誰でもわかるStable Diffusion その10:U-Netの各ブロックの働き
前の記事まで、Stable Diffustionで使われているU-Netがどういう仕組みで画像データを処理しているのかをずっと見てきました。
一通り説明が終わったので、U-Netの全体像と、各ブロックが何をしているのかを少し詳しく眺めていきます。
U-Netについては以前少し紹介したのでその記事も参考にしてください。
注意
ここで説明するU-Netの構造はStable Diffusion独自のものです。
U-Netが必ずこういう形をしているわけではありません。
U-Netは3ブロック、5段階構造
Stable DiffusionのU-Netの構造は下の図の通りです。

上下で見ると、画像データのサイズの違いから4段構えになっています(下の2段は画像サイズが同じなので、これらを1段とカウントしています)。
左右で見ると、以下の3ブロックに分かれます。
- 画像を小さくしながら特徴を取り出していく「INブロック」(エンコーダーと呼ばれることもあります)
- 最小画像、最大特徴数を処理する「MIDブロック」(ボトルネックと呼ばれることもあります)
- 画像を大きくしながら特徴をまとめていく「OUTブロック」(デコーダーと呼ばれることもあります)
IN、MID、OUTもそれぞれ
- IN0からIN11までの12ブロック
- MID
- OUT0からOUT11までの12ブロック
の合計25ブロックに分かれます。
さて、上下の各段を見ると、INでは基本的に1段が2つのINブロックで構成されていることが分かります。OUTでは1段が3つのOUTブロックで構成されます。
つまり、INでは2つのブロックが同じサイズの画像データを処理します。OUTでは3つのブロックが処理をします。
IN、MID、OUTの各ブロックを見てみると、さらに処理を細かく分けることができます。
例えばIN1を見てみると、「Resブロック」と「Attention」ブロックの2つからできています。
MIDブロックは「ResーAttentionーRes」というサンドイッチ構造をしています。
下段のIN10、IN11、OUT0、OUT1、OUT2では「Resブロック」しかありません。
このように、ブロックによって処理も違います。
各ブロックの処理と特徴
さて、ここからは各ブロックの主な特徴を見ていきます。
注意
- 分かりやすくするために、以下の説明で処理される画像データのサイズは「タテ64xヨコ64」とします。
- Attentionブロックで画像に反映されるトークン(テキスト単語)の影響の強さは「弱、中、強」で表します。
- トークンが画像中のどれくらいの範囲に反映されるかは「全体的、やや微細、微細構造、超微細構造」で表します(ただしこの範囲は画像やトークン内容によって変わる可能性があります)。
INブロックの処理
IN0
処理:畳み込みのみ
入力サイズ:タテ64xヨコ64x特徴4
出力サイズ:タテ64xヨコ64x特徴320
IN1
処理:Resブロック、Attentionブロック
入力サイズ:タテ64xヨコ64x特徴320
出力サイズ:タテ64xヨコ64x特徴320
トークンの影響:弱、全体的
IN2
処理:Resブロック、Attentionブロック
入力サイズ:タテ64xヨコ64x特徴320
出力サイズ:タテ64xヨコ64x特徴320
トークンの影響:中、全体的
IN3
処理:畳み込みのみ(サイズ縮小)
入力サイズ:タテ64xヨコ64x特徴320
出力サイズ:タテ32xヨコ32x特徴640
IN4
処理:Resブロック、Attentionブロック
入力サイズ:タテ32xヨコ32x特徴640
出力サイズ:タテ32xヨコ32x特徴640
トークンの影響:強、全体的
IN5
処理:Resブロック、Attentionブロック
入力サイズ:タテ32xヨコ32x特徴640
出力サイズ:タテ32xヨコ32x特徴640
トークンの影響:弱、微細構造
IN6
処理:畳み込みのみ(サイズ縮小)
入力サイズ:タテ32xヨコ32x特徴640
出力サイズ:タテ16xヨコ16x特徴1280
IN7
処理:Resブロック、Attentionブロック
入力サイズ:タテ16xヨコ16x特徴1280
出力サイズ:タテ16xヨコ16x特徴1280
トークンの影響:中、全体的~やや微細
IN8
処理:Resブロック、Attentionブロック
入力サイズ:タテ16xヨコ16x特徴1280
出力サイズ:タテ16xヨコ16x特徴1280
トークンの影響:中、全体的
IN9
処理:畳み込みのみ(サイズ縮小)
入力サイズ:タテ16xヨコ16x特徴1280
出力サイズ:タテ8xヨコ8x特徴1280
IN10
処理:Resブロック
入力サイズ:タテ8xヨコ8x特徴1280
出力サイズ:タテ8xヨコ8x特徴1280
IN11
処理:Resブロック
入力サイズ:タテ8xヨコ8x特徴1280
出力サイズ:タテ8xヨコ8x特徴2560
MIDブロックの処理
MID
処理:Resブロック、Attentionブロック、Resブロック
入力サイズ:タテ8xヨコ8x特徴2560
出力サイズ:タテ8xヨコ8x特徴1280
トークンの影響:強、全体的~やや微細
OUTブロックの処理
OUT0
処理:Resブロック
入力サイズ:タテ8xヨコ8x特徴1280+IN11出力(タテ8xヨコ8x特徴1280)
出力サイズ:タテ8xヨコ8x特徴1280
OUT1
処理:Resブロック
入力サイズ:タテ8xヨコ8x特徴1280+IN10出力(タテ8xヨコ8x特徴1280)
出力サイズ:タテ8xヨコ8x特徴1280
OUT2
処理:Resブロック
入力サイズ:タテ8xヨコ8x特徴1280+IN9出力(タテ8xヨコ8x特徴1280)
出力サイズ:タテ16xヨコ16x特徴1280
OUT3
処理:Resブロック、Attentionブロック
入力サイズ:タテ16xヨコ16x特徴1280+IN8出力(タテ16xヨコ16x特徴1280)
出力サイズ:タテ16xヨコ16x特徴1280
トークンの影響:弱、微細構造
OUT4
処理:Resブロック、Attentionブロック
入力サイズ:タテ16xヨコ16x特徴1280+IN7出力(タテ16xヨコ16x特徴1280)
出力サイズ:タテ16xヨコ16x特徴640
トークンの影響:強、微細構造
OUT5
処理:Resブロック、Attentionブロック
入力サイズ:タテ16xヨコ16x特徴640+IN6出力(タテ16xヨコ16x特徴1280)
出力サイズ:タテ32xヨコ32x特徴1280
トークンの影響:中~強、やや微細
OUT6
処理:Resブロック、Attentionブロック
入力サイズ:タテ32xヨコ32x特徴1280+IN5出力(タテ32xヨコ32x特徴640)
出力サイズ:タテ32xヨコ32x特徴640
トークンの影響:強、超微細構造
OUT7
処理:Resブロック、Attentionブロック
入力サイズ:タテ32xヨコ32x特徴640+IN4出力(タテ32xヨコ32x特徴640)
出力サイズ:タテ32xヨコ32x特徴320
