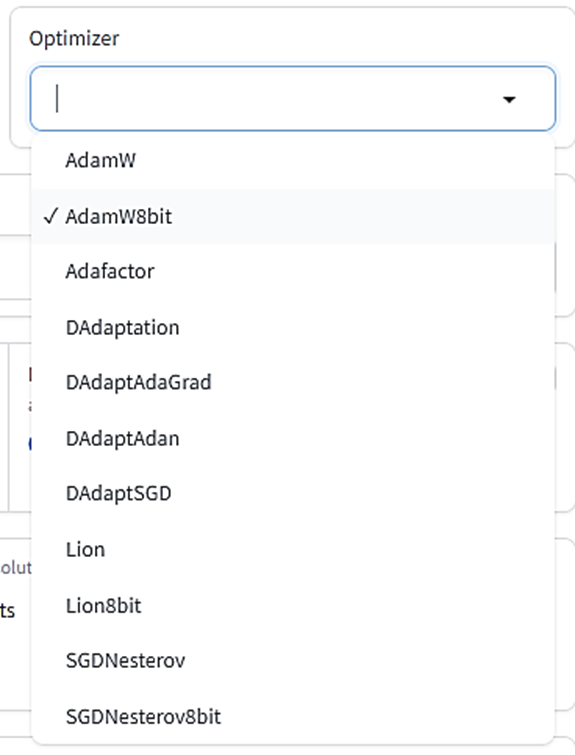
オプティマイザーとは「学習中にニューラルネットのウェイトをどうアップデートするか」の設定です。賢く学習するためにいろいろな手法が提案されていますが、LoRA学習で最もよく使われるのは「AdamW」(32ビット)または「AdamW8bit」です。AdamW8bitはVRAMの使用量も低く、精度も十分なので迷ったらこれを使いましょう。
その他、Adam手法を取り入れつつ学習の進み具合に応じて学習率を適切に調節する「Adafactor」もよく使われるようです(Adafactorを使う場合はLearning rate設定は無視されます)。
「DAdapt」は学習率を調節するオプティマイザー、「Lion」は比較的新しいオプティマイザーですがまだ十分検証されていません。「SGDNesterov」は学習精度は良いものの速度が下がるという報告があります。
デフォルトはAdamW8bitです。基本的にこのままで問題ありません。
Optimizer extra arguments
指定したオプティマイザーに対してさらに細かく設定したい場合は、ここでコマンドを書きます。
通常は空欄のままで構いません。
Text Encoder learning rate
テキストエンコーダーに対する学習率を設定します。最初のほうで書いた通り、テキストエンコーダーの追加学習の影響はU-Net全体に及びます。
そのため、通常はU-Netの各ブロックに対する学習率(Unet learning rate)よりも低くしておきます。
デフォルト値は0.00005(5e-5)です。
ここで数値を指定した場合、Learning rateの値よりもこちらが優先されます。
Unet learning rate
U-Netに対する学習率を設定します。U-Netの中にある各Attentionブロック(設定によっては他のブロックも)に追加学習を行うときの学習率です。
デフォルト値は0.0001です。
ここで数値を指定した場合、Learning rateの値よりもこちらが優先されます。
Network Rank(Dimension)
記事の上の方で説明した「追加する小さなニューラルネット」の中間層のニューロンの数を指定します(詳細は上の図を見てください)。
ニューロンの数が多いほど学習情報を多く保持できますが、学習対象以外の余計な情報まで学習してしまう可能性が高くなり、LoRAのファイルサイズも大きくなります。
一般的に最大128程度で設定することが多いですが、32で十分という報告もあります。
試験的にLoRAを作る場合は2~8あたりから始めるのがいいかもしれません。
デフォルトは8です。
Network alpha:
これは、LoRA保存時にウェイトが0に丸め込まれてしまうのを防ぐための便宜上の処置として導入されたものです。
LoRAはその構造上、ニューラルネットのウェイト値が小さくなりがちで、小さくなりすぎるとゼロ(つまりなにも学習していないのと同じ)と見分けがつかなくなってしまう恐れがあります。そこで、実際の(保存される)ウェイト値は大きく保ちつつ、学習時には常にウェイトを一定の割合で弱めてウェイト値を小さく見せかける、というテクニックが提案されました。この「ウェイトを弱める割合」を決めるのがNetwork alphaです。
Network alpha値が小さければ小さいほど、保存されるLoRAのニューラルネットのウェイト値が大きくなります。
使用時にウェイトがどれだけ弱まるか(使用強度)は「Network_Alpha/Network_Rank」で計算され(ほぼ0~1の値)、Network Rank数と深く関係しています。
学習後のLoRAの精度がいまいちな場合、ウェイトデータが小さすぎて0に潰れてしまっている可能性があります。そんな時はNetwork Alpha値を下げてみる(=保存ウェイト値を大きくする)とよいでしょう。
デフォルトは1(つまり保存ウェイト値をなるべく最大にする)です。
Network AlphaとNetwork Rankが同じ値の場合、効果はオフになります。
※Network Alpha値がNetwork Rank値を超えてはいけません。超える数字を指定することは可能ですが、高確率で意図しないLoRAになります。
また、Network Alphaを設定するときは、学習率への影響を考える必要があります。
例えばAlphaが16、Rankが32の場合、ウェイトの使用強度は16/32 = 0.5になり、つまり学習率が「Learning Rate」設定値のさらに半分の効力しか持たないことになります。
AlphaとRankが同じ数字であれば使用強度は1になり、学習率に何の影響も与えません。
Max resolution
学習画像の最大解像度を「幅、高さ」の順で指定します。もし学習画像がここで指定した解像度を超える場合、この解像度まで縮小されます。
デフォルトは「512,512」です。多くのモデルがこのサイズの画像を使っているので、LoRA学習の時もこのサイズの画像を使うのが無難です。
Stop text encoder training
テキストエンコーダーの学習は途中でストップすることができます。上で書いた通り、テキストエンコーダーのアップデートは全体に大きな影響を及ぼすので過学習(学習画像にチューニングしすぎて他の画像が描けなくなる)に陥りやすく、ほどほどのところで学習をストップさせるのも過学習を防ぐ一つの手です。
ここで指定した数値は全学習ステップのパーセントです。学習がこのパーセントに達したら、テキストエンコーダーは学習をストップします。
例えば、総ステップ数が1000だった場合、ここで80と指定したら、学習進行度が80%の時、つまり1000x0.8=800ステップの時点でテキストエンコーダーの学習が終了します。
U-Netの学習は残り200ステップで引き続き行われます。
ここが0の場合、テキストエンコーダーの学習は最後までストップしません。
Enable buckets
「bucket」とはその名の通り「バケツ」(入れ物)です。LoRAで使う学習画像はサイズが統一されていなくてもかまわないのですが、違うサイズの画像を同時に学習することはできません。そのため、学習前に画像をサイズに応じて「バケツ」に振り分ける必要があります。似たサイズの画像は同じバケツに入れ、違うサイズの画像は別のバケツに入れていきます。
デフォルトはオンです。
もし学習画像のサイズがすべて同じならこのオプションはオフにして構いませんが、オンのままでも影響はありません。
※もし学習画像のサイズが統一されていない時にEnable bucketsをオフにすると、学習画像は拡大、縮小されてサイズが同じ大きさに揃えられます。
拡大、縮小は画像のアスペクト比を保ったまま行われます。アスペクト比が基準サイズと同じでない場合、拡大縮小後の画像のタテかヨコが基準サイズからはみ出すことがあります。例えば、基準サイズが512x512(アスペクト比1)で、画像サイズが1536x1024(アスペクト比1.5)の場合、画像は縮小されて768x512(アスペクト比1.5のまま)になります。
Advanced Configuration
ここより後は、「Advanced Configuration」セクションにあるオプションです。
Weights、Blocks、Conv
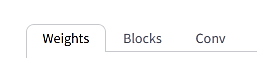
これらはU-Net内の各ブロックの「学習の重み付け」と「ランク」の設定です。それぞれのタブを選択すると、対応する設定画面が表示されます。
※これらの設定は上級者向けです。こだわりがないならすべて空欄のままで構いません。
Weights: Down LR weights/Mid LR weights/Up LR weights
U-Netの構造図からわかる通り、U-Netは12個のINブロック、1個のMIDブロック、12個のOUTブロックの計25個のブロックからできています。
それぞれのブロックの学習率のウェイト(重み)を変えたい場合、ここで個別に設定することができます。
ここでいうウェイトとは0~1の数値で表される「学習の強さ」で、0の場合は「まったく学習しない」、1の場合は「Learning rateで設定した学習率で学習」という感じで学習の強さを変えることができます。
ウェイトを0.5にした場合、Learning rateの半分の学習率になります。
「Down LR weights」は12個のINブロックのそれぞれのウェイトを指定します。
「Mid LR weights」はMIDブロックのウェイトを指定します。
「Up LR weights」は12個のOUTブロックのそれぞれのウェイトを指定します。
Weights: Blocks LR zero threshold
「LoRAはニューラルネットを追加する」と説明しましたが、ウェイトが小さすぎる(つまりほとんど学習していない)ニューラルネットは追加しても意味がありません。そこで、「ウェイトが小さすぎるブロックにはニューラルネットを追加しない」という設定ができます。
ここで設定したウェイト値を超えないブロックでは、ニューラルネットが追加されません。例えばここに0.1と指定した場合、ウェイトを0.1以下に設定したブロックにはニューラルネットが追加されません(排除対象が指定値も含んでいることに注意してください!)。
デフォルトは空欄で、空欄の場合は0(何もしない)です。
Blocks: Block dims, Block alphas
ここで、IN0~11、MID、OUT0~11の25個の各ブロックに対しそれぞれ違うランク(dim)値とアルファ値を設定することができます。
ランク値とアルファ値についてはNetwork Rank、Network alphaの説明を見てください。
ランクの大きいブロックはより多くの情報を保持できることが期待されます。
このパラメータ値は常に25個の数字を指定しなければいけませんが、LoRAはAttentionブロックを学習対象としているので、Attentionブロックの存在しないIN0、IN3、IN6、IN9、IN10、IN11、OUT0、IN1、IN2に対する設定(1、4、7、11、12、14、15、16番目の数字)は学習時は無視されます。
※上級者向け設定です。こだわりがないなら空欄のままで構いません。ここを指定しない場合は「Network Rank(Dimention)」値と「Network Alpha」値がすべてのブロックに適応されます。
Conv: Conv dims, Conv, alphas
LoRAが学習対象としているAttentionブロックには「Conv」というニューラルネットがあり、そこも追加学習によりアップデートされます(記事上部のAttention層の構造の図を見てください)。これは「畳み込み」と言われる処理で、そこで使われている「フィルター」の大きさは1x1マスです。
畳み込みについてはこの記事を読んでください。
一方、Attention以外のブロック(Res、Downブロック)やOUTにあるAttentionブロックの一部には、3x3マスのフィルターを使った畳み込みを行っている部分もあります。本来そこはLoRAの学習対象ではありませんが、このパラメータで指定することでResブロックの3x3の畳み込みも学習対象にすることができます。
学習対象が増えるので、より精密なLoRA学習を行える可能性があります。
設定方法は「Blocks: Blocks dims, Blocks alphas」と同じです。
3x3のConvは25層すべてに存在します。
※上級者向け設定です。こだわりがないなら空欄のままで構いません。
No token padding
学習画像につけるキャプションは、75トークンごとに処理されます(「トークン」は基本的に「単語」と捉えて問題ありません)。
キャプションの長さが75トークン未満の場合、キャプションの後に終端記号が必要なだけ追加され、75トークンに揃えられます。これを「パディング」と言います。
ここでは、トークンのパディングを行わないようにする指定ができます。
デフォルトはオフです。基本的にオフのままで構いません。
Gradient accumulation steps
ウェイトの変更(つまり「学習」)は通常は1バッチ読み込むごとに行いますが、学習を複数バッチまとめていっぺんに行うこともできます。何バッチまとめていっぺんに学習するかを指定するのがこのオプションです。
これはバッチ数を上げる働きと似た効果(「同じ効果」ではありません!)があります。
例えば、バッチサイズが4の場合、1バッチで同時に読み込まれる画像数は4枚です。つまり4枚読み込むごとに1回学習が行われます。ここでGradient accumulation stepsを2にすると、2バッチごとに1回学習が行われるので、結果的に8枚読み込むごとに1回学習が行われることになります。これはバッチ数8と似た働き(同じではありません!)です。
この数値を上げると学習回数が減るので処理が速くなりますがメモリを多く消費します。
デフォルトは1です。
Weighted captions
現在一番人気のStable Diffusion利用環境は「Stable Diffusion WebUI」ですが、これには独特のプロンプト記述法があります。例えばプロンプトに「black cat」と指定する時に「Black」をものすごく強調したい場合、「(black:1.2) cat」という風に強調したいワードをかっこで囲み、ワードの後に「:数字」と入れると、その数字の倍数だけワードが強調されます。
この記述法を学習画像のキャプションでも使えるようにするのがこのオプションです。
複雑なキャプションを書きたい場合は試してみるのもいいでしょう。
デフォルトはオフです。
Prior loss weight
学習時に「正則化画像」(詳しくは上のRegularisation folderの説明を見てください)をどれだけ重要視するかを決めるのがPrior loss weightです。
この値が低いと、正則化画像はそれほど重要でないと判断され、より学習画像の特徴が強く現れるLoRAが生成されます。
正則化画像を使わない場合はこの設定は意味がありません。
これは0~1の値で、デフォルトは1(正則化画像も重視)です。
LR number of cycles
スケジューラーに「Cosine with restart」または「Polynomial」を選んだ場合、学習中にスケジューラー何サイクル実行するかを指定するオプションです。
このオプションの数値が2以上の場合、1回の学習中にスケジューラーが複数回実行されます。
Cosine with restartもPolynomialも、学習が進むにつれて学習率が0までだんだん下がっていきますが、サイクル数が2以上の場合、学習率が0に達したら学習率をリセットして再スタートします。
下の図(引用元)はCosine with restart(紫)とPolynomial(薄緑)の学習率の変化の例です。
紫の例ではサイクル数が4に設定されています。薄緑の例ではサイクル数は1です。
指定されたサイクル数を決められた学習ステップ内で実行するので、サイクル数が増えれば増えるほど、学習率の変化が激しくなります。
デフォルトは空欄で、空欄の場合は1になります。

