誰でもわかるStable Diffusion その9:U-Net(画像データの縮小、拡大)
Stable Diffusionの心臓部であるU-Net解説の9回目です。
これまでU-Netの重要なパーツであるResブロック、Attentionブロックを見てきました。
すでに解説したこれらのブロックでは処理によって画像データのサイズは変わりませんでした。
しかし、処理によって画像のサイズが変わるブロックもあります。今回はそれらを見ます。
そもそもなぜ縮小するの?
そもそも、画像データのサイズを小さくすることに何の意味があるのでしょう?
これには「特徴抽出」が大きく関係しています。
以前の記事で、「U-Netは特徴発見機を使って画像データをスキャンして、画像内の特徴を取り出していく」という解説をしました。
この特徴発見機、別名「フィルター」は3x3マスの大きさで固定です。
さて、仮に画像データサイズが64x64マスとすると、3x3マスの特徴発見機が発見できるものは何でしょう?*1おそらく画像内の細かな特徴、例えばネコの画像であれば毛の質感、目の特徴、鼻の形などでしょう。
しかし、この大きさのフィルターでは「ネコの顔つき」「ネコの取っているポーズ」や「背景のレイアウト」など、画像が持つ大きな特徴をとらえることができません。そこで、画像を小さくします*2。
画像サイズを半分、32x32にすると、同じ3x3のフィルタでも少し広範囲の特徴をとらえられるようになります。ネコの顔全体くらいはカバーできるようになるかもしれません。
さらに半分、16x16にすると、ネコの体全体もカバーできるかもしれません。8x8であれば背景とネコの位置関係までカバーできるかもしれません。
このように、U-Netでは、まず画像の持つ細かい部分の特徴から抽出していき、画像を小さくすることによって画像の持つ大まかな特徴も抽出していきます。
しかし最終的には元と同じ大きさの画像データが欲しいので、画像を再び拡大していき元の大きさに戻します。
(この時、取り出してきた大小さまざまの特徴を使って画像を再構成していきます。)
拡大、縮小はU-Netによって行われます。具体的にどこで行われるか見てみましょう。
U-Netで縮小、拡大
U-Netは大まかに「INブロック」「MIDブロック」「OUTブロック」の3つからできています。下の図を見てください。

- 左側の緑色のラベルが付いたブロックたちが「INブロック」
- 一番下の黄色のラベルが付いたブロックたち(3つの四角)が「MIDブロック」
- 右側の赤色のラベルが付いたブロックたちが「OUTブロック」
この図の上下位置は「画像データサイズの大きさ」を表しています。下に行くほどサイズが小さくなっています。
図を見て分かる通り、最初は処理ごとにどんどん下に下がっていき、MIDブロックを境にまたどんどん上に上がっていきます。
(この形が「Uの字」に似ているので「U-Net」と呼ばれます)
つまり、INブロックでは画像がどんどん小さくなり、OUTブロックで画像がどんどん大きくなり、元の大きさに戻ります。
INで画像縮小
さて、どれだけ画像が小さくなるかというと、図の中の「Down」と書かれたブロックを通るごとにタテヨコのサイズがそれぞれ半分になります(データ数が4分の1になります)。
「Down」ブロックはIN3、IN6、IN9の3つです。つまり3回縮小されます。
IN3では元のサイズの2分の1に、IN6では元のサイズの4分の1に、IN9では元のサイズの8分の1になり、MIDブロックにたどり着くころには画像サイズは8分の1になっています。

上の図は、画像データが16x16の時の例です。
IN3ブロックを通ると画像サイズが8x8になり、IN6ブロックでは4x4、IN9を通ると2x2になり、最終的には元の画像データの8分の1の大きさになっていることが分かります。
OUTで画像拡大
OUTブロックでは、画像が3回拡大され、最終的にサイズが元に戻ります。
画像拡大を行うブロックはOUT2、OUT5、OUT8の3つです。
INブロックでの縮小とは逆に、OUTブロックでは1回拡大されるごとに画像データサイズが2倍になります。3回拡大されるので、最終的に画像サイズが最小時に比べて8倍、つまり元の画像データのサイズになります。
さて、どうやって画像を縮小、拡大しているのでしょう?
画像の縮小、拡大は「畳み込み」
縮小は「畳み込み」を使って行われます。拡大の場合は「補完」によって行われますが、補完処理のあとに畳み込みも行われます。
畳み込みについては、以前の解説記事をご覧ください。
INの縮小処理はDownブロックの畳み込み
上のU-Netの図の「Down」と書かれたブロックは、畳み込みを1回だけやっています。
畳み込みによって画像が縮小する仕組みは簡単です。