トークンの影響:強、微細構造(対象トークンに関連する部分?)
OUT8
処理:Resブロック、Attentionブロック
入力サイズ:タテ32xヨコ32x特徴320+IN3出力(タテ32xヨコ32x特徴640)
出力サイズ:タテ64xヨコ64x特徴640
トークンの影響:強、全体的~微細構造(対象トークンに関連する部分?)
OUT9
処理:Resブロック、Attentionブロック
入力サイズ:タテ64xヨコ64x特徴640+IN2出力(タテ64xヨコ64x特徴320)
出力サイズ:タテ64xヨコ64x特徴320
トークンの影響:強、全体的
OUT10
処理:Resブロック、Attentionブロック
入力サイズ:タテ64xヨコ64x特徴320+IN1出力(タテ64xヨコ64x特徴320)
出力サイズ:タテ64xヨコ64x特徴320
トークンの影響:弱、全体的
OUT11
処理:Resブロック、Attentionブロック
入力サイズ:タテ64xヨコ64x特徴320+IN0出力(タテ64xヨコ64x特徴320)
出力サイズ:タテ64xヨコ64x特徴4
トークンの影響:中、全体的~やや微細
U-Netが作り出すもの
前の記事でも解説したとおり、U-Netは「ノイズだらけの絵」を取り込んで、その画像をもとに「絵に乗っているノイズ」を予想して、ノイズだけを出力します。
つまり、OUT11ブロックが最終的に出力するものは「予想ノイズ画像」です。
U-Netが出力した「予想ノイズ」を元の「ノイズだらけの絵」から引けば、「ノイズのない絵」ができる、という仕組みです。
もしU-Netが予想して作った「ノイズ画像」が完全に正しいなら、ノイズだらけの絵からこのノイズ画像を引けば一発で完全に正しい絵ができるはずです。
しかし、予想が完全に正しいということはあり得ません。そこで、この「予想ノイズ画像」を弱めて(薄めて)、元の絵から少しだけノイズを引くようにします。
元の絵にはまだノイズが残っているので、またU-Netに突っ込みます。U-Netはまた乗っているノイズを予想し、出力します。
こうしてU-Netの処理を繰り返して絵を完成させていきます。
この「ノイズを予想する」処理を「サンプリング」と言い、予想を繰り返す回数を「サンプリングステップ」と言います。
上で「ノイズだらけの絵から予想ノイズを引く」と書きましたが、「画像生成のどの段階でどれだけノイズを引くか」を決めるのが「サンプラー」(または「スケジューラー」)と呼ばれるモジュールです。
あるサンプラーでは生成の最初から最後まで毎回ほぼ一定量のノイズを引き続けます。
他のサンプラーでは生成初期の段階ではノイズをごっそりと引き、絵からノイズが少なくなったら今度は少しずつノイズ引いていきます。
生成方法が違うので、サンプラーによってできる絵が微妙に違います。
(サンプラーについてはまた後日機会があれば解説します)
まとめ
U-Netの各ブロックが何をしているのかを全体的に見ました。
IN、MID、OUTの3パートに分かれていて、INでは画像を縮小しながら特徴抽出、OUTでは画像を拡大しながら特徴をもとに新たな画像を作り出していく働きがあります。
各ブロックは一見似たような処理を行っているように見えて、役割はそれぞれ微妙に違うようです。
画像データはこのU-Netを通り抜けて、「予想ノイズ画像」に変換されます。
これを使って元の画像データから少しずつノイズを取り除き、絵を完成させるのです。
U-Netの解説はこれでおしまいです。
誰でもわかるStable Diffusion その9:U-Net(画像データの縮小、拡大)
Stable Diffusionの心臓部であるU-Net解説の9回目です。
これまでU-Netの重要なパーツであるResブロック、Attentionブロックを見てきました。
すでに解説したこれらのブロックでは処理によって画像データのサイズは変わりませんでした。
しかし、処理によって画像のサイズが変わるブロックもあります。今回はそれらを見ます。
そもそもなぜ縮小するの?
そもそも、画像データのサイズを小さくすることに何の意味があるのでしょう?
これには「特徴抽出」が大きく関係しています。
以前の記事で、「U-Netは特徴発見機を使って画像データをスキャンして、画像内の特徴を取り出していく」という解説をしました。
この特徴発見機、別名「フィルター」は3x3マスの大きさで固定です。
さて、仮に画像データサイズが64x64マスとすると、3x3マスの特徴発見機が発見できるものは何でしょう?*1おそらく画像内の細かな特徴、例えばネコの画像であれば毛の質感、目の特徴、鼻の形などでしょう。
しかし、この大きさのフィルターでは「ネコの顔つき」「ネコの取っているポーズ」や「背景のレイアウト」など、画像が持つ大きな特徴をとらえることができません。そこで、画像を小さくします*2。
画像サイズを半分、32x32にすると、同じ3x3のフィルタでも少し広範囲の特徴をとらえられるようになります。ネコの顔全体くらいはカバーできるようになるかもしれません。
さらに半分、16x16にすると、ネコの体全体もカバーできるかもしれません。8x8であれば背景とネコの位置関係までカバーできるかもしれません。
このように、U-Netでは、まず画像の持つ細かい部分の特徴から抽出していき、画像を小さくすることによって画像の持つ大まかな特徴も抽出していきます。
しかし最終的には元と同じ大きさの画像データが欲しいので、画像を再び拡大していき元の大きさに戻します。
(この時、取り出してきた大小さまざまの特徴を使って画像を再構成していきます。)
拡大、縮小はU-Netによって行われます。具体的にどこで行われるか見てみましょう。
U-Netで縮小、拡大
U-Netは大まかに「INブロック」「MIDブロック」「OUTブロック」の3つからできています。下の図を見てください。
- 左側の緑色のラベルが付いたブロックたちが「INブロック」
- 一番下の黄色のラベルが付いたブロックたち(3つの四角)が「MIDブロック」
- 右側の赤色のラベルが付いたブロックたちが「OUTブロック」
この図の上下位置は「画像データサイズの大きさ」を表しています。下に行くほどサイズが小さくなっています。
図を見て分かる通り、最初は処理ごとにどんどん下に下がっていき、MIDブロックを境にまたどんどん上に上がっていきます。
(この形が「Uの字」に似ているので「U-Net」と呼ばれます)
つまり、INブロックでは画像がどんどん小さくなり、OUTブロックで画像がどんどん大きくなり、元の大きさに戻ります。
INで画像縮小
さて、どれだけ画像が小さくなるかというと、図の中の「Down」と書かれたブロックを通るごとにタテヨコのサイズがそれぞれ半分になります(データ数が4分の1になります)。
「Down」ブロックはIN3、IN6、IN9の3つです。つまり3回縮小されます。
IN3では元のサイズの2分の1に、IN6では元のサイズの4分の1に、IN9では元のサイズの8分の1になり、MIDブロックにたどり着くころには画像サイズは8分の1になっています。