Cosine with restartで「LR number of cycle = 4」 (紫)
Polynomialで「LR power = 2」 (薄緑)
LR power
これはスケジューラーにPolynomialを設定した場合のオプションで、この数が大きければ大きいほど最初の学習率の下がり方が急激になります。(上の図の薄緑の線のスロープが急激になります)。
powerが1の時はlinearスケジューラーと同じ形になります。
あまり数を大きくしすぎると学習率が0ちかくに張り付いてしまって学習不足に陥るので気をつけましょう。
デフォルトは空欄で、空欄の場合は1(つまりlinearスケジューラーと同じ)になります。
Additional parameters
kohya_ssのGUIに表示されていない学習設定パラメータをいじりたい場合、ここでコマンドとして入力します。
通常は空欄のままで構いません。
Save every N steps
ここで指定したステップ数の学習が終了するごとに、LoRAファイルが作成され、保存されます。
例えば総学習ステップ数が1000の時、ここで200と指定すると、200、400、600、800ステップ終了時にLoRAファイルが保存されます。
途中経過のLoRA保存については「Save every N epochs」も参照してください。
デフォルトは0(途中経過LoRAを保存しない)です。
Save last N steps
学習途中のLoRAを保存するようSave every N stepsで指定した場合のオプションです。
もし最近のLoRAファイルのみ保持して古いLoRAファイルは破棄したい場合、ここで「最近何ステップ分のLoRAファイルを保持しておくか」を設定できます。
例えば総学習ステップが600の時、Save every N stepsオプションで100ステップごとに保存するよう指定したとします。すると100、200、300、400、500ステップ目にLoRAファイルが保存されますが、Save every N stepsを300と指定した場合、最近300ステップ分のLoRAファイルのみ保持されます。つまり500ステップ目には200(=500-300)ステップ目より古いLoRA(つまり100ステップ目のLoRA)は消去されます。
デフォルトは0です。
Keep n tokens
学習画像にキャプションがついている場合、そのキャプション内のコンマで区切られた単語をランダムに入れ替えることができます(詳しくはShuffle captionオプションを見てください)。しかし、ずっと先頭に置いておきたい単語がある場合は、このオプションで「最初の〇単語は先頭に固定しておいて」と指定できます。
ここで指定した数の最初の単語は、いつも先頭に固定されます。
デフォルトは0です。Shuffle captionオプションがオフの場合はこのオプションは何もしません。
※ここでいう「単語」とは、コンマで区切られたテキストのことです。区切られたテキストがいくつ単語を含んでいようと、それは「1単語」としてカウントされます。
「black cat, eating, sitting」の場合、「black cat」で1単語です。
Clip skip
テキストエンコーダーには「CLIP」という仕組みが使われていますが、これは12層の似たようなレイヤーからできています。
テキスト(トークン)は本来、この12層のレイヤーを通って数字の列(ベクトル)に変換され、最後のレイヤーから出てきたベクトルがU-NetのAttentionブロックに送られます。
しかし、「Novel AI」というサービスが独自に開発したモデル、通称「Novel AIモデル」は、最後のレイヤーでなく最後から2番目のレイヤーが出力したベクトルを使う、という独自仕様を採用しました。Novel AIモデルから派生したモデルも同様です。そのため、「学習に使うベースモデルがCLIPのどのレイヤーから出てきたベクトルを使っているか」という指定が必要になります。
この「最後から〇番目」のレイヤー番号を指定するのが「Clip skip」です。
ここを2にすると、最後から2番目のレイヤーの出力ベクトルがAttentionブロックに送られます。1の場合は、最後のレイヤーの出力ベクトルが使われます。
ベースモデルにNovel AIモデル(またはそのミックスモデル)が使われている場合は、2にした方がいいでしょう。そのほかの場合は1で構いません。
Max Token Length
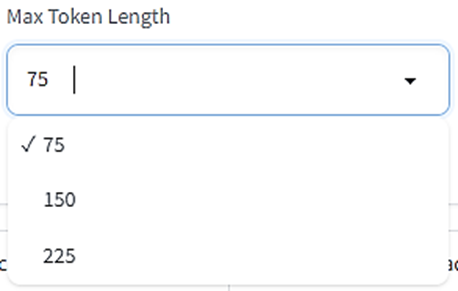
キャプションに含まれる最大のトークンの長さを指定します。
ここでいう「トークン」は単語数ではなく、トークン数は単語数とだいたい同じ~1.5倍ぐらいの数になります。コンマも1トークンとカウントされることに注意してください。
75トークンを超えるキャプションを使うことはめったにないでしょうが、「キャプションの文が長いな」と思ったときは、ここでより大きな数字を指定してください。
Full fp16 training (experimental)
上で説明したオプション「Mixed precision」をオン(fp16またはbf16)にすると、学習時に32ビットと16ビットのデータが混合して使用されますが、このオプションをオンにするとすべてのウェイトデータが16ビット(fp16形式)に揃えられます。メモリの節約にはなりますが、一部データ精度が半分になるので学習精度も落ちる可能性があります。
デフォルトはオフです。よっぽどメモリを節約したいとき以外はオフのままでいいでしょう。
Gradient checkpointing
通常の場合、学習中は、画像が読み込まれるごとに膨大な数のニューラルネットのウェイトを一斉に修正しアップデートします。これを「一斉」でなく「少しずつ」修正することで、計算処理を減らしてメモリを節約できます。
このオプションはウェイト計算を少しずつ行うように指定します。ここをオンにしてもオフにしてもLoRAの学習結果に影響はありません。
デフォルトはオフです。
Shuffle caption
学習画像にキャプションがついている場合、キャプションの多くは「black cat, eating, sitting」といった具合にコンマで区切られた単語が並んだ形式で書かれていることが多いでしょう。このコンマで区切られている単語の順番を毎回ランダムに入れ替えるのがShuffle captionオプションです。
一般的にキャプション内の単語は先頭に近いほど重視されます。そのため、単語の順番が固定されていると後方の単語がうまく学習されなかったり、前方の単語が学習画像と意図しない結びつきをする可能性があります。画像を読み込むごとに毎回単語の順番を入れ替えることで、このかたよりを修正できることが期待されます。
キャプションがコンマ区切りでなく文章になっている場合はこのオプションは意味がありません。
デフォルトはオフです。
※ここでいう「単語」とは、コンマで区切られたテキストのことです。区切られたテキストがいくつ単語を含んでいようと、それは「1単語」としてカウントされます。
「black cat, eating, sitting」の場合、「black cat」で1単語です。
Persistent data loader
学習に必要なデータは1つのエポックが終わるごとに破棄され、再読み込みされます。これを破棄せずに保持しておくためのオプションです。このオプションをオンにすると新しいエポックの学習が始まる速度が上がりますが、データを保持する分メモリを消費します。
デフォルトはオフです。
Memory efficient attention
これにチェックを入れるとVRAMの使用を抑えてAttentionブロックの処理を行います。次のオプションの「xformers」に比べてスピードは遅くなります。VRAMの容量が少ない場合はオンにしましょう。
デフォルトはオフです。
Use xformers
「xformers」というPythonライブラリを使用すると、若干のスピード低下と引き換えにVRAMの使用を抑えてAttentionブロック処理を行います。VRAMの容量が少ない場合はオンにしましょう。
デフォルトはオンです。
Color augmentation
「augmentation」とは「画像の水増し」を意味します。学習画像を毎回少し加工することにより、学習画像の種類を疑似的に増やします。
Color augmentationをオンにすると、画像の色相(Hue)を毎回ランダムに少し変化させます。これによって学習したLoRAは色調に若干の幅が出ることが期待されます。
Cache latentsオプションがオンの場合は使用できません。
デフォルトはオフです。
Flip augmentation
このオプションをオンにすると、ランダムに画像が左右反転します。左右のアングルを学習できるので、左右対称の人物や物体を学習したいときは有益でしょう。
デフォルトはオフです。
Min SNR gamma
LoRA学習では学習画像にいろいろな強さのノイズを乗せて学習します(このあたりの詳細は省略)が、乗っているノイズの強さの違いによって学習目標に近寄ったり離れたりして学習が安定しないことがあり、Min SNR gammaはそれを補正するために導入されました。特にノイズがあまり乗っていない画像を学習するときは目標から大きく離れたりするので、このジャンプを抑えるようにします。
詳細はややこしいので省略しますが、この値は0~20で設定でき、デフォルトは0です。
この方法を提唱した論文によると最適値は5だそうです。
どれほど効果的なのかは不明ですが、学習結果に不満がある時はいろいろな値を試してみるといいでしょう。
Don't upscale bucket resolution
Bucket(バケツ)のサイズはデフォルトでは256~1024ピクセル(またはMax resolutionオプションで最大解像度を指定している場合はそちらが優先されます)に設定されています。タテかヨコのどちらか一方でもこのサイズ範囲から外れた画像は、指定範囲内のサイズになるように(アスペクト比を保ったまま)拡大または縮小されます。
しかし、このオプションをオンにするとバケツサイズの範囲設定は無視され、学習画像のサイズに応じて自動的にバケツが用意されるので、すべての学習画像が拡大縮小されずに読み込まれるようになります。ただしこの時もBucket resolution steps(後述)にサイズを合わせるため画像の一部が切り取られる可能性はあります。
デフォルトはオンです。
Bucket resolution steps
Bucket(バケツ)を使用する場合、各バケツの解像度間隔をここで指定します。
例えばここで64を指定した場合、それぞれの学習画像をサイズに応じて64ピクセルごとに別のバケツに振り分けます。この振り分けはタテヨコそれぞれに対して行われます。
もし画像サイズがバケツの指定するサイズピッタリでない場合、はみ出した部分は切り取られます。
例えば、最大解像度が512ピクセルでバケツのステップサイズが64ピクセルごとの場合、バケツは512、448、384…となりますが、500ピクセルの画像は448ピクセルのバケツに入れられ、サイズを合わせるため余分な52ピクセルが切り取られます。
デフォルトは64ピクセルです。
※この数値をあまり小さくしすぎるとバケツの振り分けが細かくなりすぎてしまい、最悪「画像1枚ごとに1つのバケツ」のような状態になってしまいます。
1バッチにつき必ず同じバケツから画像を読み込むので、バケツの中の画像が少なすぎるとバッチ数が意図せず少なくなってしまうことに注意してください。
Random crop instead of center crop
上記のように、中途半端なサイズの画像はバケツに振り分けた後に一部が切り取られてサイズが揃えられますが、通常は画像の中心を保つように切り取られます。
このオプションをオンにすると、絵のどの部分が切り取られるかがランダムに決まります。学習の範囲を画像の中心以外に広げたいときはこのオプションをオンにします。
※cache latentsオプションをオンにしているときはこのオプションは使えません。
Noise offset type
学習画像に追加ノイズを乗せるときに、どの手法で乗せるのかを指定するオプションです。学習時には必ず画像にノイズを乗せる(この辺の詳細は省略します)のですが、このノイズは「予測しづらい」ノイズである方がより好ましいため、さらに多くのノイズを乗せることでより「予測しづらい」ノイズにします。
デフォルトはOriginalです。Multiresはもう少し複雑な方法でノイズを追加します。
Noise offset
Noise offset typeに「Original」を選択したときのオプションです。ここで0より大きな値を入れると追加ノイズが乗ります。値は0~1で、0の場合はまったくノイズを追加しません。1の場合は強いノイズを追加します。
0.1程度のノイズを追加するとLoRAの色合いが鮮やかになる(明暗がはっきりする)という報告があります。デフォルトは0です。
Adaptive noise scale
Noise offsetオプションとペアで使います。ここに数値を指定すると、Noise offsetで指定した追加ノイズ量がさらに調整され増幅あるいは減衰します。増幅(または減衰)する量は、「画像に現在どのくらいノイズが乗っているか」によって自動的に調整されます。値は-1~1で、プラスを指定すると追加ノイズ量が増え、マイナスを指定した場合は追加ノイズ量が減ります。
デフォルトは0です。
Multires noise iterations
Noise offset typeに「Multires」を選択したときのオプションです。ここで0より大きな値を入れると追加ノイズが乗ります。
Multiresでは、様々な解像度のノイズを作ってそれらを足すことで最終的な追加ノイズを作成します。ここでは「様々な解像度」をいくつ作るかを指定します。
デフォルトは0で、0の時は追加ノイズは乗りません。使用したい場合は6に設定することがが推奨されています。
Multires noise discount
Multires noise iterationsオプションとペアで使います。各解像度のノイズ量をある程度弱めるための数値です。0~1の値で、数字が小さいほどノイズがより弱まります。ちなみに弱める量は解像度によって違い、解像度の低いノイズはたくさん弱めます。
デフォルトは0で、0の場合は使用時に0.3に設定されます。通常は0.8が推奨されています。学習画像が比較的少ない場合は0.3程度に下げると良いようです。
Dropout caption every n epochs
通常、画像とキャプションはペアで学習されますが、特定のエポックごとにキャプションを使わず「キャプションなしの画像」のみ学習させることができます。
このオプションは「〇エポックごとにキャプションを使わない(ドロップアウト)」という指定を行えます。
例えばここで2を指定すると、2エポックごとに(2エポック目、4エポック目、6エポック目…)キャプションを使わない画像学習を行います。
キャプションのない画像を学習すると、そのLoRAはより包括的な画像の特徴を学習することが期待されます。また、特定の単語に画像の特徴を結び付けすぎないようにする効果も期待できます。ただしあまりキャプションを使わなすぎると、そのLoRAはプロンプトの効かないLoRAになってしまう可能性があるので気をつけましょう。
デフォルトは0で、0の場合はキャプションのドロップアウトを行いません。
Rate of caption dropout
上記のDropout caption every n epochsと似ていますが、学習の全工程のうち、ある一定の割合だけキャプションを使わず「キャプションなしの画像」として学習させることができます。
ここでキャプションなし画像の割合を設定できます。0は「学習中必ずキャプションを使う」設定、1は「学習中キャプションを全く使わない」設定です。
どの画像が「キャプションなし画像」として学習されるかはランダムに決まります。
例えば、画像20枚をそれぞれ50回読み込むLoRA学習を1エポックだけ行う場合、画像学習の総数は20枚x50回x1エポック=1000回です。この時Rate of caption dropoutを0.1に設定すると、1000回x0.1=100回は「キャプションなしの画像」として学習を行います。
デフォルトは0で、すべての画像をキャプション付きで学習します。
VAE batch size
Cache latentsオプションをオンにすると「圧縮」した状態の画像データをメインメモリに保持しておくことができますが、この「圧縮」画像を何枚一組で保持するかを設定するのがVAE batch sizeです。バッチサイズ(Batch size)で指定した画像枚数を一度に学習するので、VAE batch sizeもこれに合わせるのが普通です。
デフォルトは0で、この場合Batch sizeと同じ数値に設定されます。
Save training state
学習画像、繰り返し数、エポック数が多いとLoRAの学習に長い時間がかかります。
このオプションをオンにすると、学習を途中で中断して後日続きから学習を再開することができます。
学習の途中経過データは「last-state」というフォルダに保存されます。
Resume from saved training state
中断した学習を再開したい場合、ここに「last-state」フォルダの場所を指定します。
学習を再開するには、学習の途中経過データが保存されている必要があります。
Max train epoch
学習のための最大エポック数を指定します。Epochオプションでエポック数を指定するのが基本ですが、ここで指定したエポック数に達すると必ず学習を終了します。
デフォルトは空欄です。空欄のままで構いません。
Max num workers for DataLoader
学習のためのデータを読み込む時に使用するCPUプロセス数を指定するオプションです。この数値を上げるごとにサブプロセスが有効になりデータの読み込みスピードが上がりますが、数字を上げすぎるとかえって非効率になる場合があります。
なお、どれだけ大きい数字を指定しても、使用CPUの同時実行スレッド数以上にはなりません。
デフォルトは0で、CPUのメインプロセスでのみデータ読み込みを行います。
WANDB API Key
「WandB」(Weights&Biases)という機械学習サービスがあります。これは最適な設定を見つけるために学習の進行状況をグラフで表示したり学習ログなどをオンラインで記録、共有するサービスですが、kohya_ssでもこのサービスを使用できるようになりました。
ただしこのサービスのアカウントが必要です。アカウントを作成した後、https://app.wandb.ai/authorizeから「API key」を取得できます。取得したAPIキーをここに入力しておくと、学習時に自動的にログインし、WandBのサービスと連動できるようになります。
WandBに関する詳細は省きますが、「LoRA職人」を目指す人は試してみましょう。
WANDB Logging
学習状況のログをWandBサービスを使って記録するかどうかをここで指定できます。
デフォルトはオフで、オフの場合は「tensorboard」というツールの形式でログを記録します。
Sample images config
LoRAを使った画像生成がどんな感じになるのか学習途中でチェックしたい場合、ここで画像生成プロンプトを入力します。
ただ、LoRAは比較的学習時間が短いので、画像生成テストの必要はあまりないかもしれません。
Sample every n steps
学習中、何ステップ目に画像を生成したいのかを指定します。例えば100と指定すると、100ステップごとに画像を生成します。
デフォルトは0で、0の場合は画像を生成しません。
Sample every n epochs
学習中、何エポック目に画像を生成したいのかを指定します。例えば2と指定すると、2エポックごとに画像を生成します。
デフォルトは0で、0の場合は画像を生成しません。
Sample sampler
画像生成に使うサンプラーを指定します。ここで指定するサンプラーの多くはStable Diffusion Web UIで用意されているサンプラーと同じなので、詳細はWeb UIの説明サイトを参照してください。
デフォルトはeuler_aです。
Sample prompts
ここでプロンプトを入力します。
ただしここにはプロンプトだけでなく他の設定も入力できます。ほかの設定を入力する場合は「--n」のようにマイナス2つとアルファベットを組み合わせて設定を指定します。例えばネガティブプロンプトに「white, dog」と入れたい場合、「--n white, dog」と書きます。
よく使いそうな設定の指定は以下の通りです。
--n:ネガティブプロンプト
--w:画像の幅
--h:画像の高さ
--d:Seed
--l:CFG Scale
--s:ステップ数
デフォルトは空欄です。空欄の時に記述例が薄く表示されているので、それを参考にしてください。
まとめ
Stable Diffusionの追加学習のひとつであるLoRAのしくみと、LoRA学習を行うツールであるkohya_ssの各設定について解説しました。
設定する項目が非常に多いので混乱しそうですが、まずは推奨設定で軽く学習して、学習結果に応じて少しずつ設定を変えていくようにしましょう。
ここでの解説を参考にして、さらに高い精度のLoRA作成を目指してみてください。
AIお絵描きをめぐる問題 これまでとこれから
Stable Diffusionが一般に利用されるようになった2022年以降、AIによって生成された絵をめぐっては様々な賛否両論が巻き起こり、2023年現在でもこの技術をどう扱うべきなのか多くの業界が試行錯誤している状態です。
いずれ明確な方向性が決まるかガイドラインが策定されるかして議論は落ち着いていくと思いますが、ここでは2023年5月現在の状況を軽くまとめておきたいと思います。
驚異的な進化を遂げたお絵描きAI
「AIお絵描き」とは、文字通り「AIが描いた絵」、または「AIに絵を描かせる行為」です。2014年ごろからベースになる技術が発表され始め、2022年に一気に普及しました。その起爆剤になったのはDall-E、MidJourneyやStable Diffusionなどの「無料で使えるAIお絵描きサービス」の公開です。
DALL-E初期バージョンは2021年に登場しましたが、正直「AIにしてはよく頑張って描いたね」くらいのレベルの画像で、人間の描く絵や写真にはとても及びませんでした。
しかし、2022年になると状況が一変します。
「Diffusionモデル」と呼ばれる手法が実装されたサービスが登場して、生成画像のレベルが一気に上がります。