畳み込みは、画像データにフィルターを重ねて、重なった部分から新たに1つの数字を取り出す処理です。以前の解説記事に出てきた畳み込みでは、フィルターは画像データ上を1マスずつずらしていました。1マスずつずらした場合、元の画像データと畳み込み後の画像データのサイズは同じになります*3。
このずらし(ストライドと言います)を2マスにすると、フィルターは画像データを毎回1マス分スキップしながらスキャンすることになります。つまり、画像データのサイズが半分になるのです。
このストライドの数によって畳み込み後のデータサイズが決まります。ちなみにフィルターのサイズは関係ありません。2x2でも3x3でもストライドが2であればサイズは半分になります。
OUTの拡大処理は補完と畳み込み
INに「Down」というブロックがあるので、OUTに「Up」というブロックがあってもよさそうなものですが、拡大のときは単独では行われません。ResブロックやAttentionブロックに引き続いて行われるので、それらのブロックと同じところ(OUT2、OUT5、OUT8)に所属しているという扱いです*4。
上のU-Netの図のOUT2、OUT5、OUT8を見てもらえばわかるとおり、まずResブロックやAttentionブロックで処理が行われ、拡大はそれらの処理の後に行われます。
拡大処理ですが、畳み込みを使って画像データ拡大する方法もありますが、Stable DiffusionのU-Netではもう少し単純な方法で拡大を行っています。
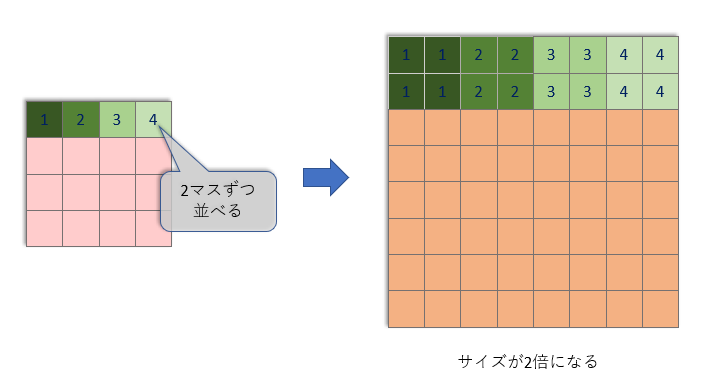
単純に、1マスごとに同じものをタテヨコに2つ並べるだけです。「補完」といいます。
これでサイズは2倍になりますが、これだけではありません。
Stable Diffusionはこの後にサイズが変わらない畳み込みも1回行っています。
ここで畳み込みをする理由は、「この畳み込みが学習によって賢くなるから」です。単純に同じデータを2個並べるだけより賢く拡大できます。
さらに、畳み込みは特徴情報をまとめる役割も果たすので、拡大の時に画像データに特徴情報を反映させることもできます。
縮小の時とは違って畳み込みによって画像サイズを変えているわけではありませんが、ここでも畳み込みは重要な役割を果たしています。
まとめ
U-Netは画像データを縮小しながら細かい特徴から大まかな特徴までたくさんの特徴を抽出していきます。これら抽出した特徴情報をもとに、画像データを再拡大しながら出力データを作り上げていきます。
INブロックでは縮小処理が畳み込みによって行われます。OUTブロックでは拡大処理が補完と畳み込みによって行われます。
これでU-Netで行われている処理はだいたい見終わりました。
次回はIN、MID、OUTのそれぞれのブロックの処理をまとめます。
*1:ここでは分かりやすさのために画像データを「ピクセルデータ」として説明しています
*2:画像を縮小するのでなくフィルターを大きくすればいいのでは、と思われるかもしれませんが、そうすると計算量が増えてしまい効率的ではありません
*3:画像の端っこの処理には注意する必要があります。フィルターが画像からはみ出ている場合、はみ出た部分をどうするかを決めておかなければなりません。
*4:別に拡大処理を単独ブロックとみなしてもかまわないのですが、Stable Diffusionの実装を見ると単独ブロックにはなっていないので、ここではResやAttentionブロックに付随しているという扱いにしています