上の図は、画像データが16x16の時の例です。
IN3ブロックを通ると画像サイズが8x8になり、IN6ブロックでは4x4、IN9を通ると2x2になり、最終的には元の画像データの8分の1の大きさになっていることが分かります。
OUTで画像拡大
OUTブロックでは、画像が3回拡大され、最終的にサイズが元に戻ります。
画像拡大を行うブロックはOUT2、OUT5、OUT8の3つです。
INブロックでの縮小とは逆に、OUTブロックでは1回拡大されるごとに画像データサイズが2倍になります。3回拡大されるので、最終的に画像サイズが最小時に比べて8倍、つまり元の画像データのサイズになります。
さて、どうやって画像を縮小、拡大しているのでしょう?
画像の縮小、拡大は「畳み込み」
縮小は「畳み込み」を使って行われます。拡大の場合は「補完」によって行われますが、補完処理のあとに畳み込みも行われます。
畳み込みについては、以前の解説記事をご覧ください。
INの縮小処理はDownブロックの畳み込み
上のU-Netの図の「Down」と書かれたブロックは、畳み込みを1回だけやっています。
畳み込みによって画像が縮小する仕組みは簡単です。

畳み込みは、画像データにフィルターを重ねて、重なった部分から新たに1つの数字を取り出す処理です。以前の解説記事に出てきた畳み込みでは、フィルターは画像データ上を1マスずつずらしていました。1マスずつずらした場合、元の画像データと畳み込み後の画像データのサイズは同じになります*3。
このずらし(ストライドと言います)を2マスにすると、フィルターは画像データを毎回1マス分スキップしながらスキャンすることになります。つまり、画像データのサイズが半分になるのです。
このストライドの数によって畳み込み後のデータサイズが決まります。ちなみにフィルターのサイズは関係ありません。2x2でも3x3でもストライドが2であればサイズは半分になります。
OUTの拡大処理は補完と畳み込み
INに「Down」というブロックがあるので、OUTに「Up」というブロックがあってもよさそうなものですが、拡大のときは単独では行われません。ResブロックやAttentionブロックに引き続いて行われるので、それらのブロックと同じところ(OUT2、OUT5、OUT8)に所属しているという扱いです*4。
上のU-Netの図のOUT2、OUT5、OUT8を見てもらえばわかるとおり、まずResブロックやAttentionブロックで処理が行われ、拡大はそれらの処理の後に行われます。
拡大処理ですが、畳み込みを使って画像データ拡大する方法もありますが、Stable DiffusionのU-Netではもう少し単純な方法で拡大を行っています。
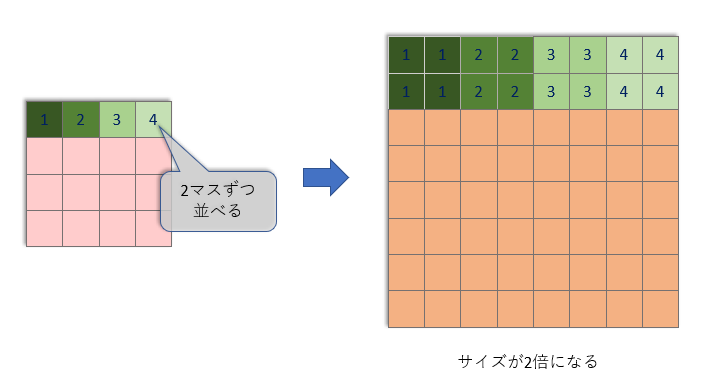
単純に、1マスごとに同じものをタテヨコに2つ並べるだけです。「補完」といいます。
これでサイズは2倍になりますが、これだけではありません。
Stable Diffusionはこの後にサイズが変わらない畳み込みも1回行っています。
ここで畳み込みをする理由は、「この畳み込みが学習によって賢くなるから」です。単純に同じデータを2個並べるだけより賢く拡大できます。
さらに、畳み込みは特徴情報をまとめる役割も果たすので、拡大の時に画像データに特徴情報を反映させることもできます。
縮小の時とは違って畳み込みによって画像サイズを変えているわけではありませんが、ここでも畳み込みは重要な役割を果たしています。
まとめ
U-Netは画像データを縮小しながら細かい特徴から大まかな特徴までたくさんの特徴を抽出していきます。これら抽出した特徴情報をもとに、画像データを再拡大しながら出力データを作り上げていきます。
INブロックでは縮小処理が畳み込みによって行われます。OUTブロックでは拡大処理が補完と畳み込みによって行われます。
これでU-Netで行われている処理はだいたい見終わりました。
次回はIN、MID、OUTのそれぞれのブロックの処理をまとめます。
*1:ここでは分かりやすさのために画像データを「ピクセルデータ」として説明しています
*2:画像を縮小するのでなくフィルターを大きくすればいいのでは、と思われるかもしれませんが、そうすると計算量が増えてしまい効率的ではありません
*3:画像の端っこの処理には注意する必要があります。フィルターが画像からはみ出ている場合、はみ出た部分をどうするかを決めておかなければなりません。
*4:別に拡大処理を単独ブロックとみなしてもかまわないのですが、Stable Diffusionの実装を見ると単独ブロックにはなっていないので、ここではResやAttentionブロックに付随しているという扱いにしています
誰でもわかるStable Diffusion その8:AttentionとTransformer
前回はU-Netの「テキストを取り込む」機能であるAttentionブロックを見ましたが、その中で特に大切な「Attention」パートについては概要しか説明しませんでした。
今回はそのAttentionについて詳しく見ていきますが、その前にAttentionを行うメカニズムである「Transformer」についても少し説明します。
- はじめに:Attentionさえあれば
- Transformerのしくみ
- Attentionとは
- Stable DiffusionのSelf Attention
- Stable DiffusionのCross Attention
- まとめ
はじめに:Attentionさえあれば
2017年のことでした。グーグルの研究グループからある論文が発表されます。

タイトルは「Attention Is All You Need」、邦題をつけるなら「アテンションさえあれば」という感じです。ビートルズの曲名「Love Is All You Need」を意識してつけられたのでしょう。
ここで「Attention」という概念と「Transformer」というメカニズムが提唱されました。
文の中の言葉は1つ1つ独立しているわけじゃなく、お互いの関係や順番によって意味合いが変わります。だから言葉どうしや対になる文(翻訳など)との関係に注意を向けて(Attention)、それぞれの言葉が文中でどういう意味合いを持っているかを調べることが重要です。
この処理を行うことができる「Transformer」というアーキテクチャを提案します。
この論文は言葉を扱う人工知能の世界に革命を起こします。Transformerがあまりにも優秀だったため、あっというまに既存のメカニズムにとって代わり、2023年現在ではほとんどの人工知能がTransfomerを何らかの形で使用しています。
今話題のChatGPTもこれを使っています。
Transformerは最初は言葉を扱うために提案されたものですが、のちにこれが他のモダリティ、例えば画像や音声の処理にも使えることが分かってきました。
Stable Diffusionは「言葉と画像を比べる」処理にTransformerを使っています。
Transformerのしくみ

Transformerのしくみ
Stable Diffusionの画像処理では右側だけ使っています
上の図は論文の中で説明されたTransformerの中身ですが、左右二つのパーツで構成されていることが分かります。左のパーツは「エンコーダー」、右のパーツは「デコーダー」と呼ばれます。
Stable Diffusionでは、左側のエンコーダーは「入力されたテキスト(プロンプト)」の処理を行い、右側のデコーダーが「テキストを取り込んで画像を書き換える」処理をしています。
エンコーダーブロック
エンコーダーがやっているのは、「テキスト内の単語(トークン)を数字(ベクトル)に変換すること」です。
テキストデータは人工知能にとって扱いづらいので、数字化するのです。
ただし、ただ単純にトークンを決められたベクトルに変換するのではなく、テキストの中でそのトークンがどういう意味合いを持っているかを考慮して、それに見合ったベクトルを作り出しています。
この「トークンにふさわしいベクトルを作る」部分でAttentionが行われます。
ただ、Stable Diffusion自体はテキスト変換処理をやっていません。
よその処理プログラムを流用しているだけで、Stable Diffusionはエンコーダー部分にはノータッチなのです。
そのため、Stable Diffusionに画像やキャプションをどれだけ学習させても、テキスト処理は賢くなりません。
(ちなみに、学習しても賢くならないパーツは俗に「固まっている」(Frozen)と呼ばれたりします)
ほかのStable Diffusionの解説記事で「Text Encoder」(テキストエンコーダー)というパーツを見かけることがあると思いますが、まさにそれがここでいうエンコーダー部分です。
デコーダーブロック
デコーダーブロックはStable Diffusionが使っている部分です。
上の図はちょっと難しいので理解する必要はありません。
下の図はStable Diffusionの心臓部、U-Netの中にある「Attentionブロック」の構造ですが、これがTransformerのデコーダーブロックとほぼ同じことをやっています。