よく「将来AIが人間の仕事を奪う」と言われますが、AIが奪う仕事はIT関連や単純作業などで、芸術に関わるような仕事はまだまだ人間のものだと思われてきました。
しかし、AIお絵描きのレベルがここまで上がってくると、「芸術は人間の牙城」とは言い切れなくなってきました。
ここ最近起きたこと
2022年にAI生成画像が話題になってから1年も経っていませんが、軽く今までのいきさつを振り返ってみます。以下の流れは主に日本国内での動きです。
AI画像反対運動のはじまり
私が知る限り、日本で起こった初の反AI画像運動は「mimic騒動」です。
本日、イラストレーターさんの絵の特徴を学んでイラストを生成するAI サービス mimic(ミミック)をリリースいたしました!
— mimic(ミミック) (@illustmimic) August 29, 2022
2回までイラストメーカー(イラスト生成AI)を無料で作成できますので、ご自分のイラストを学習させたい方は是非ご利用ください!https://t.co/fhVVFJUhQM pic.twitter.com/ZGTq8zVVcA
日本発のサービス「mimic(ミミック)」が「既存のイラストを学習し、そのタッチに似た全く新しい絵を生成するAIサービス」を公開すると、そのサービスに対して大きな反対運動が起こりました。
この時問題になったのは「他人の絵を勝手に学習させれば、その画風をパクり放題になる」という点です。
あまりの反対の多さにmimicは公開わずか1日でサービスを停止、半月後に利用規約を大幅に改訂して再公開しました。

新たに公開したmimicは「学習イラストが自分のイラストと証明できること」「顔のみのイラスト生成」「透かしは必須」という厳しい条件でのみAI画像を生成できます。
この規約改定はイラストを描く人々にはおおむね好意的に受け入れられましたが、利用者も用途も非常に限られたサービスになってしまいました。
これより少し後の2023年11月29日、お絵かきソフトの「CLIP STUDIO PAINT」が「画像生成AIパレット」の試験的実装を発表します。
このころにはすでに発表されていた「Stable Diffusion」(後述)を利用して、CLIP STUDIO PAINT内でプロンプトを入力し、テキストからイラスト(おもに背景?)を作り出せる機能になる予定でした。
しかし、この試験実装が発表されると再び大きな反対運動が起こり、このソフトの不使用を呼びかける人が現れるなど、mimic騒動と同様大炎上します。
これを受けてCLIP STUDIO PAINT開発会社のセルシスは3日後の12月2日にこの実装計画を撤回、AIによる画像生成は完全にタブーになりました。
この流れに対しては賛否両論あり、「イラストレーターに配慮した素晴らしい対応」という評価もあれば、「絵師の『お気持ち表明』に屈してAI市場を捨てた愚策」という厳しい意見もあります。
MidJourneyとStable Diffusionの登場
2022年7月13日、「MidJourney」のベータがリリースされました。これは「Discord」というチャットサービス(ブラウザで動くLineのようなものです)の上でAI画像を生成できるサービスで、英語での公開です。画風はいわゆる「コンセプトアート風」で、いかにも海外イラストといった感じです。