本質的にはTransformerのデコーダーと同じ
Attentionブロックに関しては前回の記事を参考にしてください。
ここで最も重要な処理は「Self Attention」と「Cross Attention」です。
Attentionとは
では、いよいよAttentionについて詳しく見ていきましょう。
まず、Cross AttentionとSelf Attentionが何をしているかをたとえで説明してみます。
Attentionについて分からなくなったら例えを(もし参考になるなら)参考にしてください。
Cross Attentionを婚活に例えると
あなたが結婚相談所に登録するとします。
そこには3人のアドバイザー、Qさん、Kさん、Vさんがいます。
- Qさんはあなたに「相手に対する希望」をまとめるためのアドバイスをします。
- Kさんはあなたに「自分のプロフィール」をまとめるためのアドバイスをします。
- Vさんはあなたに「相手に見せたい自分自身」を準備するようアドバイスします。
3人のアドバイザーはとても優秀なので、相談所のメンバーは絶対にウソをつけません。そうしてメンバー全員、完璧に準備を整えます。
さて、あなたは「相手に対する希望」(仮にQ文書と呼びます)と候補者から送られてきた「プロフィール」(仮にK文書と呼びます)を比べます。
自分のQ文書と相手のK文書がよくマッチする候補者もいれば、ほとんどマッチしない候補者もいるでしょう。とにかく候補者全員のK文書と自分のQ文書を比較します。
比較した後で、相談所主催のイベントに出席して候補者全員と会うことにします。
あなたは自分のQ文書とよくマッチしたK文書を持つ候補者を重要視し、「よく知りたい」と思うでしょう。逆にそれほどマッチしなかった候補者にはあまり関心を示さないでしょう。
実際に会ってみると、候補者たちはVさんのアドバイスに従って「相手に見せたい自分」(仮にVと呼びます)をあなたに見せてくれます。
イベント終了後、あなたは候補者たちについて思い返します。
QとKがよくマッチした候補者の印象Vが、あなたの心に強烈に焼き付いています。あまりマッチしなかった候補者のことは、ほとんど忘れているでしょう。
もし同じぐらいマッチした候補者が2人いたら、その2人の印象Vが半分ずつ混ざり合って心に残ります。
こうして、あなたの心に「混ざり合ったV」が生まれるのです。
Cross Attentionの目的は、この「混ざり合ったV」を生み出すことです*1。
Self Attentionを婚活に例えると
さて、前の例えでは「自分の希望」と「婚活相手のプロフィール」を比べました。
しかし、あなたはこの相談所にいるライバル(つまり同性)たちのプロフィールも気になっています。
あなたにとってより理想的なプロフィールを持ったライバルを真似たいものです。
そこで、あなたはアドバイザーにそのことを相談します。
するとアドバイザーQさんが「では、なりたい自分についてまとめてみましょう」と言いました。あなたは「なりたい自分」を正直に書き出し、まとめます(今回はこれをQ文書と呼びます)。
「なりたい自分」を書き出した後、ライバル全員の「プロフィール」(K文書)と比べます。QとKがよくマッチしたライバルのことは結構気になります。
さて、イベントであなたはライバル全員を見かけることになります。QとKがよくマッチしたライバルがいたら、その人物が持つ「見せたい自分」(V)をよく観察します。あまりマッチしなかったライバルについてはそれほど観察する必要はないでしょう。
イベント後、ライバルたちについて思い返します。参考にすべきVは大いに参考にし、あまり興味のないVはほどほどに、そうして自分の中で「混ざり合ったV」を作り出して自分磨きに使います。
Self Attentionも結局はこの「混ざり合ったV」を作るのが目的です。
CrossとSelfの違いは、「誰と比較するか」ということだけです。
ただしCross Attentionのアドバイザー3人とSelf Attentionのアドバイザー3人は別人であることに注意してください。
Stable DiffusionのSelf Attention
以上の例を踏まえて、Stable DiffusionのAttentionがどういう処理をしているか見ていきましょう。まずはSelf Attentionから。
以下はIN1ブロックのSelf Attentionの説明です(ブロックが変わるとデータのサイズが変わりますが、行う処理は一緒です)。
入力される画像のサイズは、ここでは64x64とします。これは320個の「特徴チャンネル」を持っています。
1.データをフラットに
まず、このデータを平べったくします。64x64x320の3次元データを4096x320の2次元データに再構成します。積みあがったブロックを平べったく並べ替えるだけです。

これをAttention処理に入力します。

2.マルチヘッド化
平べったくなった画像データを3つに複製します。それらをそれぞれ、タテに8つ*2に切り分けます。
ここでは、40個の特徴チャンネルごとにグループ分けされたことになります。
以降、これら8つのデータは別々に処理されます。複数に切り分けて別々に処理する仕組みを「Multi Head Attention」と呼びます。
3.Q、K、Vに変換
この後の処理が非常に重要です。
複製されたデータはそれぞれ別のニューラルネットワーク(歯車のついた頭のアイコン)を通り、クエリ(Q)、キー(K)、バリュー(V)というデータに変換されます。これら全部、変換前と変換後のサイズは同じ(4096x40)です。
- Qは比較するためのデータ
- Kは比較されるためのデータ
- Vは置き換え用のデータ
です。
4.QとKを比較
変換後、すべてのマス(4096個)同士で自分のQと相手のKを比較します。比較するとは、数学的に言えば「内積を計算する」ということです。
内積を知りたい人向け:計算法は以下の通りです。
今回は、それぞれのマスが40個の数字を持っています。マス1とマス2を比べたい場合、それぞれが持つ40個の数字を重ね合わせ、重なる数字どうしを掛け、それらを全部(40個)足します。
計算結果として、1つの数字が出てきます。
40個の数字の並びが似ている場合、計算結果は大きな数字になります(本質的には畳み込みと同じです)。
こうして、それぞれのマスが(自分自身も含め)すべてのマスと比較した結果、4096x4096の比較マップが出来上がります。
これはエクセルの表と同じです。行が自分のマス、列が比較対象のマスを表し、それぞれのセルの中の数字が「どれだけ関係が深いか」を表します。
この中に入っている数字が大きいほど「そのマス同士の関係が深い」ということになります。
次に比較マップ内の数値を小さくします。
今回、各マスが持っている数字(特徴)は40個の数字ですが、これが80個、160個…と増えていったら、比較マップの中の数値もどんどん大きくなります。なので、比較マップ内の全部の数字を特徴数に応じて割り算することで、数値を一定範囲に抑えます。
具体的には、特徴数の平方根で割ります。
数字を一定範囲に抑えたら、今度は正規化します。
これには「SoftMax」という方法を使います。これによって比較マップ内の全ての数字が0から1の範囲に収まり、しかも同じ行の数字をすべて足すと必ず1になります。
SoftMaxを知りたい人向け
同じ行のすべての数を指数関数に代入し、この結果を使って同じ行内で正規化します。
つまり、数字が大きくなればなるほど指数関数的に重みが増えます。
5.Vを重み付けて足す
さて、いよいよ最後です。これが最も重要な処理です。
上の図のVの処理を見てください。Vは4096x40のデータです。このVこそが「元のデータに置き換わるデータ」です。
具体的には、比較マップとVデータを掛け算します。
行列計算を忘れてしまった人向けに説明すると、4096x4096のデータと4096x40のデータ掛け算すると、結果は4096x40になります。
Vデータ内の4096行すべてが足しこまれるのですが、ここで、比較マップはVデータのそれぞれの行を「重み付け」する役割を果たしています。
つまり、関係の深い行はより多く、関係の薄い行はより少なく、足しこみます。
上の婚活の例えでいえば「混ざり合ったV」を作る作業です。
6.マルチヘッドを再結合