公開後しばらくして日本でも大きな話題になりましたが、大きな反対運動は起きませんでした。これは
- 英語の海外サービスなので、利用する日本人がそれほど多くなかった
- 画像を学習する機能がなく、既存の絵をパクるという利用が困難
- 学習モデルが非公開なので、学習元の絵のソースが不明
- 画風が日本のイラストと程遠い
といった理由が原因と考えられます。
MidJourneyやmimicと同時期、8月22日に「Stable Diffusion」が公開されます。日本では公開時はmimic騒動に隠れて大きな話題にはなりませんでした。
話題にならなかった理由はMidJourneyともかぶりますが、
- 情報が英語
- Pythonコードによる公開のため、プログラム知識がないと使えない
- いわゆる「フォトリアル」な生成画像なので、イラスト生成が難しい
などの点だと思います。
Stable Diffusion公開後まもなく、Automatic1111氏が「Stable Diffusion WebUI」を公開します。
これは、Stable Diffusionを自分のPC上だけで使うことができるツールです。この公開によって、Stable Diffusionの利用がとても簡単になりました。
こうしたAI生成の利用環境が整いつつある中、Stable Diffusionが大きく取り上げられるきっかけとなったサービスが公開されます。
Novel AI:「写実絵」から「二次元絵」へ
Stable Diffusion公開より少し前、「Novel AI」というAI文章生成サービスが2022年6月に公開されていました。その名の通り、「ノベル(小説)執筆をAIがアシストします」がウリのサービスです。
このNovel AIが2022年10月3日、Stable diffusionを使って日本のお絵描き界隈を震撼させるサービスを公開します。それが、「AIによる二次元画像生成サービス」です。

このサービスが生成するイラストは、今までのAI生成画像のような「いかにも洋風イラスト」だとか「写真風」ではなく、完全に「日本のイラストレーターが描くイラスト」そのものだったため、日本でもちょっとした騒ぎになりました。
Stable Diffusionは「モデル」と呼ばれるいわば「AIの脳みそ」を入れ替えることで様々な画風のイラストを描くことができます。
Stable Diffusion公式が提供したモデルは「写実的な画像」を描くことに特化していましたが、Novel AIは「日本風二次元イラスト」を描くモデルを独自に構築したのでした。
後に、このモデルが「Danbooru」という画像サービスにアップロードされた大量の画像を学習したモデルであることが明らかになります。これはイラストを描く人たちにとって大問題でした。Danbooruに上げられた大量の二次元イラスト画像はPixivなどの他の画像投稿サービスからの無断転載だったからです。
Stable Diffusionが今に至るまで絵描き界隈で悪名高いのは、Novel AIモデルのせいでもあります。
Novel AIの登場によって、「AIももしかしたら人間に負けないほど精巧な二次元イラストを描けるのではないか」という期待と不安が広がります。
Novel AIモデル流出事件~現在
2022年10月6日、なんとサービス開始わずか3日でNovel AIのモデルがハッキングにより流出、ネット上に公開されてしまいます。
先に公開されていた「Stable Diffusion WebUI」にNovel AIのモデルを読み込ませることで、AI二次元イラストが自分のPCで生成できてしまう、という環境がついに整うことになりました。

通称「Hello Asuka」
これをきっかけに、ネット上にAI生成イラストが溢れかえるようになります。
これと並行して、Novel AIやStable Diffusionのモデルに追加学習やマージ(複数のモデルをミックスすること)を行ったモデルが次々と公開され、AI生成画像の質も種類も飛躍的に向上していきます。
さらに、LoRAのような「描きたい画風をピンポイントで学習できる仕組み」が登場するに至り、もうAIお絵描きで描けないものはない、と言っても過言ではない状況になりつつあります。
2023年5月時点、AI素材やAI生成イラストを投稿するサイトが複数オープンしており、今後もAI生成画像のクオリティが上がっていくことが予想されます。
反AI運動
AIが描いたイラストに対しては、現在根強い反対意見があります。
法的な問題
AIによる生成画像の法的な問題に関し、いくつかの論点があります。
- AIが学習した絵はどこから来たのか
- 生成したAIイラストは著作権を侵害しないか
これらの解説は以前に書いたのでそちらをお読みください。
ひとことでいうと、「AI学習で著作権を気にする必要はない」、「生成イラストの使用は権利侵害や犯罪に抵触する用途でなければOK」です。
つまり、現状(2023年5月)は実質「イラストはパクられ損」な状態です。
この現状を変えるため、イラストレーターや漫画家有志で作る団体「クリエイターとAIの未来を考える会」が2023年4月に
- 画像生成AIの機械学習に著作物を使用する場合は事前に著作権の所有者に使用許可を得ること
- 画像生成AIの画像には、AIによる作品であることや元となった著作物の明示を義務づけること
- 著作者に対して使用料を支払うこと
などを求める提言を行っていますが、今のところ生成AI画像を著作権侵害に問うことは難しいと思われます。
提言と直接関係はありませんが、将来的に起こりうる著作権認定の厳格化を見越して「商用禁止」と明記するモデルも増えています。
「絵師」と「AI術師」
法的な問題に加えて、AIが描く「絵そのもの」に問題があると考える人も多くいます。
- 手描きのような温もりや個性がない
- どれもこれも似たような顔や画風ばかり
- 構図やバランスがおかしい、特に人の手が描けていない
- そもそも描いていない、印刷やコピーと同じ
これらの問題提起は、おもに「絵師」を名乗る人から多く出ています。
「絵師」とは、もともとは絵を描くことで生計を立てる職業のことですが、現在はTwitterなどのSNS上でイラストを描く人に対しての「敬称」(あるいは「自負」)という意味合いがあります。
つまり、イラストを描く人たちにとって、「絵師」とは「尊敬されるべき存在」という意味合いを含んでいます。
お絵描きAIが広く利用できるようになって以降、これを使って「自作のAIイラスト」をPixivなどに公開する人が現れ、画像投稿サイトがAI生成のイラストで溢れかえるようになりました。
「AI絵師」と名乗る人たちも多く現れましたが、彼らが「絵師」と名乗ることはもともとイラストを描いていた人たちには許しがたい事だったようで、「反AI絵師」の動きがますます活発化しています。
お絵描きAIを使用する人たちは、この流れを受けて「AI術師」という呼び名を生み出します。彼らの多くはもともとイラストを描いていたわけではなく、「絵師」という称号(?)にあまりこだわりがないため、現在ではAI術師と名乗る人の方が多くなっているようです。
※2023年5月現在、Twitterで「AI絵師」「AI術師」とそれぞれ検索すると、ユーザー名またはプロフィールで「AI絵師」と名乗っているアカウントは140ほど、「AI術師」は270ほどでした。
ちなみに、「絵師」といえば普通は二次元デジタルイラストを描く人たちを指しますが、「AI術師」の生成画像の対象はイラストだけではありません。彼らの多くはフォトリアルな画像、つまり写真のような三次元画像を生み出すことにも力を入れています。
YoutubeやTwitterで投稿されるAI生成画像は、三次元画像の方が多いように感じます。
この興味対象のズレは結構見過ごされがちですが、三次元AI生成画像を生み出す「AI術師」は「絵師」とは競合しません。
むしろ彼らを脅威に感じるのは3Dモデリング作成者、写真家やグラビアモデルといった人たちかもしれません。
締め出されるAIイラスト
AI生成画像が乱立するようになった理由の一つが、「手っ取り早く稼げる」ということです。
成人向け画像は特に儲かります。精彩でエロい絵を大量生産できるとなれば、稼ぐネタを探し続ける商売人たちに利用されないわけがありません。
日本最大の画像投稿サイトであるPixivは当初、AI生成画像に対して比較的寛容でした。「AI生成」であることを明記する必要はありましたが、AIイラスト投稿やAIイラストでの収益化を黙認してきました。
こんな状況に抗議すべく、Pixivに上げた自分のイラストをすべて非公開にするという動きが2023年5月ごろから起こります。ついにPixivもこの抗議活動を看過できなくなったのか、2023年5月10日、「AI生成イラストを使って収益化することを禁止する」と発表しました。
これに追従するように、Fantia、Fanbox、Ci-en、DS Liteといったコミュニティサイトや販売サイトでもAI生成イラストの取り扱いを禁止(一部例外あり)しました。
今はAI生成イラストを使ってコミュニティサイトで稼ぐことがどんどん難しくなっています*1。
今後起こりうること
今後、AI生成画像をめぐっては以下のような動きが起こる可能性があります。
AI画像の潜伏
「AI生成画像」と銘打って商売することが難しくなると、AI生成であることを隠して商売する人が現れるでしょう。昨今のAI生成画像は手描きや本物の写真と見分けがつかないほど精巧なので、気づかれない可能性もあります。
明らかにAIで描かれたと思われる絵でも、「これはAI画像だ」と証明する手段は今のところありません。結局は作者の自己申告なので作者に手描きであることを証明させる(お絵かきソフトの生データを提出させるなど)しかないのですが、おそらくこのチェックもすり抜けてしまうような技術が生まれてくるでしょう。
まるで潜伏レプリカント*2のように、AI生成画像は手描きイラストや本物の写真の中に紛れ込んでいきます。
そうなると、AI画像かどうかの判断は見る人の手にゆだねられることになります。
AI画像かどうかを見分けるのは完全に主観となり、手描きのイラストに対しても「これは手が描けてないからAI画像だ」というレッテル貼り、AI魔女裁判が引き起こされる可能性があります。
著作権論争
現在、多くの反AI活動は「AI生成画像で人の絵をパクリ、それを使って儲けている」という反感に基づくものが大半を占めています。
しかし、「人の絵をパクリ、それを使って儲ける」行為は手描きのイラストであっても可能で、実際、収益化サイトやイラスト売買サイトを見ると版権キャラを使った同人作品が多くやり取りされています。「二次創作禁止」や「エロ禁止」といった厳しい規約を設ける作品に対しても、それを破って儲けている手描き作家がいるのが実情です。
この状態を放置していると、「手描きなら版権キャラで儲けてもいいのに、なぜAI画像はダメなんだ?」という疑問が沸き起こるでしょう。
反AI生成画像を叫ぶ人たちの中には、「法律で規制しろ」とまで踏み込んだ発言をする人もいますが、これはやぶ蛇になる*3可能性があります。
なぜなら、AI生成画像を規制する法的根拠は「著作権侵害」しかなく、これを厳しくすることは手描きを含んだ同人活動を破壊することにもつながりかねないからです。
同人市場の大部分は業界黙認の二次創作コミュニティであり、著作権的にはアウトですが業界を盛り上げるために見逃されてきた側面があります。
「触れない方がみんな幸せ」という、微妙なバランスの上に成り立ってきたのが同人界隈といえます。
お絵描きAIをめぐる議論はこのバランスをぶち壊す可能性があり、「AIと共存」か「共倒れ」という究極の選択を迫られることになるかもしれません。
新手法として受け入れられる
AI生成画像はとても便利な技術です。今まで長い時間かかって描いていた画像を瞬時に作り出すことができます。この技術で最も恩恵を受けるのは今まで手描きで描いていたイラストレーターです。表現に幅が広がり、作業効率も上がるため、イラストレーターこそ最もこの技術を上手に利用できるはずです。
ソフト供給側もこのことを十分把握しており、NVIDIA、アドビやセルシスも新手法としてAI生成機能を搭載したソフトを発表しています。
※ただしCLIP STUDIO PAINTは反対意見が多く取り下げられてしまいましたが
プロのイラストレーターの中にはAI生成を利用して作品を生み出し始めている人もいます。こうした流れが加速すれば、AI生成イラストに対する抵抗感が薄れていくかもしれません。
後戻りはできない
AIが常にいいものとは限りませんが、AIは走り出してしまった暴走機関車のように技術発展が加速しており、誰にも止めることはできません。
AI画像生成の波も、もう止まらないと思います。仮に日本でAI反対の動きが大きくなっても、海外の「AI術師」は動きを止めないでしょう。
AIの新技術を拒絶し続けていると、日本でのAI技術発展が遅れ、しぶしぶ海外のAI技術を受け入れるしかなくなる、という事態になりかねません。
現在、日本はAI研究を進めるうえで他国と比べてかなり「甘い」規制下にあり、海外のAI企業も日本市場に大きく注目しています。
国は法規制に乗り出すでしょうか?現在はその兆しはありませんが、近い将来必ず議論の的になるでしょう。
個人的には「規制する方向にはいかないでほしい」と願っています。AI技術はパンドラの箱ですが私たちの創造活動がもっと豊かになる大きな可能性を秘めているので、誰もがハッピーになる方向で発展していってほしいと思います。
誰でもわかるStable Diffusion LoRAを作ってみよう(導入編)
Stable Diffusionはそのままでも十分きれいな画像を描いてくれますが、自分の好みに合った画風の絵を描いてくれなかったり、特殊な構図を指定しても理解してくれなかったり、いまいちかゆいところに手が届かない、と思うことがあるでしょう。
そんな時、Stable Diffusionに新たな絵柄や構図を教えて、自分の好みに近い絵柄や構図の画像を生成させることができます。
その仕組みが「追加学習」です。
追加学習の方法はいくつかありますが、今回は、現在主流になっている「LoRA」という手法について簡単に解説し、LoRA学習を行うのに必要なプログラムを導入する方法を説明します。
注意:
今回の解説にあるKohya_ssのインストール手順はWindow向けです。Mac/Linuxと共通する部分もありますが、手順はWindowsマシンにインストールすることを想定しています。
Loraとは
Loraとは「Low-Rank Adaptation」の略です。
以下がLoRAの仕組みの概要です。
- 「テキスト処理」の部分だけ追加学習する。
- 他の学習法と違ってベースモデルにはまったく手を加えずに、その代わり「小さなニューラルネットワーク」をベースモデルに新しく追加する。
- 「テキスト処理」を行う部分はStable Diffusion内にいくつもあるので、それぞれの部分に「小さなニューラルネットワーク」を追加する。
- 追加学習はこの複数の「小さなニューラルネットワーク」たちに対して行われる。
LoRAは以下のような素晴らしい特徴を持っています。
- 学習に使う画像の枚数が少なくてもかなり精度よく再現してくれる。
- 学習時間が他の方法よりも短い。10~20分程度で学習させることも可能。
- 学習された「小さなニューラルネットワーク」だけ配布できるので、サイズがとても小さい
これらの利点があるので、現在は「追加学習」といえばLoRAが主流になっています。
Lora学習環境の導入
Kohya氏が公開しているKohya_ssを使うのが簡単だと思いますので、この導入法を解説します*1。
Kohya_ssはウェブブラウザからアクセスする追加学習実行環境です。ウェブブラウザで動くといっても実行に必要なファイルはすべて自分のPCの中にあるので、追加学習を行うときにネット環境は不要です。
インストール前の準備
Pythonをインストール
まずここからPython(ぱいそん)のインストーラをダウンロードし、インストールしましょう。バージョンは3.10です。
Pythonは「実行環境」です。Kohya_ssやStable Diffusion WebUIは「Pythonコード」で書かれたファイルの集まりです。このままではただのテキストファイルにすぎませんが、Pythonがインストールされていると、これがコードを読み込んでプログラムとして実行してくれます。
Kohya-ssのファイルを自分のPCにコピー
Kohya_ssはGithubというサイトでソースコードが公開されていますので、そこにあるソースコードを自分のPCにコピーします。
そのために、ここから「Git」をダウンロードし、インストールしてください。
Gitとは、いわゆる「バージョン管理システム」で、プログラムの開発過程をすべて管理してくれるしくみです。多くのプロジェクトがGitを利用していて、Kohya_ssもGithubというサイトでGit管理されています(Gitは「仕組み」で、Githubは「Gitを導入しているサービスの名前」です)。
Gitのインストールが終わったら、Kohya_ssを自分のPCに持ってきます。
まず「コマンドプロンプト」を開きます。Windowsの画面の左下にある「ここに入力して検索」と表示されている検索欄に「cmd」と打ち込むと「コマンドプロンプト」がリストに現れるので実行しましょう。
実行したら、プロンプト内で「Kohya_ssのフォルダを置きたい場所」に移動します。
移動には「cd」というコマンドを使います。
Kohya_ssを置く場所はどこでも構いません。例えば「C:\application」というフォルダの中に置きたい場合は以下のようにコマンドをタイプします。
cd c:\application
すると現在位置が指定されたフォルダに移ります(フォルダ場所はお好みに応じて変えてください)。
次に、Kohya-ssのファイルをサーバから持ってきて、そこに置きます。
Gitには、Github上で公開されているソースコードを自分のPCに丸ごとコピーする機能があります。それが「git clone」というコマンドです。
コマンドプロンプトに以下のように入力しましょう。
git clone https://github.com/bmaltais/kohya_ss.git
ファイルのダウンロードが始まるはずです。しばらく待ちましょう。
ダウンロードが終わったら、コマンドプロンプトは閉じてかまいません。
Kohya_ssのインストール
コマンドプロンプトで指定したフォルダの中を見ると、「kohya_ss」というフォルダができているはずです。
そのフォルダの中の「setup.bat」というファイルをダブルクリックすると、再びコマンドプロンプトが開き、インストールが始まります。
インストール中、設定に関していくつか質問されます。以下は質問の内容と、おすすめの回答です。特にこだわりがない場合は以下のように回答してください。
1.もしpytorchが既にインストールされているなら、最初に以下のような質問があります。これはインストールされているtorchをアンインストールするかという質問です。
Do you want to uninstall previous versions of torch and associated files before installing? Usefull if you are upgrading from torch 1.12.1 to torch 2.0.0 or if you are downgrading from torch 2.0.0 to torch 1.12.1.
「No」を選んでください
2.インストールするtorchのバージョンを聞かれます。
Please choose the version of torch you want to install
「v1 (torch 1.12.1)」を選んでください
ここまで回答すると、必要な外部プログラムをダウンロードし始めます。しばらく待ちましょう。
外部プログラムをインストールし終わると、次の質問が表示されます。
3.kohya-ssをどの環境で実行するか聞かれます。
In which compute environment are you running?
「This machine」を選んでください
4.実行するマシンのタイプを聞かれます。
Which type of machine are you using?
「No distributed training」を選んでください
5.GPUを使わず、CPUのみで実行するかどうか聞かれます。
Do you want to run your training on CPU only (even if a GPU is available)?
「no」とタイプして決定キーを押してください
6.torch dynamoを使って実行高速化のための最適化を行うか聞かれます。
Do you wish to optimize your script with torch dynamo?
「no」とタイプして決定キーを押してください
7.実行高速化のためDeepSpeedを使いたいか聞かれます。
Do you want to use DeepSpeed?
「no」とタイプして決定キーを押してください
8.マシン上のどのGPUを使うか指定するよう求められます。
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list?
「all」または「0」とタイプして決定キーを押してください。ほとんどの場合「all」で問題ないでしょう。
※「all」を選んでインストールをした場合、GPUがうまく認識されずにエラーになる事があります。その時は、もしGPUがNVIDIA製なら、「コマンドプロンプト」を新たに開き「nvidia-smi」というコマンドを打ってGPUのIDを確認してください。多くの場合「0」だと思いますが、そうでない可能性もあります。確認後、再び「setup.bat」ファイルをダブルクリックし、インストール作業をやり直します。この選択肢まできたら、先ほど調べたGPUのIDをタイプします。
9.処理データタイプをfp16にするかbf16にするか聞かれます。
Do you wish to use FP16 or BF16 (mixed precision)?
Please select a choice using the arrow or number keys, and selecting with enter
「fp16」を選んでください
ここまで来たら、インストールは完了です。
コマンドプロンプトを閉じてください(または、勝手に閉じます)。
Kohya_ssを立ち上げてみよう
再びkohya_ssフォルダ内を見ると「gui-user.bat」というファイルがあるはずです。
これをダブルクリックすればコマンドプロンプトが開き、しばらくすると以下のように表示されます。