上のQ、K、V処理はヘッドごとに別々に行われます。処理後、それぞれの結果をまたくっつけて、8つの4096x40のデータを1つの4096x320のデータに戻します。
これでSelf Attention処理は終了です。出てきたものは「混ざり合ったV」です。
つまり「Vこそが新しいデータの本体」なのです。
Stable DiffusionのCross Attention
Cross Attentionもやっている処理自体はSelf Attentionとほとんど同じですが、扱うデータが違います。
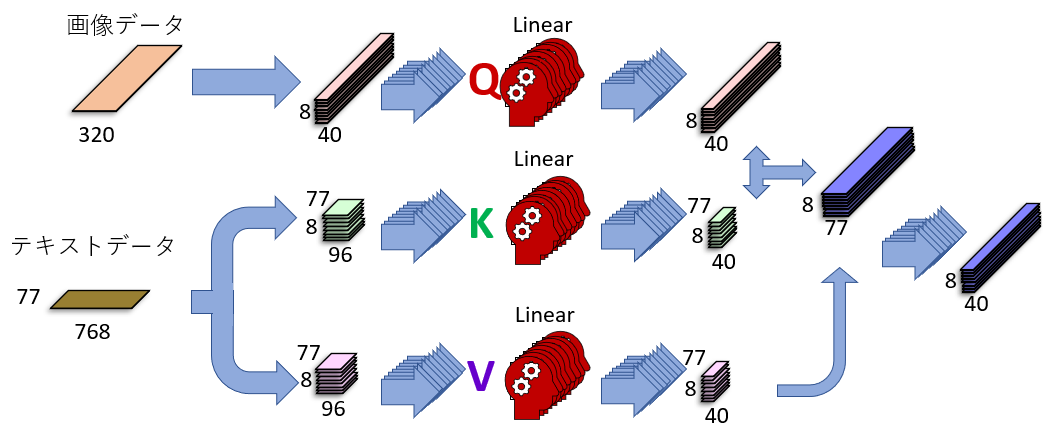
上の図を見てください。KとVがテキストデータから来ていることが分かります。
以下でSelf Attentionの違いを見ていきましょう。
テキストは75トークンごとに処理
Stable Diffusionではテキスト(プロンプト)の長さに上限はありませんが、処理される時は75トークンごとに切り分けられて、それに開始記号と終端記号が足され、合計77トークンをひとまとめとして処理されます。
プロンプトが短く、例えば3トークンしかない場合も、余白のトークンは終端記号で埋め尽くされ、必ず77トークンのデータとして処理されます。
75トークンごとに切り分けられた時、別々のトークングループに入ってしまった単語は関係が完全に切れてしまいます!関係を持たせたい単語はプロンプト内で近くに書きましょう。切り分け場所も意識する必要があるかもしれません。
各トークンは768個の特徴数を持っています。つまり入力されるテキストデータのサイズは77x768です。
上でも書いた通り、このデータを作るのはStable Diffusionではありません。
テキストから数字データへの変換はほかの処理系が行います。
テキストK、Vはサイズが変わる
画像データもテキストデータもマルチヘッド化で8つに切り分けられます。画像データは4096x320が8個の4096x40に、テキストデータは77x768が8個の77x96に分割されます。
その後、画像データはQ、テキストデータはKとVに変換されます。
Qに変換された画像データはサイズが変わりませんが、KとVの場合、変換前のテキストデータサイズ77x96がニューラルネットワークによる変換後には77x40に縮小されています。
なぜこんなことをするのかというと、画像由来のQとサイズを合わせるためです。
比較するためには(行列計算の性質上)特徴数を同じにする必要があるので、テキストデータの特徴数を96から40に圧縮しています。
画像のQとテキストのKを比較する
画像とテキストで特徴数が一致したので、比較することができます。
画像は4096マス、テキストは77トークンなので、比較マップは4096x77になります。
この比較マップが「それぞれのトークンが画像の各マスとどれほど深い関係を持っているか」を表しています。
Self Attentionと同じように、Cross Attentionでも比較マップを正規化します。正規化後の比較マップはVを重み付けする役割を担っています。
出力データは入力データとサイズが同じ
比較マップとVを掛け合わせ、重み付けされたVを足し込んで出力します。
ここでのVはテキスト由来です。テキストのVのサイズは77x40なので、比較マップ4096x77と掛けると出てくるデータのサイズは4096x40になります。これは入力データのサイズと全く同じです。
最後に8つのヘッダをくっつけて、4096x320にします。
これでCross Attention処理は終了です。出てきたものは「混ざり合ったV」です。
テキスト由来のデータが画像に埋め込まれる
ここでも「Vこそが新しいデータの本体」ですが、注目すべきは「Vがテキスト由来」という点です。
つまり画像データがテキストデータに置き換わっているのです!
厳密にはこのあと「処理前の画像データ」が足される(上の「Transformerブロック」セクションにある「Attentionブロック」図の茶色矢印)ので、画像データが完全になくなるわけではありませんが、それでもデータの一部はテキスト由来になります。
この処理でいかにテキストが画像に影響を及ぼすかお分かりいただけると思います。
まとめ
少し長くなりましたが、Attentionについて詳しく見ました。
Attentionを行うためのメカニズムが「Transformer」とよばれるアーキテクチャです。Stable Diffusionではこのうちのデコーダー部分を使って画像を処理しています。
デコーダーでは「Self Attention」と「Cross Attention」の二つの処理を行いますが、Self Attentionは画像のマス同士、Cross Attentionでは画像のマスとテキストをそれぞれ比較し、関係の深いデータをより重視して新たなデータを作り出します。
とくにCross Attentionでは画像データがテキスト由来のデータに置き換わるので、ここで画像にテキストを反映させています。
誰でもわかるStable Diffusion その7:U-Net(テキストを画像に反映するAttentionブロック)
今回はStable Diffusionがどうやってテキストを画像に反映させているのかを見ていきます。
重要な役割を担うのは「Attention」です。これには「Transformer」というメカニズムが使われていますが、これは少し複雑なので今回は詳細は省いて、大まかに何をしているかだけを説明します。
Attentionブロック:テキストを画像に反映
Stable Diffusionの心臓部、U-Netの構造を再び見てみましょう。
ところどころにオレンジの部分があります。これが「テキストを画像に取り込む」ブロック、「Attentionブロック」です。
Attentionブロックこそが人間とAIのコミュニケーションを担う場所です。
このAttentionブロックがないと、Stable Diffusionにどんな絵を描きたいかを伝えることができません。
指示がないと、Stable Diffusionは知っている絵をランダムに適当に描きます。それでは使い物になりませんね。
ここでいう「描く」とは、「ノイズ画像からノイズを取り除いて知っている絵に近づける」作業のことです。これはResブロックが行います。

Attentionブロックはすべてのブロックにあるわけではありません。
テキスト情報を取り込むブロックは、
IN1、IN2、IN4、IN5、IN7、IN8
MID
OUT3、OUT4、OUT5、OUT6、OUT7、OUT8、OUT9、OUT10、OUT11
の計16ブロックです。
特に後半(OUTブロック)に何度もテキストを反映させて、画像をテキスト通りに描かせようとしている様子がうかがえます。
Attentionブロックの概要
まずはAttentionブロックが何をしているのかを大まかに把握します。

入力準備だの出力準備だの後処理だのは単なる「データ変換」で、これは本質ではありません。
このブロックで重要なのは「比較」処理です。「Attention」と呼ばれます。
Attentionとは
比較処理は2回行われます。
- 画像内のそれぞれのマスが他のマスとどう関係しているか
- 画像内のそれぞれのマスが与えられたテキスト(トークン)とどう関係しているか
前者を「Self Attention」、後者を「Cross Attention」と呼びます。
Attentionとは「注意を向ける」という意味です。「Self」は「自分自身」、「Cross」は「自分以外」との比較を表します。
もちろんやっているのは比較だけではありません。比較した結果、より関係が深いと思われるデータを自分に取り込んでいきます。
例えば、あるマスが「black」というテキスト(トークン)に深く関係していると判断された場合、そのマスのデータに「black」由来のデータを多く取り込みます。
こうして元のデータが「関係の深い情報を取り込んだデータ」に変換されます*1。
茶色の矢印は、「データを足す」ことを表しています。つまり、データに何か処理を行った後は、必ず処理を行う前のデータを足します。これはAttentionによって変換されてしまった前の情報も忘れないためです。「ちゃんと賢くなる」ための工夫でもあります。
Attentionブロックの構造
Attentionブロックが何をしているのか大まかに分かったので、中身を少し詳しく見ていきます。
Self AttentionとCross Attentionについては上で概要を説明したのでここでは省きます。
Normalization:正規化
まずあちこちで見られる「Norm」について。
Normはデータの正規化を行う処理です。数字を足したり掛けたりするとどんどん数が大きくなって制御しにくくなるので、正規化によって常に制御範囲内に収めるようにしています。
ここではGroup NormとLayer Normの2種類が使われています。
Group Norm:グループごとに正規化
ブロック最初に現れる「Group Norm」は、Resブロックでも出てきました。
これは320チャンネル*2を10個のグループに分けて、そのグループ内でそれぞれ正規化する処理です。