ここに表示されるURL(環境によって変わります。上の例の場合は「http://127.0.0.1:7860」です)をウェブブラウザのURL欄に入力すると、kohya_ssの画面がブラウザ上に表示されます。

まとめ
今回はStable Diffusionの追加学習の主流であるLoRAについて紹介しました。
また、LoRA学習環境として人気の高いKohya_ssの導入について解説しました。
LoRA学習法の詳細はまた別の記事で解説するつもりです。
*1:Kohya_ssはLoRA学習専門というわけではなく、ほかの追加学習手法にも対応しています
誰でもわかるStable Diffusion その11:VAE
前回の記事まではStable Diffustionの心臓部であるU-Netについて解説してきました。
ただのノイズから画像を作りだしていくのはU-Netの役割ですが、これだけでは画像は完成しません。
なぜならU-Netが作り出すものは「圧縮された画像」だからです。
絵を完成させるためにはこの圧縮された画像を展開して、元のサイズに戻す必要があります。
この、絵を圧縮したり展開したりする機能を「Variational Autoencoder」(ヴァリエーショナル・オートエンコーダー)、略して「VAE」と言います。
Stable Diffusionのしくみを語るとき、U-NetやTransformerに目が行きがち(Lora、Dreamboothなどの追加学習がU-Net対象なせいもあるでしょう)で、Stable DiffusionのVAEの機能は見落とされがちですが、それでも非常に重要なモジュールです。
今回はこのVAEについて見ていきます。
- VAEとは
- VAEの進化
- Stable DiffusionのVAEの特徴
- Stable Diffusionの潜在空間ってどうなってるの
- VAEエンコーダーは画像生成には不要
- VAEデコーダーのしくみ
- まとめ
VAEとは
私たちがふだん目にする画像は「ピクセル」で描かれた「ピクセル画像」です。
Stable Diffusionで作りたい画像も「ピクセル画像」です。
しかし、ピクセル画像は解像度が上がるたびにデータ量がどんどん膨大になり、大規模なマシンがないと計算できなくなってしまいます。
そこでStable Diffusionは画像を圧縮した状態でデータを作り、最後にVAEで展開してピクセル画像に変換して出力しています。
圧縮された画像のタテヨコのサイズはそれぞれ8分の1になります。
(ただし画像の場合はR、G、Bの3つのチャンネルを持っていますが、圧縮状態の画像はチャンネルが4つに増えます。)
圧縮前の画像と圧縮後のデータを比べると、データ量は48分の1になっています。
例えば512x512x3ピクセルの画像(最後の3はRGBチャンネル)を作りたい場合、生成される圧縮データのサイズは64x64x4です。
下の図はVAEの構造です。
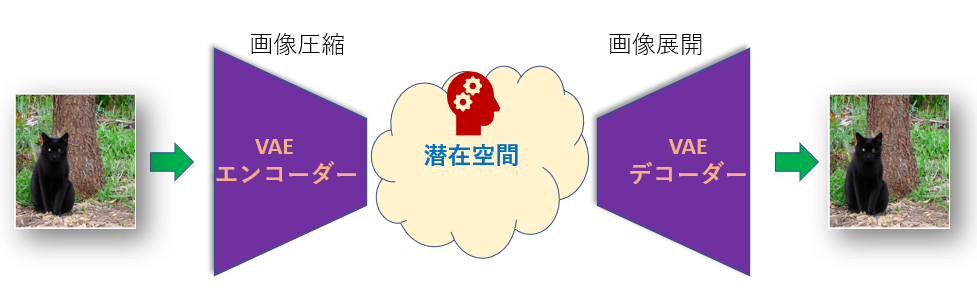
圧縮された画像は小さくなり、「Latent Space」(レイテント・スペース)、いわゆる「潜在空間」と呼ばれる情報空間に置かれます。
デコーダーは「潜在空間」にある画像を取り出して展開し、ピクセル画像に戻します。
VAEが作り出せるありとあらゆる画像データはこの「潜在空間」が保持しているわけです。
もともとVAEはStable Diffusionとはまったく別に提案された画像生成モデルです。
ここで、Stable Diffusionの構造を見てみましょう。

VAEの構造とよく似ていることがわかります。違うのは「潜在空間」の部分にU-Netが挿入されているところです。
つまり「Stable DiffusionはVAEの一種とみることもできる」のです。
U-Netは「潜在空間」で画像を作り出しますが、VAE的に解釈すると、U-Netは「潜在空間の中を泳ぎ回ってふさわしい絵を探し出す」という作業をやっていることになります*1。
VAEの進化
VAEは数年で何度も改良を重ねてきました。
画像を生成する技術として、まず「Autoencoder」(オートエンコーダー)というものが提案されました。これを発展させたものがVAEです。
さらにVAEを発展させたもののとして、Vector Quantized VAE、略して「VQ-VAE」が提案されました。
さらにさらに、QV-VAEを発展させたものとして「VQ-GAN」と呼ばれるものが登場しました*2。
VQ-GANは「VAE」という単語が抜け落ちていますが、VAEの一種です(正確にはVQ-VAE + GANです)。
Stable Diffusionで一般にVAEと呼ばれているものは、この「VQ-GAN」のことです。
これらすべて、「画像を圧縮、展開する」ことに関しては同じですが、画像の情報をどう保持するか、画像をどう復元、生成するか、という手法が違っています。
詳細は省きますが、VQ-GANはより精細な画像を生成できるとされています。