Layer Norm:チャンネル内で正規化
Layer Normは文字通り「レイヤー(チャンネル)ごとの正規化」、つまりそれぞれのチャンネル内で正規化を行います。

Linear:データを賢く変換
次に「Linear」というブロックですが、これはただのニューラルネットワークです。
その役割は「データを変換する」ことですが、この「変換」は学習によって賢くなります。
それぞれのブロックの最後にLinearブロックを入れることで、賢く変換されたデータが出力されるようになります。
Conv:1x1の畳み込み
最初と最後のブロックにある「Conv」ブロックは、畳み込みを行っています。
畳み込みについての詳細は過去の記事を参考にしてください。
Resブロックの畳み込みと違って、ここのフィルターの大きさは1x1マスです(Resブロックのフィルターは3x3)。
1x1マスの畳み込みは普通、チャンネルの数を変換する(減らす)のが目的ですが、実際はAttentionブロックで使われるConvでは処理前後でチャンネル数は変わりません。
つまり、320チャンネルのデータを入れると320チャンネルそのままのデータが返ってきます。ただしサイズは変わりませんがデータの中身は変わっています。
本質的にはConvもLinearの一種です。
GeGLu:非線形要素を追加
最後にGeGLuですが、これは非線形変換です。「非線形」というのはLinear変換に加えるスパイスのようなもので、これがあると変換が複雑になる、というくらいの理解で構いません。
画像のような複雑なデータを扱うので、複雑な変換ができる機能を追加しています。
GeGLuとはGELUの一種です。

GELUは「マイナスの値を受け取ったらはほぼ0を返し、プラスの値はほぼそのままを返す」関数です。
GeGLuでは、まず入力データが2つに複製されます。
- 片方はGELUに通しますが、その前にLinear処理を行います。つまりニューラルネットに通します。
- もう片方にも別のLinear処理を行いますが、こちらはGELUを通りません。
最後に、GELUに通したデータと通さなかったデータを重ね、重なった所を掛け合わせます。

複雑に見えますが、やっていることはただの非線形化です。
まとめ
Attentionブロックは、ユーザーが入力したテキストを画像に反映させる仕組みです。これがないとStable Diffusionは好き勝手に絵を描いてしまいます。
AttentionブロックはU-Netに複数個あり、画像生成途中でテキストが何度も反映されていることが分かります。
重要なのは画像のマス同士の関係を比較する「Self Attention」、画像のマスと与えられたテキスト(トークン)を比較する「Cross Attention」です。これらが画像に情報を取り込み、テキストを反映させていきます。
Attentionを行うメカニズムである「Transformer」についてはまた別記事で。
誰でもわかるStable Diffusion その6:U-Net(IN1、Resブロック)
Stable DiffusionのU-Net解説の3回目です。
今回はIN1ブロックの中にある「Resブロック」を詳しく見ます。
- IN1ブロックの構造
- Resブロックの構造
- Group Norm:グループごとに正規化
- SiLU:非線形な要素を加える
- Conv:絵の特徴を抽出
- Time Embed:ノイズの量を知らせるスケジュール係
- 処理後に元データを足す:「Res」という名前の由来
- まとめ
IN1ブロックの構造
上のU-Netの図の左上にあるIN1ブロックは「Resブロック」(青色)と「Attentionブロック」(オレンジ色)の2つのブロックからできています。
Resブロックは、入力された画像が持っている特徴を探し出す処理を行います。また、画像に混ざっているノイズ量の情報を画像に追加します。
(Attentionブロックは次回見ます。)
Resブロックの構造
Resブロックが行っている処理は以下の図の通りです。

「Group Norm」→「SiLU」→「Conv」という処理を2回やっていることに気付かれるでしょう。この2回の処理の間に「Time Embed」という処理を行っています。
ちなみに「Dropout」という処理が2回目のConv前に置かれていますが、実際のStable Diffusionではこの処理はスキップされている(通る前と後でデータの中身が変わらない)ので無視してもかまいません。
Group Norm:グループごとに正規化
まずデータに対して「Group Normalization」という処理を行います。
(データというのは、前のブロックから出てきた画像データです。例えばIN1のResブロックの場合、IN0の結果をデータとして受け取ります)
入力データは320のチャンネル(特徴)を持っています。まず、この特徴チャンネルを32チャンネルずつ10個のグループに分けます。
このグループごとに数字を正規化します。グループ内の平均と分散の値にもとづいて正規化します。たとえて言うならグループ内の偏差値を計算するようなものです。
あるマスの値がグループ内の平均値と全く同じなら、正規化後の値は0になります*1。
この処理の意味は、おもに計算の効率化のためです。
ちなみに、この処理も「学習によって賢くなる」パーツです。
SiLU:非線形な要素を加える
次に、「活性化関数」と呼ばれるものにデータを通します。Stable Diffusionでは「SiLU」という名前の関数を使います。

この関数に通すと、マイナスの数値は「ほとんど0」になります。プラスの数値は「だいたい同じ」数値が出てきます。やっているのはこれだけです。
なぜこんなことをするのかというと、Resブロックが「非線形関数」であってほしいからです。
「線形関数」だと複雑な処理ができない、というくらいの理解でかまいません。
何億枚という絵を記憶するには単純な関数だと役不足なのです。
Conv:絵の特徴を抽出
最後に「畳み込み」処理(Convolution)を行って、画像が持つ特徴を抽出します。これは前回の記事で説明しました。
このブロックでやっているConv処理を図で表すと下のような感じです。

IN0で行ったConv処理は特徴チャンネルが4から320に増えました。
しかしここでは、入力データも出力データも特徴チャンネルは320個で、Conv前後でデータの形は全く変わりません。
では、何もやっていないのかというと、もちろんそんなことはありません。
上の図のフィルターを見てください。マス数は3x3ですが、チャンネル数が320になっています。この3x3x320というフィルターを使って畳み込みをすると、出力として新たに1チャンネル分のデータが出てきます。
こうしたフィルターが320個あるので、新たな320チャンネルのデータが作られるわけです。
このフィルターは何をしているのでしょう?
あるフィルターをデータに重ねてみましょう。フィルターは重ねたエリアにある320個の特徴をそれぞれ見ます。例えばそのエリアで「タテ棒」チャンネルと「ヨコ棒」チャンネルが大きな数値を持っているなら、きっとそのエリアはより複雑な「十字」という特徴を持っているでしょう*2。そうやって単純な特徴からより複雑な特徴を見つけ出すことができます。
一般的に、Conv処理を重ねれば重ねるほど、より複雑な特徴を検出するようになります。
Time Embed:ノイズの量を知らせるスケジュール係
畳み込みが終わったら、今の状態の画像にどれだけノイズが混ざっているか、という情報を画像に追加します。
画像データは完全なノイズ画像から始まって、これを何度もU-Netに通すことで徐々にノイズが取り除かれて絵になっていきますが、U-Netというのは1つしか存在しません。ノイズがたくさん乗っているときも、ほとんど取り除かれているときも、同じU-Netを使います。
そのため、「画像にどれくらいノイズが乗っているか」という情報がないと、U-Netがどれだけノイズを取り除いていいのか分からなくなってしまいます。
そこで、Time Embed処理で「今、絵がどれくらいの段階にいるか」という「時間情報」を絵のデータに追加します。
この情報を画像に持たせることで、「どれくらいの量のノイズを取り除いたらいいか」という情報をこの後のブロックに伝えることができます。

時間情報は1280個の数字からなるベクトルです。このベクトルをどうやって作るかの説明は省きますが、このベクトルによって今の画像がどの段階にいるのかを知ることができます。
さて、このベクトルを画像に足したいのですが、画像は320チャンネル(つまり数字が320個)なので1280個と合いません。そこで、このベクトルをSiLU+Linearという処理に通して320個に圧縮します。
Linearは学習によって賢くなるパーツです。ここに通すと1280個の数字が320個の数字になって出てきます。
チャンネル数が同じになったので、全部のマス(例えば64x64マス)に対してこのベクトルを足します。
これでデータに「時間情報」が追加されました。
この後、もう一度「Group Norm」「SiLU」「Conv」の処理を行います。
処理後に元データを足す:「Res」という名前の由来
上の「Resブロックの構造」の図をもう一度見てください。
全部の処理をすっ飛ばして、右端に直接つながっている細い矢印があります。これは、「処理し終わったデータに、処理する前のデータを足す」ことを表しています。これこそが「Resブロック」と言われるゆえんです。
ResとはResidual(残りもの)という意味です。
ある処理ブロックがあって、そこにXを入れるとX+dが出てくるとします。つまりその処理ブロックはdの部分を求めていることになります。このdこそがXを取った後の「残り物」です。Resブロックはこれをやっているのです。
これを行う理由はいろいろありますが、一番の理由は「ちゃんと賢くなるため」です。
単純な事ですが、この「足す」という処理はニューラルネット界隈では大発見でした。
まとめ
U-NetのIN1ブロックはさらに細かい2つのブロックからなりますが、そのうちの一つ、「Resブロック」について詳細に見ました。
ここでは正規化、非線形化、畳み込みを2回行い、その間で時間情報を埋め込みます。
これらの処理が終わった後、処理前のデータを足して、次のブロックへと渡します。
次の記事は、IN1の2つ目のコンポーネント「Attentionブロック」について。
誰でもわかるStable diffusion その5:U-Net(IN0ブロックと畳み込み)
Stable Diffusionで使われるU-Netの最初のブロック、IN0層についての説明です。
IN0ブロックのやっていること
IN0ブロックは、最初に画像を受け取るブロックです*1。
画像は圧縮され、タテヨコがそれぞれ8分の1の大きさになっています。例えば512x512ピクセルの画像を描きたい場合、IN0ブロックには64x64のデータが入力されます。768x512ピクセルの時は96x64のデータが入力されます。
受け取って最初に行う処理が「畳み込み」(Convolution)です。畳み込みとは、簡単に言えば「特徴をサーチする処理」です。IN0ブロックはこの畳み込みを一回だけやって、処理後のデータを次のブロック(IN1ブロック)に送ります。
畳み込み処理とは
ここで使われる畳み込みを絵で表したのが下の図です。
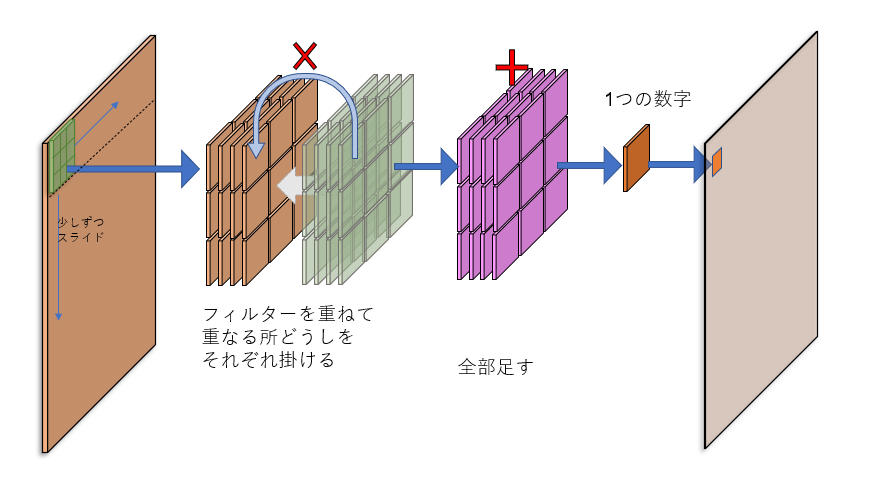
左の茶色い板はU-Netに入力した画像を表しています。板に厚みがあるのは、この画像が4つの「チャンネル」を持っているからです(本来画像はR、G、Bの3つのチャンネルを持っていますが、Stable Diffusionが画像を圧縮して処理する都合で、チャンネルが4つになっています)。
さて、畳み込みはこの画像の持つ特徴をサーチしますが、サーチするうえで重要になるのが「フィルター」の存在です(カーネルと言われたりもします)。図の緑色のパネルがフィルターで、大きさは3x3マス、厚さは4チャンネル(つまり入力画像と同じ厚さ)です。フィルターの厚さは必ず入力画像と同じでなければなりません。
このフィルターを、画像に重ねます。画像左上の3x3マスを見てみましょう。それぞれのマスはひとつの数字を持っています(デジタルデータはいつもそうです)。フィルターをそこにピッタリ重ねたら、重なったマスの数字どうしを掛けます(上の図の左から2番目)。
数字を掛けたら(上の図の紫のパネル)、これらのマスの数字を全部足します。そうすると、最終的には1つの数字が出てきます。
この数字こそが「その部分がどれだけフィルターに似ているか」を表す数字です。フィルターを重ねた画像部分がフィルターに似ていれば似ているほど数字は大きくなります。「似ている」というのは、つまり「フィルターの特徴をその部分が持っている」ということです。
このフィルターは画像の上を少しずつスライドし、左上から右下まで画像をくまなくスキャンします。それぞれ出てきた数字を並べていくと、スキャンした画像と同じ大きさの「特徴マップ」が完成します。
フィルターは「特徴発見機」で、畳み込みは「特徴サーチ」なのです。
畳み込みの具体例
まだ分かりにくいかもしれないので、例を挙げます。
ここでの例では、圧縮していない画像を入力に使います。シンプルにするためにチャンネルの数は1つにします。
「タテ線発見機」というフィルターを使ってみましょう。3x3マスの真ん中にタテ線が1本走っています。つまり、真ん中のタテ3マスが「1」で、あとのマスは「0」です。

さて、入力画像の中にタテ線があるとします(上の図の茶色のパネル)。ここにタテ線発見機フィルターを重ねて畳み込み(重なった所をかけて、全部足す)をすると「3」という数字が出てきます。重ねた部分がタテ線発見機に似ていたので、大きい数字が出てきました。つまり、「タテ線を発見した」のです。
では、斜め線があるところにこのタテ線発見機フィルターを重ねると…