VAEは上の図のように機能が置き換わったり追加されたりする形で進化してきましたが、VQ-GANではU-Netでも使われているTransformerという仕組みが追加されたり、GANという画像生成メカニズムが追加されたり、まさに「いいところどり」な形態です。
これらの機能はVAEが学習して賢くなる時に特に大きな威力を発揮します。次のセクションではそれらについて概要だけ解説しますが、Stable Diffusionで画像を生成するだけならあまり意識する必要がないので、興味がなければ読み飛ばしてください。
Stable DiffusionのVAEの特徴
VAE(正確にはVQ-GAN)がどういうしくみなのか、具体的な特徴を見てみましょう。
ここで説明していることは主にVAEが画像を学習するプロセスです。興味ない方は読み飛ばしてもらっても構いません。
VAEは異次元世界への扉
絵をVAEエンコーダーに入れるとデータが小さくなりますが、この時、画像は「潜在空間」という異次元世界に飛ばされたと考えることができます。
画像は潜在空間に入ると、まず細切れに切り分けられます。そしてそれぞれの細切れが、それぞれ別の場所に置かれます。例えば、ある細切れが置かれた場所を住所で表すと「1丁目1番地1」だとします。少し短く書くと、[1, 1, 1]となります。
この「潜在空間の住所」こそが「圧縮されたデータ」です。もし細切れひとつが8x8ピクセルだったとする(簡単のため色はグレーのみとします)と、8x8=64個のデータが3個のデータに圧縮されたことになります。
画像を展開するときは、「潜在空間」の「1丁目1番地1」にある画像を現実世界に持ってくればよいのです。VAEデコーダーがその役割を担います。
潜在空間は区画整備されている
VAEエンコーダーを通して「潜在空間」に絵を入れたとき、絵の細切れを適当にバラまいてしまったら空間内がゴチャゴチャになってしまいます。「潜在空間」は無限に広がる膨大な空間ですが、だからといって絵の細切れを適当に放り投げて適当に住所を割り振っていくのは賢い方法とは言えません。
ちなみにVAEの先祖にあたるAutoencoderは実際そんな感じで適当に絵を潜在空間に突っ込んでいました。)
絵を機能的な形で潜在空間に置くために、以下のような整備計画を立てます。
- 同じような特徴を持つ細切れは近い場所に置いて、特徴ごとにまとまるようにする。
- デタラメに住所の数字を発行せず、有効な数字をあらかじめ決めておいて、その住所しか使えないようにする。
- 似たような細切れは1つにまとめる
これらに従って転送されてきた細切れを整理していくと、潜在空間内もスッキリして、のちにここから絵を復元するときに効率よく復元できるようになります。
3つ目の項目に注目してください。もし入ってきた細切れがすでに存在する細切れに似ている場合、すでに存在する細切れで代用します。
代用なので、オリジナルとは違うものになります。しかし、汎用性を上げる(いろいろな絵を効率的に保持できるようにする)ために、ある程度のロスは許容します。
「贋作師」と「鑑定士」が腕を競い合う
さて、潜在空間に入ってきた絵は細切れにされますが、細切れをつなぎ合わせれば理屈としては再び絵になるはずです。しかし、上で書いた通り、細切れの情報はオリジナルとは違っています。オリジナルとは違うものをつなぎ合わせて作る絵は、いわば「贋作」(ニセモノ)です。
元の絵を作る時はこれらの細切れを「現実世界の絵」に修復して、絵にします。
こうした、いわば「贋作師」の仕事をするのがVAEデコーダーです。
一方、現実世界(つまりVAEデコーダーの処理後)に「鑑定士」(Discriminatorと呼ばれます)を配置しておきます。この「鑑定士」は送られてきた絵が本物かニセモノかを細切れごとに鑑定し、「本物」「ニセモノ」のラベルをつけていきます。
学習の最初のうちは「贋作師」は未熟なので、「鑑定士」にすべて「ニセモノ」と見破られてしまうでしょう。「贋作師」はこの結果をもとに少し学習します。すると、次に作った絵は少しだけ「鑑定士」をだませるかもしれません。「贋作師」はさらに学習して腕を上げようとします。「鑑定士」のほうも負けじと少し学習してニセモノを見破る技術を上げます。
こうして「贋作師」と「鑑定士」が競い合うようにして腕を上げていき、ついには「贋作師」(つまりVAEデコーダー)が本物と見分けがつかないような絵を作り出せるようになります。
この贋作師と鑑定士が競い合って生成画像のクオリティを上げていく方法を「GAN」(Generative Adversarial Network、ギャンと発音されることが多いです)といいます*3。

本来、GANはVAEとは全く別に提案されたメカニズムです。
「VAEとGANを一緒に使ったらいいものができるんじゃないか」という発想で生まれたのがVQ-GANです。
Stable Diffusionの潜在空間ってどうなってるの
VAEの仕組みの概要を説明しましたが、実際Stable Diffusionの潜在空間のデータがどうなっているのか見てみましょう。
Stable Diffusionに以下のネコの画像を生成してもらいました。

サイズは512x512ピクセル、色チャンネルはRGBの3チャンネルです。
この画像のデータは潜在空間ではどうなっているのでしょう?
上でも解説した通り、潜在空間では画像データは圧縮されているのですが、強引に画像として出力してみると…

左は全チャンネル合成、右はCYMKチャンネルとして出力
思ったより画像っぽい?
タテヨコサイズは8分の1(64x64ピクセル)、チャンネルは4つです。
圧縮データとはいうものの、ネコの形も木の形もはっきり分かって、結構画像っぽいですね。
これを見ると、「画像をデザインするのはVAEでなくU-Net」だということが分かります。
ちなみに、潜在空間の各チャンネルを別に画像として表示させると以下のような感じ。

何となーく規則性が見えるような気がします。
VAEエンコーダーは画像生成には不要
上で書いた通り、VAEは「エンコーダー」と「デコーダー」でできているのですが、画像生成の時は「エンコーダー」は使いません。
今までの記事を読まれた方は、「画像を作る時にまずノイズ画像を用意するんじゃないの?」と思われるかもしれませんが、ノイズ画像は潜在空間で作られるのでVAEエンコーダーは必要ないのです。
つまり、例えば512x512ピクセルの画像を生成したい場合、512x512ピクセルのノイズ画像を用意してから潜在空間のデータに圧縮するのではなく、初めから潜在空間で64x64マスのノイズ画像データを作ってしまいます。
というわけで、エンコーダーは使用しないので説明は省略して、デコーダーの解説をします。
VAEデコーダーのしくみ
さて、潜在空間のデータはもう十分画像っぽいので、単純に8倍に拡大すればもう普通の画像になりそうなものですが、当然そんなに簡単ではありません。
具体的にStable Diffusionがどうやって潜在空間のデータを画像に戻しているのか見てみましょう。
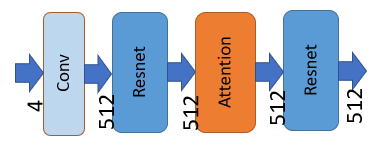
上の図は、VAEデコーダーが最初に行う処理です。矢印の下に書かれた数字は画像データの特徴チャンネルの数です。
U-Netの処理を終えた画像データは4つの特徴チャンネルを持っています。このデータがVAEデコーダーに送られ、VAEの処理が始まります。
まず、畳み込みを行います(畳み込みについては過去の解説を見てください)。
補足:
畳み込み前のチャンネルは4、畳み込み後のチャンネルは512です。ここで画像データから512個の特徴が取り出されたことになります。
次に「Resnet」、「Self Attention」、再び「Resnet」という3つの処理が行われます。
ResnetやAttentionはU-Netでも出てきましたのでリンク先の過去の記事を参考にしてください。Resnetは「特徴データの処理」、Attentionは「画像内の他の場所との関係を考慮したデータ変換」を担います。
U-Netのブロックとは詳細な処理内容は微妙に違いますが、やっていることはだいたい同じです。
次にデータは、たくさんの「Resnet」の流れ処理の中を通ります。

Resブロックと拡大の繰り返し
矢印の上に書かれた数字は画像データの特徴チャンネルの数です。
「Resnet」というブロックが12回繰り返し処理を行っていることが分かります。
そして、Resnetが3回処理を行うごとに「Up」ブロックがタテヨコサイズを2倍に拡大しています。
この「Up」ブロックでは、非常に単純な拡大を行い、そのあと特徴チャンネル数の変わらない畳み込みを1回行います。
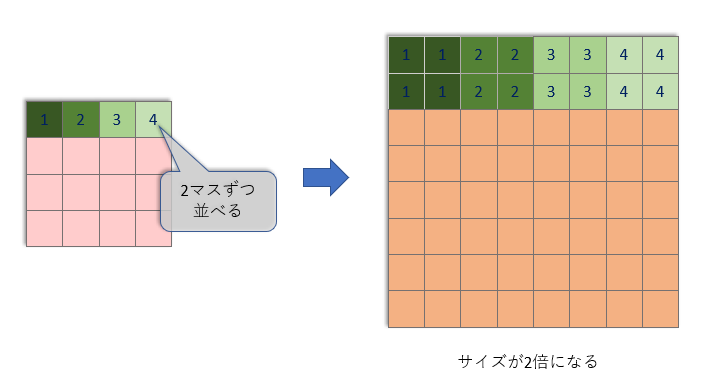
しかし、こんな単純な拡大(と畳み込み)だけでは、ぼんやりとした、色の薄い画像になってしまいます。
そこで、「Resnet」ブロックが「ぼんやりとした小さな画像」から「精細で大きな画像」を作り出す役割を果たします。この記事の上の方で書いた「贋作師」の仕事です。
上の流れ図を見ると、Upブロックを2回通った後で、特徴チャンネル数が減っていくことが分かります。特徴チャンネルを512チャンネルからだんだんまとめていき、最後には128チャンネルにまでまとめます。
そして、128チャンネルにまとまった画像データ(サイズはこの時点ですでに最終画像サイズになっています)は下の図で示された最終処理に送られます。

「Group Norm」では、128の特徴チャンネルは32チャンネルずつ、4グループに分けられ、グループごとに正規化されます。
「SiLU」は「非線形な要素」を入れるために使われます。
これらについて詳しく知りたい方は、過去の記事をご覧ください。
最後に畳み込みを行って128の特徴チャンネルをRGBの3チャンネルにまとめます。
以上がVAEデコーダーの変換処理です。
「潜在空間のデータを展開」と聞くと何か特殊な処理に聞こえますが、実際のところ畳み込みを繰り返して特徴をまとめ上げていく処理を行っているだけで、何も特別なことはありません。
まとめ
Stable Diffusionは「潜在空間」と呼ばれる圧縮された状態で画像生成を行います。
このおかげで大きなサイズの画像も比較的軽い処理で生成できます。
画像を潜在空間上のデータへ圧縮したり、逆にデータを展開して画像に戻す処理は「VAE」が行います。Stable DiffusionのVAEは「VQ-GAN」という手法を使っています。
画像を生成するときに使われるのは「VAEデコーダー」ですが、これは連続する畳み込み処理の集合にすぎません。
指定された絵を描き出していくのは主にU-Netが行いますが、潜在空間で作り出された画像データが最終的にきれいに出力されるには、VAEの処理も非常に重要なのです。