最終的には「1」という数字が出てきます。ど真ん中のマスしか重ならないので、小さい数字になります。この斜め線を発見するには、「斜め線発見機」フィルターを新たに作らなければなりません。
IN0ブロックは320個の特徴発見機
IN0ブロックは、フィルターを320個持っています。つまり、320個の特徴を発見できます。
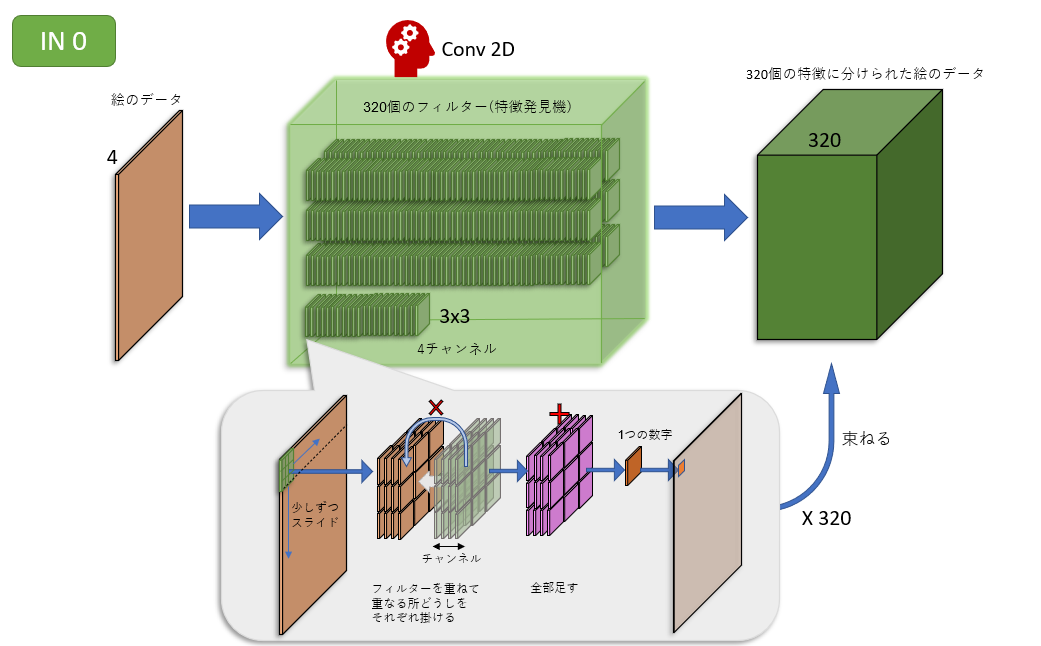
入力したときは4チャンネルだった画像が、出てくるときには320チャンネルに増えています。ちなみにタテヨコのサイズは変わりません。
つまり、チャンネルとは特徴のことです。タテ線に特化したチャンネルもあれば、ヨコ線に特化したチャンネルもあるでしょう。その他いろいろな特徴が320個、IN0ブロックからまとめて出てきます。
「そんなたくさんの特徴って、具体的に何?」と思われるでしょう。それは分かりません。人間が特徴を具体的に指定するのではなく、ニューラルネットワークが学習を通して320個の特徴発見機を改良していくからです。
上の図の中にある「歯車のついた頭のアイコン」は、そこが「学習を通して賢くなる」事を表しています。最初は全然絵の特徴をつかめないかもしれませんが、何度も学習を重ねるうちに、うまく絵の特徴を捉えられるようになります。
Stable Diffusion用に公開されている「モデル」と言われているものは、学習後のフィルターの情報を含んでいます。フィルターの種類が変われば発見できる特徴の種類も変わり、結果的に描かれる絵の特徴も変わります。
まとめ
IN0ブロックはU-Netの最初の処理を行う場所です。ここでは畳み込みが行われ、画像から320個の特徴が抽出されます。
ここで抽出されたデータは次のブロックへ送られ、さらに多くの特徴が抽出されていきます。
U-Net内では畳み込みが何度も行われますが、しくみは基本的に同じなので、ここで畳み込みを理解しておけばU-Netの理解が楽になると思います。
*1:実際のStable DiffusionはLatent Spaceという画像圧縮を使うので、厳密には画像データではありませんが。
誰でもわかるStable Diffusion その4:U-Net
前の記事で、Stable Diffusionには「U-Net」と呼ばれる仕組みが使われると説明しました。
今回はそのU-Netについての概要です。
U-Netの構造
「U」という名前の由来はその構造の形からです。まるでUの字に見えるから(下の図はゆがんだUですが)U-Netと名付けられました。
U-Net自体はStable Diffusionの発表よりも前からありましたが、Stable DiffusionがU-Netを改造して独自に実装しました。
下の図はStable Diffusionで使われているU-Netの構造です。
とてもユニークな形をしています。
画像を左上から入れると、右に向かって次々と画像が処理されて、右上から結果が出てくる仕組みです。
色のついた四角いブロックがそれぞれ何かの処理をすると考えてください。処理が終わったら隣にあるブロックにバケツリレーのようにデータを渡します。
(ピンク線のように途中をすっとばしてデータを渡すこともあります)。
ブロックの中の数字は「画像の持つ特徴の数*1」を表しています。
図を見てみると
大まかにINパート、MIDパート、OUTパートに分かれています。
INパート
INパートはIN0からIN11まで12のブロックに分けられます。
ここでは画像をどんどん小さくしていって、画像が持ついろいろな特徴を取り出していきます。また、与えられたテキスト(プロンプト)を画像に反映させる処理(後述)も行います。
MIDパート
MIDパートはひとつのブロックです。
ここでは画像が最小(最初の画像に比べて8分の1)になります。
OUTパート
OUTパートはOUT0からOUT11まで12のブロックに分けられます。
ここでは画像をどんどん大きくしていって、最初の画像のサイズまで戻します。INパートやMIDパートで取り出してきた画像の特徴をもとに、OUTパートで画像サイズを戻しながら特徴をまとめていきますが、面白いのが「INパートで見つけた特徴を直接使う」という点です。INパートから特徴情報を直接受け取って使う機能があり、「スキップコネクション」と呼ばれます。
OUTパートから出てきた画像が、最終的に欲しい画像です。
スキップコネクション:データを遠くに渡す
図のピンク色の線のように、ブロックごとの処理に加えてINパートからOUTパートへとデータがダイレクトに渡されています。なぜこんなことをするのでしょう?
隣のブロックからバケツリレーのように渡されてきたデータにも画像のデータは入っているのですが、そのデータの内容はブロックを通るごとにどんどん内容が変わっているので、まるで「伝言ゲーム」のように最初に取り出した特徴情報が分からなくなってしまいます。そこで、その情報を「カンニング」するのです。
実際に伝言ゲームを例にとってみましょう。
10人の人が一列に並びます。この人たちが隣にいる人に聞いたことをそのままコッソリ伝えます。

誰もが知っていると思いますが、1番目の人が聞いた内容は伝言の途中でどんどん変わってしまい、10番目の人が聞くころには全然違う内容になっています。そこで、正確に情報を伝えるために「カンニング」を許すことにします。

U-Netでやっていることもまさにこれと同じ事です。
ちょっと実用的な話
つながっているブロック同士の関係は強くなります。どのブロックがペアになっているかという情報は、LoraやLyCORIS(Locon)といった追加学習の層別適用を行うときに重要になるでしょう。例えばLoraでIN0層を無効にした場合、OUT11層にも追加学習の効果が反映されにくくなります。
Stable Diffusion独自技術:テキスト取り込み
本来のU-Netはテキスト情報を読んだりはしません。Stable Diffusionではこれを改良し、「Transformer」という別の仕組みをくっつけて、テキスト(つまりプロンプト)によって画像処理を操作できるようにしました。
Transformerはテキスト処理が大得意です。が、本来は画像処理用ではありませんでした。これを改良してテキストと画像を比べられるようにしたのが「CLIP」という仕組みです。
Stable DiffusionはこのCLIPを利用し、さらにStable Diffusionに合わせて改良し、U-Netの中に取り込みました。
上の図のオレンジの部分がテキストを取り込んで画像処理を行う部分です。
結局何をしているの?
Stable DiffusionのU-Netがやっていることは、以下のことです
- 画像を受け取って、そこから画像の持っている特徴をたくさん見つける
- 見つけ出した特徴から、その画像に乗っているノイズを予測する
- 予測したノイズの画像を吐き出す
ネコの絵を描きたいとします。
ノイズだらけの画像をU-Netに入れると、U-Netはそのノイズだらけの画像が持つ特徴をたくさん見つけ、「ここはネコっぽいな、ここはネコっぽくないな」と判断します。そして、ネコっぽくないところを「ノイズ」と判断し、ネコっぽくない特徴を集めて「ノイズ画像」を作り、吐き出します。
U-Netから出てきたノイズ情報を元の画像から除去すると、「ネコっぽい特徴」が残り、よりネコの絵に近づきます。これを何回も繰り返すと、最終的にネコの絵になります。
「なぜU-Netは『ネコっぽい特徴』じゃなくて『ネコっぽくない特徴』を吐き出すの?最初から『ネコっぽい特徴』を吐き出せば、それがネコの絵になるじゃないか」と思われるかもしれませんが、確かにその通りです。ただ、U-Netは特定の絵を予測するよりノイズを予測する方が得意なのです。計算量はどちらもほとんど変わりません。
まとめ
Stable Diffusionの心臓部、U-Netの概要を説明しました。
次回は特徴を取り出すしくみ、「畳み込み」を説明する予定。
*1:この数字は「処理前」の特徴数であることに注意してください!!処理後に増えたり減ったりすることがあります